基于MySQL和Infobright的数据仓库技术
除非你最近在一个荒岛上,否则你不可能不知道,数据仓库/分析/商务智能( BI )领域正在飞速发展。许多年前,当行业分析师群体调查CIO最优先考虑的事时,BI排第十位 。然而,他于2006年跃升到了第二位,今天,根据Gartner Group分析已经跃居第一位了。这没有什么神秘的原因:在激烈的经济竞争中所有行业和智能企业需要利用其内部的数据来做出重要的商业决策,包括战术和战略两方面,以保持行业的领先地位。
但有个问题:在公司组建主要的BI部门将要花费很大一笔资金。很多数据仓库和BI厂商较好的实现你的AMEX金卡态度,对部分IT负责人造成了一些挫折;事实上,2007年信息周刊调查发现, 39 %的IT经理抱怨说,软件许可费用阻碍他们想要推广BI的倡议。
但是进入开源!正如最近,开放源码已经革新了软件的许多领域,几乎为任何公司创造研发操作系统,开发工具,以及数据库,等具有竞争力的IT环境打开了方便之门,那么现在同样的事情也发生在了数据仓库和商务智能(BI)领域。目睹事实,数据仓库(如对MySQL的一次重大社会和客户调查)目前是MySQL的第五种最常见的应用。
但这里的另一个统计称:根据TDWI ,数据仓库每年的平均增长速度的介于33和50 %之间,然而这一数据对一些企业来说还是相对比较保守的。现在用于MySQL数据仓库最流行的存储引擎是MyISAM (第二个是InnoDB的) ,当数据达到1TB左右是他的性能依然很优越。在此之后,大量的用户往往将数据仓库分布在多个服务器,以提高性能。现在,从分析公司IDC统计资料来看,大多数的数据仓库是6TB下(据IDC称只有4 %超过25TB),因此这意味着大多数人成天都只在管理数百GB和6TB之间的数据仓库。
如果是你,并且你希望有一个基于MySQL的解决方案,那么你应该为亲自去留意一下Infobright存储引擎。 Infobright,MySQL / Sun公司的合作伙伴之一,供应的引擎能突破MyISAM和其他存储引擎限制,并提供了一个非常尖端的技术(令人吃惊... ),当进行安装,设置和数据库设计以获得难以置信的快速的反应时间时,你并不需要繁重的工作。
让我们先来看看在Infobright架构,看看它是如何完成这些事情,然后对他进行测试以了解其是如何更好的执行解析式查询。
列非常酷
概括地说, Infobright存储引擎是一个列导向的架构,结合高速数据装载机,高度的数据压缩和一个灵活的,外部优化器以及'知识网格' ,提供令人印象深刻的数据仓库功能。从MySQL的角度来看, Infobright就像其他任何存储引擎,因此从界面的角度来看没有什么新的东西要理解。 Infobright是一个单独的安装,然而,从总体MySQL服务器,但它安装很简单(我发现实际速度超过一个标准MySQL的安装) ,以及下载也只有17MB,这是一个非常了不起的引擎,可以管理10万亿字节的数据。
首先要说明的是, Infobright引擎是一列导向的设计。列导向的数据库的存在已经有一段时间(如Sybase公司的IQ ) ,但现在才给人以强烈的印象,归功于其能很好的满足数据仓库的需求。2008年3月Infobright研究报告“What’s Cool About Columns”,菲利普霍华德写道, “在过去十年,对于大部分使用列导向的做法是非常合理的。不过...我们相信,现在是列走出阴影,成为数据仓库和相关的市场主要力量的时候。”他接着补充说, “列以较低的成本和更小的封装提供更好的性能:但很难理解,为什么任何公司都对查询性能感兴趣,但从不考虑基于列的解决方案。
为什么要作这样的声明?由于像Infobright这样列导向的设计,在数据仓库环境下真的包含着许多优势。出现这种情况有许多原因,但在这里仅仅是少数几个。大多数数据仓库/解析查询,只关心一个或多个表中的两列,而不是所有的列。在这种情况下,为数据仓库目的,数据以典型的行格式存储是没有效率,而更应该采取列导向的格式存储。在像Infobright这样列导向设计的数据库中,全表扫描将永远不会被执行(除非查询请求一个表中全部或大部分列) ; 可能只需进行全列扫描。最终的结果是更少I / O操作并且提高列导向数据库的响应时间。
Infobright采用列导向的设计并结合任何人都喜欢的其它设计:高强度的数据压缩。因为它是列导向,当Infobright压缩数据,它对每一列这样做,这通常是比标准的行导向的压缩更有效率,因为压缩算法可被每一列数据类型精调。在正常的行导向的压缩中,你最多看到2或3比1的压缩;但采用Infobright ,10比1压缩是最基本的(在某些情况下会高得多) ,所以1TB的数据库可以被压缩到100GB 。当Sun性能组一些成员的看到这种性能,他们对Inforbright压缩数据的能力很吃惊,他的性能比他们以往使用过的任何数据库(行导向和列导向)都要强。当然,数据压缩的结果是,不仅有助于提高性能,同时也有助于降低数据仓据的存储成本,这将受到更多IT经理的青睐。
Infobright的其他技术优势
虽然您可以通过所有标准路线加载数据到MySQL Infobright表, Infobright还提供了一个特殊的高速装载机,他在加载数据到一个数据库时采用了完全不一样的算法。该加载算法是多线程,使每个列能并行载入。采用Infobright企业版,单表加载100GB的数据通常需要一个小时,而多表加载一个小时可以实现300GB左右的二进制数据载入,这不是太寒酸。Infobright社区版已降低载入速度,因为它只能处理文字输入(而不是二进制) ,但你仍然可以看一个小时载入40GB左右数据的速度。
