初识数据源同步利器--DataX
一、DataX是什么?
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、
HDFS、Hive、MaxCompute(原ODPS)、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
设计理念:
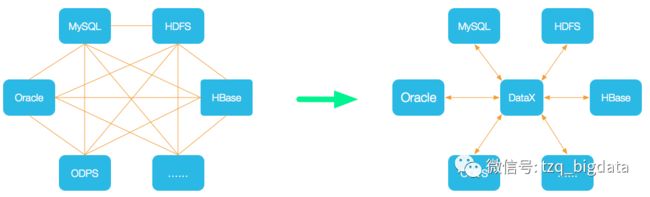
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
dataX本身只是一个数据库同步框架,通过插件体系完成数据同步过程reader插件用于读入,writer插件用于写出,中间的framework可以定义transform插件完成数据转化的需要。
使用它之后,我们的数据同步工作就简化成了:根据数据源选择对应的reader或者writer插件,填写必要的一个配置文件,一句命令搞定全部。
DataX详细介绍:请参考:DataX-Introduction
简言之,DataX是一个单机多任务的ETL工具,支持各种异构数据源之间稳定高效的数据同步功能。
二、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX 3.0六大核心优势:
1.可靠的数据质量监控
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
提供作业全链路的流量、数据量运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
2. 丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
3. 精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
如:
"speed": {"channel": 8, ----并发数限速(根据自己CPU合理控制并发数)"byte": 524288, ----字节流限速(根据自己的磁盘和网络合理控制字节数)"record": 10000 ----记录流限速(根据数据合理空行数)}
4. 强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。
在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。
性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
5. 健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,
在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到 线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
线程内部重试:DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
线程级别重试:目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
6.极简的使用体验
三、DataX支持哪些数据同步?
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
| 类型 |
数据源 |
Reader(读) |
Writer(写) |
文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 |
四、DataX使用示例
1、样例输出:$ python datax.py ../job/job.json
2、hive2mysql json配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{"index":0,"type":"string"},
{"index":1,"type":"long"},
{"index":2,"type":"string"}
],
"defaultFS": "hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode286,namenode36",
"dfs.namenode.rpc-address.nameservice1.namenode286": "zmbd-uat01:8020",
"dfs.namenode.servicerpc-address.nameservice1.namenode286": "zmbd-uat01:8022",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"haveKerberos": "true",
"kerberosKeytabFilePath": "/home/zmbigdata/kerberos/zm_app_prd.keytab",
"kerberosPrincipal":"[email protected]",
"encoding": "UTF-8",
"fileType": "orc",
"path": "/user/hive/warehouse/bi.db/bi_1v1_lesson_ability_data_df/pt=2019-11-25"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["subject_code","ability_id","ability_name"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://xx:3306/test?useUnicode=true&characterEncoding=utf8",
"table": ["bi_1v1_lesson_ability_data"]
}
],
"password": "xxx",
"preSql": [],
"session": [],
"username": "xx",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "2"
},
"errorLimit": {
"record": 0
}
}
}
}遇到问题:kerberos 认证失败
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[HdfsReader-13], Description:[KERBEROS认证失败]. - kerberos认证失败,请确定kerberosKeytabFilePath[/home/xx/zm_app_prd.keytab]和kerberosPrincipal[zm_app_prd/[email protected]]填写正确 - java.io.IOException:
Login failure for zm_app_prd/[email protected] from keytab /home/xxx/zm_app_prd.keytab: javax.security.auth.login.LoginException:
