Java爬虫爬取百度贴吧图片
大家可能都会用python试着写过,原理都差不多,所以在这里我简单说一下用Java如何实现
首先呢!我们应该干啥应该知道我们要去访问那个页面,然后去那个页面去另存为图片对,爬虫就是这样,模拟人的行为批量化的访问URL并获取响应数据。
1.那么这次我们要去访问的页面呢就是这个桌面吧壁纸。
2.打开页面以后呢,我们可以看到有很多的图片,但是我们不是全都要,我们只要里面的大的那种图片,(你打开之后就懂我的意思)。
3.然后呢,我们就选中这个图片,右键,然后另存为。
如果们只要一张的话,完全没有必要去写个代码,但是如果是很多呢?(重复以上步骤,当然可以,如果你不嫌麻烦的话)
所以我们就可以使用网络爬虫来实现,计算机CPU执行的速度当然是比你的手速快了。
爬虫实现
在说代码之前我先说一些等下要用到的一些东西。
1.URL
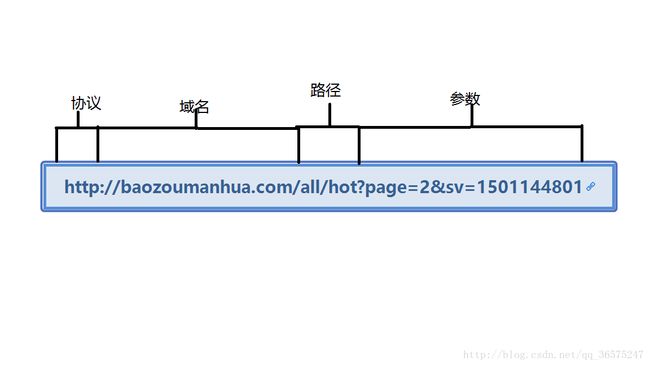
统一资源定位符(URL)是资源标识符最常见的形式。URL描述了一台服务器上某资源的特定位置。他们可以说明如何从一个精确、固定的位置获取资源。
大部分URL都遵循一种标准格式,这种格式包含三个部分。
1.URL的第一部分通常被称为方案(scheme),说明了访问资源所使用的协议类型。这个部分通常就是HTTP协议(http://)
2.第二部分通常是服务器的因特网地址(www.baidu.com)。
3.其余部分指定了Web服务器上的某个资源。
得到网页的源码
1.和我说的一样,先知道自己访问的页面,也就是上面那个,然后我们要做的就是把网页的源码全部拿下来,因为在网页的源码里存在着关于这个图片的URL,你的网络爬虫也就是根据这个找你的图片的位置的。
private static String getHtml(String url) throws IOException {
System.out.println("Getting Url..........");
URL url1 = new URL(url);
URLConnection connection = url1.openConnection();
InputStream in = connection.getInputStream();
InputStreamReader isr = new InputStreamReader(in);
BufferedReader br = new BufferedReader(isr);
String line;
StringBuffer sb = new StringBuffer();
while ((line = br.readLine()) != null) {
sb.append(line, 0, line.length());
}
br.close();
isr.close();
in.close();
return sb.toString();
}
这个方法需要把上边那个链接传进去,返回值将返回一个Sritng来保存网页源码,你可以打印出来看一下。如果是空的话,就是你写错了。
得到图片的URL
然后呢就是去找这个图片的URL,你可能不知道找什么?图片的URL一般是img标签,或者说一个简单的方法,你打开这个网页,然后检查元素,用你的鼠标点一下你要的东西,这样你就会发现你旁边的那个框框里有一段代码高亮,你要找的就是这个。
那么从一个字符串里找到另一个字符串,我们该怎么办呢?大家肯定首先想到的是正则表达式,对没错我也是这样写的。
1.先拿到图片标签下的所有东西,我先说一下问我为什么这么做,是因为我看到那个img标签下的都一样我不能全拿了把,所以我就先把I那些我要的img拿下来,然后再把URL解析出来,这里我写了两个方法,当然你可以用一个来实现。
private static List<String> getImageUrl(String html) {
Matcher matcher = Pattern.compile("[^) ]*?>").matcher(html);
List<String> listimgurl = new ArrayList<String>();
while (matcher.find()) {
listimgurl.add(matcher.group());
}
return listimgurl;
}
private static List<String> getImageSrc(List<String> listimageurl) {
List<String> listImageSrc = new ArrayList<String>();
for (String image : listimageurl) {
Matcher matcher = Pattern.compile("[a-zA-z]+://[^\\s]*").matcher(image);
while (matcher.find()) {
listImageSrc.add(matcher.group().substring(0, matcher.group().length() - 1));
}
}
return listImageSrc;
}
}
]*?>").matcher(html);
List<String> listimgurl = new ArrayList<String>();
while (matcher.find()) {
listimgurl.add(matcher.group());
}
return listimgurl;
}
private static List<String> getImageSrc(List<String> listimageurl) {
List<String> listImageSrc = new ArrayList<String>();
for (String image : listimageurl) {
Matcher matcher = Pattern.compile("[a-zA-z]+://[^\\s]*").matcher(image);
while (matcher.find()) {
listImageSrc.add(matcher.group().substring(0, matcher.group().length() - 1));
}
}
return listImageSrc;
}
}
当然还有一种方法是你用String的方法也可以,你可以找到以“private static void downLoadImg(List<String> imgUrl) throws IOException {
for (String s : imgUrl) {
System.out.println("Downloading " + s);
HttpURLConnection connection = null;
FileOutputStream image = null;
try {
connection = (HttpURLConnection)
new URL(s).openConnection();
i++;
InputStream in = connection.getInputStream();
image = new FileOutputStream("d:\\img\\" + i + ".jpg");
while (true) {
byte[] buf = new byte[1024 * 8];
int len = in.read(buf);
if (len == -1) {
break;
}
image.write(buf, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("ok_____________");
}
}
接着我们就该考虑了,上边这些代码就是只处理了,第一页的,那之后的呢?一样的道理,写到循环里,你重复以上步骤就行了,只要每次,给出正确的链接就行。最后一项的参数只有在翻页或者有特殊请求的时候会改变。你只要翻页然后看参数的变化就行,然后把参数拼到连接上就行。
当然,这个代码我们只用到了一个线程,我们完全可以用多个线程来一次爬取多个页面,这样性能会更高。
这里是完整代码链接