但是,也许在Infobright架构主要的最突出的技术是它的“知识网格”和相应的优化器。 Infobright在数据加载到数据库中(无论初始化或递增)时候就开始建造知识网格。知识网格本质上是数据库中数据和数据统计的一个统计描述。这里关键要记住知识网格:它可以替代索引,这意味着你永远不需要在Infobright表中创建索引。不用创建索引,这是一件好事!
Infobright知识网格没有索引维护的缺点,从所周知,造成数据库插入和更新的响应时间随着时间的推移而增加的原因,是因为对据库越来越多的修改操作。另一个优点Infobright在做非常难以预测的查询服务时,做得非常好,这正是许多数据仓库需要处理的。这种查询是数据库管理员的恶梦,因为他们不能设计一个有效的索引或分割策略,因此数据库性能从来没有到达最大。但随着Infobright 出现,所有这些问题都迎刃而解,因为它能自动完成这些工作。
Infobright的实际数据是按照列存储的。这些列被分为64K的大小,称作数据包,其元数据存储在知识网格。当一个查询提交给Infobright执行时,优化器咨询知识网格,以便产生一个粗略的想法,哪些数据包包含查询结果集所需的数据。当出现以下两种情况( a )有相对较少的数据包中包含结果集的数据;( b )优化工具能够准确地确定一系列所需的数据包,查询速度将异常快速。
考虑数据分布方法类似于自动数据分割。再次,这是一件好事。随着Infobright 出现,得到性能优越的数据仓库,你不必是一个数据仓库的设计专家,因为它几乎为你做了所有困难的工作-没有索引或分割战略,这以前都是你工作的一部分。
在某些情况下,查询根本不需要任何数据包就可以执行;只要咨询过知识网格,像这样的查询将立即执行。由于知识网格包含了许多聚合信息,因为在数据仓库的应用中,聚合是所有查询一个共同的点,对许多数据仓库类型的查询执行来说,很少或根本没有这些必要处理是不寻常的(例子后续下文) 。
Infobright趋向的应用框架是有深的、宽的实际表和低维度表的星型模式(尽管真正的星型设计不需要),并且数据库中表的设计基本上是非格式化的。在包括高度标准化架构的应用和更多的随机数据的分布的使用情况下,Infobright可能无法执行。这是因为这些数据不会以数据集中的模式压缩,并且数据的查询结果集遍布数据库,因此大量的数据包需要被扫描。
如此多的讨论-现在,让我们通过一些标准的数据仓库的使用案例,来练习使用Infobright引擎,并看看他的性能如何。下面所有的测试将在戴尔PowerEdge 6850上进行,它有4个Intel Xeon双核处理器(3.4GHz), 32GB的内存,和5个RAID 10 形式的300GB的内部硬盘,运行在64位的红帽Linux 5企业版和Infobright企业版上。
Kicking the Tires
使用Infobright创建表时,操作与任何其他MySQL引擎是大致相同的-所有你要做的就是指定引擎的类型为brighthouse。例如:
mysql> create table t (c1 int) engine=brighthouse;
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t values (1), (2), (3);
Query OK, 3 rows affected (0.16 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t;
+------+
| c1 |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
所以,现在进入实际测试:我用作下面查询的模型是一个标准的数据仓库星型模型(代表汽车销售数据库) ,可用如下数据模型描述: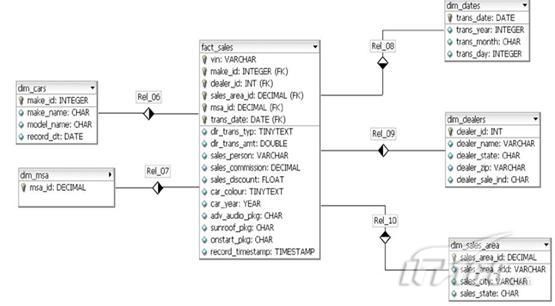
计算行数和数据库的总体规模(如计算INFORMATION_SCHEMA信息)如下:
+----------------------------+-------------+------------+--------------+
| table_name | engine | table_rows | data_length |
+----------------------------+-------------+------------+--------------+
| fact_sales5 | BRIGHTHOUSE | 8080000000 | 135581094511 |
| fact_sales | BRIGHTHOUSE | 1000000000 | 16789624027 |
| fact_sales1b | BRIGHTHOUSE | 1000000000 | 17424704919 |
| mthly_sales_by_dealer_make | BRIGHTHOUSE | 4207788 | 43958330 |
| dim_vins | BRIGHTHOUSE | 2800013 | 15251819 |
| dim_sales_area | BRIGHTHOUSE | 32765 | 302326 |
| dim_dates | BRIGHTHOUSE | 4017 | 9511 |
| dim_dealers | BRIGHTHOUSE | 1000 | 9631 |
| dim_dealers2 | BRIGHTHOUSE | 1000 | 10222 |
| dim_cars | BRIGHTHOUSE | 400 | 4672 |
| dim_msa | BRIGHTHOUSE | 371 | 3527 |
