DataX环境部署以及测试案例
DATAX简介(简介来自官网加以改编)

DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
Features
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
System Requirements
Linux-没有要求
JDK(1.8以上,推荐1.8)
Python(推荐Python2.6.X)(注意:一定要2.X,不要安装3.X会出错)
Apache Maven 3.x (Compile DataX)
环境部署
JDK环境部署
配置
vi /etc/profile
#JDK1.8
JAVA_HOME=/usr/local/jdk
JRE_HOME=/usr/local/jdk/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASSPATH PATH
刷新环境变量,使之生效。
source /etc/profile
测试
java -version

python2.X环境
linux-centOS自带的就有2.X
测试
python

Maven环境部署
配置
vi /etc/profile
#MAVEN
M3_HOME=/usr/local/apache-maven-3.3.9
export PATH=$M3_HOME/bin:$PATH
刷新环境变量,使之生效。
source /etc/profile
测试
mvn -v

Quick Start
工具部署
方法一、直接下载DataX工具包:DataX下载地址(建议使用)
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
自检脚本: python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
例如:
MY_DATAX_HOME=/usr/local/datax
cd /usr/local/datax
./bin/datax.py ./job/job.json
出现下面情况,表明dataX环境搭建完成。
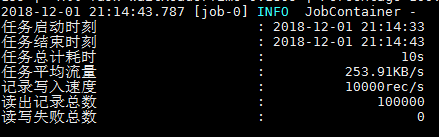
方法二、下载DataX源码,自己编译:DataX源码
(1)、下载DataX源码:
$ git clone [email protected]:alibaba/DataX.git
(2)、通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] -----------------------------------------------------------------
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] -----------------------------------------------------------------
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
配置示例:从stream读取数据并打印到控制台
Support Data Channels
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南

Hive与MySQL交互案例
将MySQL表导入Hive
0.在mysql中造数据
test数据库。
创建test_test_table表
表结构

表数据

1.在Hive中建表(储存为文本文件类型)
hive> create table mysql_table(word string, cnt int) row format delimited fields terminated by ',' STORED AS TEXTFILE;
OK
Time taken: 0.194 seconds
hive> select * from mysql_table limit 10;
OK
Time taken: 0.162 seconds
2.在{YOUR_DATAX_PATH}/job下面,编写mysql2hive.json配置文件
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123",
"column": [
"word",
"cnt"
],
"splitPk": "cnt",
"connection": [
{
"table": [
"test_table"
],
"jdbcUrl": [
"jdbc:mysql://192.168.231.1:3306/test"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://192.168.10.3:9000",
"fileType": "text",
"path": "/user/hive/warehouse/mysql_table",
"fileName": "mysql_table",
"column": [
{
"name": "word",
"type": "string"
},
{
"name": "cnt",
"type": "int"
}
],
"writeMode": "append",
"fieldDelimiter": ",",
"compress":"gzip"
}
}
}
]
}
}
3.运行脚本
cd /usr/local/datax
./bin/datax.py ./job/mysql2hive.json

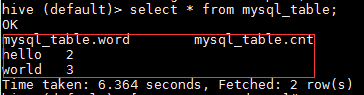
4.查看hive表中是否有数据
select * from mysql_table;
努力努力再努力!!!