Unable to obtain password from user
Caused by: javax.security.auth.login.LoginException: Unable to obtain password from user解决: user [email protected] using keytab file /home/zmbigdata/kerberos/zm_app_prd.keytab
3、mysql2hive json配置示例如下
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "xx",
"password": "xx",
"column" : [
"id"
,"les_id"
,"grade_id"
,"edition_id"
,"subject_id"
,"course_system_first_id"
,"course_system_second_id"
,"course_system_third_id"
,"course_system_four_id"
,"custom_points"
,"deleted"
,"created_at"
,"tea_id"
,"stu_id"
,"les_uid"
,"updated_at"
,"pt"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://xx:3306/test?useUnicode=true&characterEncoding=utf8"],
"table": ["ods_lesson_course_content_rt_df_tmp"]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id" , "type":"int"},
{"name":"les_id" , "type":"int"},
{"name":"grade_id" , "type":"int"},
{"name":"edition_id", "type":"int"},
{"name":"subject_id", "type":"int"},
{"name":"course_system_first_id" , "type":"int"},
{"name":"course_system_second_id", "type":"int"},
{"name":"course_system_third_id" , "type":"int"},
{"name":"course_system_four_id" , "type":"int"},
{"name":"custom_points", "type":"string"},
{"name":"deleted" ,"type":"TINYINT"},
{"name":"created_at" ,"type":"string"},
{"name":"tea_id" ,"type":"int"},
{"name":"stu_id", "type":"int"},
{"name":"les_uid" ,"type":"string"},
{"name":"updated_at" ,"type":"string"},
{"name":"pt","type":"string"}
],
"defaultFS": "hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode286,namenode36",
"dfs.namenode.rpc-address.nameservice1.namenode286": "zmbd-uat01:8020",
"dfs.namenode.servicerpc-address.nameservice1.namenode286": "zmbd-uat01:8022",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"haveKerberos": "true",
"kerberosKeytabFilePath": "/home/zmbigdata/kerberos/zm_app_prd.keytab",
"kerberosPrincipal":"[email protected]",
"encoding": "UTF-8",
"fileType": "orc",
"fileName": "ods_lesson_course_content_rt_df_orc_2",
"path": "/user/hive/warehouse/ods.db/ods_lesson_course_content_rt_df_orc_2",
"writeMode": "append",
"fieldDelimiter" :","
}
}
}
],
"setting": {
"speed": {
"channel": "5"
},
"errorLimit": {
"record": 10
}
}
}
}
五、DataX性能测试
| 时间 |
测试场景 |
环境(UAT单机) |
数据源 |
目标存储 |
测试对比 |
结论 |
|---|---|---|---|---|---|---|
| 2019年11月28日 | Hive → mysql | osInfo: Oracle Corporation 1.8 25.152-b16
|
Hive | MySQL | 数据量:单表约117万+ hive表格式:ORC 管道数设置:1 任务平均流量:3.38MB/s 耗时:41s
|
初次测试结果: 1、性能狠强 3、写入速度狠可观,实测 39239rec/s
其他:不排除受限于本地执行机器性能影响
|
| 2019年11月29日 | mysql→ hive | osInfo: Oracle Corporation 1.8 25.152-b16 jvmInfo: Linux amd64 3.10.0-957.5.1.el7.x86_64 cpu num: 8 total mem: 15G |
MySQL | Hive | Hive表:ORC (append) ods.ods_lesson_course_content_rt_df_orc_2 未设置split测试: 管道数设置:1 任务平均流量: 6.76MB/s 耗时:21s 管道数设置:10 任务平均流量:6.76MB/s 耗时:21s
|
任务启动时刻 : 2019-11-29 18:00:33 结论:这里管道数的设置变化貌似对抽数未造成影响,可能和数据量有关,目前单表117w+,抽数性能狠强悍! |
当然凡事都有利弊,dataX也不例外,datax本身不支持工作流调度,不支持简洁的配置,感觉写json文件好出错,尤其是列的书写,当列特别多,类型特别多很容易出问题,虽说dataX智能报错提示狠不错,但是我更迫切使用界面化的方式去配置任务,让用户可以通过很简单的方式轻松完成取数,后面也有计划将该方案落实。
六、参考文章
https://github.com/alibaba/DataX
https://blog.csdn.net/shudaqi2010/article/details/79247468
https://blog.csdn.net/u014646662/article/details/82792725