| tt | BRIGHTHOUSE | 1 | 193 |
+----------------------------+-------------+------------+--------------+
12 rows in set (0.00 sec)
+------------------+
| sum(data_length) |
+------------------+
| 169854973688 |
+------------------+
1 row in set (0.01 sec)
上述表明了几个相当大的实表,每个都有10亿行,一个更大的历史实表超过80亿行,一个中型汇总表( 400万行) ,以及一定数量的维数表,其大小是相当小的(除280万行dim_vins表) 。数据库的总物理大小几乎是170GB ,但实际原始数据的大小是1TB,所以你可以看到在Infobright压缩操作中,它做到了它所承诺的。
检查一些行数证明上述数据:
mysql> select count(*) from fact_sales5;
+------------+
| count(*) |
+------------+
| 8080000000 |
+------------+
1 row in set (0.00 sec)
mysql> select count(*) from fact_sales;
+------------+
| count(*) |
+------------+
| 1000000000 |
+------------+
1 row in set (0.00 sec)
请注意, Infobright响应时间就像MyISAM全表做COUNT(*)查询的时间;知识网格知道每个表有多少行,因此你不会浪费时间等待此种查询的答复。
现在,让我们进行几个解析查询,看看我们获得什么。首先,让我们做一个简单操作,看经销商在一个特定的时间内能够销售多少汽车:
mysql> select sum(dlr_trans_amt)
-> from fact_sales a, dim_cars b
-> where a.make_id = b.make_id and
-> b.make_name = 'ACURA' and
-> b.model_name = 'MDX' and
-> trans_date between '2007-01-01' and '2007-01-31';
+--------------------+
| sum(dlr_trans_amt) |
+--------------------+
| 11264027726 |
+--------------------+
1 row in set (24.98 sec)
Not too bad at all. But now let’s put the knowledge grid / data packs to the test and see how big a dent in our response time we get by adding eight times more data to the mix:
这还不算太糟糕。但是,现在让我们把知识网格/数据包进行测试,我们通过曾加八倍以上的数据组合,然后看我们的响应时间受到多大影响。
mysql> select sum(dlr_trans_amt)
-> from fact_sales5 a, dim_cars b
-> where a.make_id = b.make_id and
-> b.make_name = 'ACURA' and
-> b.model_name = 'MDX' and
-> trans_date between '2007-01-01' and '2007-01-31';
+--------------------+
| sum(dlr_trans_amt) |
+--------------------+
| 11264027726 |
+--------------------+
1 row in set (27.20 sec)
非常棒! Infobright能-再次-只审查所需的数据包,并排除所有其他数据,那些他并不需要查找以满足我们的查询,对整体的响应时间并没有真正实际的影响(运行相同的查询但实际上用比第一次查询更小的表) 。
现在,让我们测试,在某些情况下能使普通MySQL服务器瘫痪的查询, -嵌套子查询:
mysql> select avg(dlr_trans_amt)
-> from fact_sales
-> where trans_date between '2007-01-01' and '2007-12-31' and
-> dlr_trans_type = 'SALE' and make_id =
-> (select make_id
-> from dim_cars
-> where make_name = 'ASTON MARTIN' and
-> model_name = 'DB7') and
-> sales_area_id in
-> (select sales_area_id
-> from dim_sales_area
-> where sales_state =
-> (select dealer_state
-> from dim_dealers
-> where dealer_name like 'BHUTANI%'));
+--------------------+
| avg(dlr_trans_amt) |
+--------------------+
