前言:本文介绍一种利用java序列化与反序列化的
基于文件的快速索引.项目中可能会存在这样的需求场景:业务上需要从数万条记录中快速检索出满足条件的某条记录,而这数万条记录是随时变化的,比如抓包工具,时时刻刻接收不同的报文,将这些临时动态数据放入数据库性价比极低,引入Memcached等缓存工具又有杀鸡焉用牛刀的感觉,因此考虑直接将记录存入本地临时文件,采取一定的协议方式加快索引。
本篇文章重点关注以下问题:
- 规定数据存放协议,加快索引
- java利用序列化与反序列化实现对象的读写
- 对象、字节数组、文件之间的转换
- 整合Demo
1. 数据在文件中的存放协议
在面向对象的语言中,将数据以对象的形式保存极为常见,而通过序列化把对象直接保存在文件或数据库中,再反序列化得到对象,中间过程无需自己解析也极为方便,但是因为对象序列化后需要保存类信息,存储空间开销较大,如何建立快速索引,避免不必要的开销则至关重要。
首先规定每条记录的存储格式:索引(4byte) + 记录长度(4byte) + 数据(变长);
- 索引为记录的唯一标识,如若命中索引,则返回数据部分;如若为命中,继续查找下一记录。(索引大小可自定义)
- 记录长度为数据部分所占的存储空间,程序可根据此字段跳过此条记录数据部分的读取。(记录长度的大小可自定义)
- 数据部分存储数据,不同对象可能会占用不同的空间。
算法:
- 写文件:以流的方式写文件,将每条记录以上述协议一条一条写入文件,即可将对象直接序列化至文件,也可先将对象转换成字节数组后保存至文件。
- 读文件:以流的方式读文件,从文件头开始扫描,每条记录只读前8byte(索引+记录长度),如若命中索引,则读取数据部分后直接返回对象;如若未命中记录,则skip(跳过)数据部分,继续下一条数据的比对。
此方式主要是在读数据时避免读取无用数据,毕竟对象序列化后所占的空间较大。
2. java利用序列化与反序列化实现对象的读写
2.1 定义实体类
实体类为需要序列化保存的数据,需要注意的是所有序列化保存的对象必须实现Serializable接口(Externalnalizable也行)。
/**
* 实体类保存信息
* @author Administrator
*/
public class PersonEntity implements Serializable {
private static final long serialVersionUID = -5802989937522643573L;
private String name;
private int age;
public PersonEntity(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "PersonEntity [name=" + name + ", age=" + age + "]";
}
}
2.2 序列化、反序列化对象,并实现数据读写
/**
* 将对象向文件中写、读
* @author Administrator
*/
public class Main {
private static String FILE_PATH = "E:/temp.cache";
private static File FILE_TEMP;
static {
try {
FILE_TEMP = new File(FILE_PATH);
FILE_TEMP.delete();
FILE_TEMP.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
try ( FileOutputStream outF = new FileOutputStream(FILE_TEMP);
ObjectOutputStream out = new ObjectOutputStream(outF)) {
/* 准备写入文件的对象(数据部分). */
PersonEntity entity1 = new PersonEntity("熊燕子", 26);
PersonEntity entity2 = new PersonEntity("军", 25);
/* 写第一条记录. */
out.writeInt(1);
out.writeInt(64);
out.writeObject(entity1);
/* 写第二条记录. */
out.writeInt(2);
out.writeInt(128);
out.writeObject(entity2);
/* 将数据刷入文件. */
out.flush();
}
try ( FileInputStream inF = new FileInputStream(FILE_TEMP);
ObjectInputStream in = new ObjectInputStream(inF)) {
/* 读第一条记录. */
int no1 = in.readInt();
int len1 = in.readInt();
PersonEntity entity1 = (PersonEntity) in.readObject();
/* 读第二条记录. */
int no2 = in.readInt();
int len2 = in.readInt();
PersonEntity entity2 = (PersonEntity) in.readObject();
System.out.println("no1 = " + no1 + "; len1 = " + len1 + "; " + entity1);
System.out.println("no2 = " + no2 + "; len2 = " + len2 + "; " + entity2);
}
}
}
上述运行结果为:

从运行结果可以看出对象被正确写入文件、正确从文件中读取,但是上述过程并没有发挥快速检索的优势,仍然是从流中依次读取每个字段。分析ObjectOutputStream、ObjectInputStream的API,貌似并不支持对象的skip方法,因此,可以考虑将对象转化为字节数组写入流中,从流中读取对象的字节数组后转为我们所需要的对象。那么,关键问题就转为如何实现对象和字节数组之间的等价转换。
3. 对象、字节数组、文件之间的转换
直接上转换的工具类:
package com.wj.serializable;
import java.io.BufferedOutputStream;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Byte_File_Object {
/**
* 将文件内容转化为字节数组
* @param file 文件
* @return
* @throws IOException
*/
public static byte[] getBytesFromFile (File file) throws IOException {
if (file == null) return null;
try ( FileInputStream inF = new FileInputStream(file);
ByteArrayOutputStream out = new ByteArrayOutputStream()) {
byte[] bs = new byte[1024];
int readLen = 0;
while ((readLen = inF.read(bs)) != -1) {
out.write(bs, 0, readLen);
}
return out.toByteArray();
}
}
/**
* 把字节数组保存为一个文件
* @param bs 待保存的字节数组
* @param filePath 文件路径
* @return
* @throws IOException
*/
public static File getFileFromBytes(byte[] bs, String filePath) throws IOException {