| 45531.444471505 |
+--------------------+
1 row in set (50.78 sec)
Infobright plows through the data just fine. What about UNION statements – oftentimes these can cause response issues with MySQL. Let’s try both fact tables this time:
Infobright处理数据是非常的好。关于联合声明-这些操作往往会造成与MySQL响应冲突。那么,这次让我们尝试两种实际表:
mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales
-> where trans_date between '2007-01-01' and '2007-01-31')
-> union all
-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales
-> where trans_date between '2007-02-01' and '2007-02-28');
+--------------------+-----------------------+---------------------+
| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
+--------------------+-----------------------+---------------------+
| 45550.1568209903 | 5.39966 | 349.50289769532 |
| 45549.5774942714 | 5.39976 | 349.498835301098 |
+--------------------+-----------------------+---------------------+
2 rows in set (0.49 sec)
mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales5
-> where trans_date between '2007-01-01' and '2007-01-31')
-> union all
-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales5
-> where trans_date between '2007-02-01' and '2007-02-28');
+--------------------+-----------------------+---------------------+
| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
+--------------------+-----------------------+---------------------+
| 45550.1568209903 | 5.39966 | 349.50289769532 |
| 45549.5774942714 | 5.39976 | 349.498835301098 |
+--------------------+-----------------------+---------------------+
2 rows in set (0.75 sec)
It appears the UNION’s were satisfied via knowledge grid access alone. Next, let’s try a few joins coupled with a having clause and ask for the average Ashton Martin dealer transaction amounts over one year for dealers in the state of Indiana:
看来双方对仅通过知识网格来处理的结果都比较满意。接下来,让我们尝试一些有关条款的加盟,并查询阿什顿马丁经销商过去一年对印第安纳州交易商的平均交易金额,:
mysql> select fact.dealer_id,
-> avg(fact.dlr_trans_amt)
-> from fact_sales fact
-> inner join dim_cars cars on (fact.make_id = cars.make_id)
-> inner join dim_sales_area sales on
-> (fact.sales_area_id = sales.sales_area_id)
-> where fact.trans_date between '2007-01-01' and '2007-12-31' and
-> fact.dlr_trans_type = 'SALE' and
-> cars.make_name = 'ASTON MARTIN' and
-> cars.model_name = 'DB7' and
-> sales.sales_state = 'IN'
-> group by fact.dealer_id
-> having avg(fact.dlr_trans_amt) > 50000
-> order by fact.dealer_id desc;
.
.
.
| 2 | 51739.181818182 |
| 1 | 57964.8 |
+-----------+-------------------------+
317 rows in set (50.66 sec)
当然,还有许多其它的查询,可被测试,但上述将给你Infobright如何执行一些典型的解析式查询的感受。再次,一个伟大的事情是你不必花时间设计索引或制定分割计划,以获得上面展示的性能结果,因为所有这些在Infobright中是完全没有必要的。事实上,引擎只有三个左右的微调参数,并且他们都和内存相关。
Infobright的局限性
此刻,Infobright有某些限制你必须知道。并非所有的查询都能通过Infobright优化器进行优化;有些不能最终被发送到MySQL优化器。如果出现这种情况,在你的查询执行后你会收到警告,指出这样的事情发生。
• 现在,Infobright可处理多达8-10并发用户,但在即将发布的版本中计划增加至30个左右。
•查询目前被限制在一个CPU /核心。
•支持相关子查询,但通常是无法高效率运行。
•DML(插入,更新,删除;仅适用于企业版)只支持表级锁,它可以减少并发性,如果DML发生在一个Infobright仓库。
•从理论上说,一个Infobright表可以上升到147万亿行,但实际上,500亿是现在的上限-计数极大地依赖于数据行的规模和使用的数据类型(即行限制可能会更取决于行规模)
•现在,缺乏国际支持,计划2009年上半年获得UTF8支持。
•现在,没得到Windows或Solaris支持;预计到2009年底将获得。
•没有ALTER TABLE有关的支持。您不能从其他表转换到Infobright ,反之亦然。
•知识网格无法处理非Infobright表,因此,如果你的查询有一个混合存储引擎,涉及Infobright表,那么你的性能将大打折扣。
在两个查询操作中我还触及一个小错误,当我用10亿行的表取代了80亿行的表引时,引起查询性能大幅下降。显然,是已知的排序算法错误,他涉及到源数据,并且只在大表中存在。 Infobright正在试图解决这个问题。
就目前而言,在操作系统和硬件的支持下, Infobright存储引擎运行于32位(社区版)和64位(社区版和企业版)英特尔和AMD处理器以及红帽Linux企业版, CentOS , Fedora(社区版)和Debian以及标准的商品硬件。并且所有主要的BI工具( Business Objects公, Cognos, Pentaho ,JasperSoft等) ,都支持MySQL和Infobright的组合。
结论
随着智能高科技和商业人体会到数据仓库和BI支持的绝对必须性,这将是一个伟大的时间来检验MySQL - Infobright的解决方案。您可以在www.infobright.org下载并尝试社区版的Infobright存储引擎。此外, MySQL的数据仓库的问题的论坛是:http://forums.mysql.com/list.php?32,在MySQL和Infobright网站( Infobright公司的网站是www.infobright.org)有更多的资料和白皮书(包括科技和其他方面)。
所以,请尝试Infobright,并且让我知道你的想法。和以往一样,感谢你对MySQL和Sun公司的支持。