File file = new File(filePath);
try ( FileOutputStream fileOutPutStream = new FileOutputStream(file);
BufferedOutputStream bufferOutputStream = new BufferedOutputStream(fileOutPutStream)) {
bufferOutputStream.write(bs);
}
return file;
}
/**
* 将字节数组转化为对象
* @param objBytes 待转化的对象
* @return
* @throws IOException
* @throws ClassNotFoundException
*/
public static Object getObjectFromBytes(byte[] objBytes) throws IOException, ClassNotFoundException {
if (objBytes == null || objBytes.length == 0) return null;
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(objBytes);
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
return objectInputStream.readObject();
}
/**
* 将对象转化为字节数组
* @param obj
* @return
* @throws IOException
*/
public static byte[] getBytesFromObject(Serializable obj) throws IOException {
if (obj == null) return null;
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(obj);
return byteArrayOutputStream.toByteArray();
}
}
只要了解java流的读写API都是基于装饰者模式,很容易理解上述代码,对象、文件、字节数组之间的转化也很简单。下面将对象的序列化读写操作和上述对象、字节数组之间的转化相结合,实现基于文件存储的快速索引。
4. 整合利用java序列化与反序列化的基于文件的快速索引Demo
package com.wj.serializable;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
/**
* 快速索引Demo
* 按照每条记录的协议:索引(4byte) + 数据长度(4byte) + 数据部分(变长) 的格式写入三条记录
* 读取数据的时候:
* * 第一条数据假设命中,读取数据部分;
* * 第二条记录假设未命中,跳过数据部分;
* * 第三条记录假设命中,读取数据部分
* 若可正确读取,则表示此方式可行(性能项目中实测提升名明显,这里未做测试)
*/
public class QuickIndex {
private static String FILE_PATH = "E:/temp.cache";
private static File FILE_TEMP;
static {
try {
FILE_TEMP = new File(FILE_PATH);
FILE_TEMP.delete();
FILE_TEMP.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws FileNotFoundException, IOException, ClassNotFoundException {
/** 第一部分连续写入三条记录. */
try ( FileOutputStream outF = new FileOutputStream(FILE_TEMP);
ObjectOutputStream out = new ObjectOutputStream(outF)) {
/* 准备写入文件的对象(数据部分). */
PersonEntity entity1 = new PersonEntity("熊燕子", 26);
PersonEntity entity2 = new PersonEntity("小王", 25);
PersonEntity entity3 = new PersonEntity("大王", 49);
/* 写第一条记录. */
byte[] objBytes1 = Byte_File_Object.getBytesFromObject(entity1);
int no1 = 1;
int len1 = objBytes1.length;
out.writeInt(no1);
out.writeInt(len1);
out.write(objBytes1);
/* 写第二条记录. */
byte[] objBytes2 = Byte_File_Object.getBytesFromObject(entity2);
int no2 = 2;
int len2 = objBytes2.length;
out.writeInt(no2);
out.writeInt(len2);
out.write(objBytes2);
/* 写第三条记录. */
byte[] objBytes3 = Byte_File_Object.getBytesFromObject(entity3);
int no3 = 3;
int len3 = objBytes3.length;
out.writeInt(no3);
out.writeInt(len3);
out.write(objBytes3);
/* 将数据刷入文件. */
out.flush();
}
/** 第二部分读取记录(第二条记录skip). */
try ( FileInputStream inF = new FileInputStream(FILE_TEMP);
ObjectInputStream in = new ObjectInputStream(inF)) {
/* 读第一条记录. */
int no1 = in.readInt();
int len1 = in.readInt();
byte[] byteArray1 = readAccurateLenBytesFromInStream(in, len1);
PersonEntity entity1 = (PersonEntity) Byte_File_Object.getObjectFromBytes(byteArray1);
/* 读第二条记录. */
int no2 = in.readInt();
int len2 = in.readInt();
in.skip(len2); // 跳过第二条记录的数据部分
/* 读第三条记录. */
int no3 = in.readInt();
int len3 = in.readInt();
byte[] byteArray3 = readAccurateLenBytesFromInStream(in, len3);
PersonEntity entity3 = (PersonEntity) Byte_File_Object.getObjectFromBytes(byteArray3);
System.out.println("no1 = " + no1 + "; len1 = " + len1 + "; " + entity1);
System.out.println("no2 = " + no2 + "; len2 = " + len2 + "; ");
System.out.println("no3 = " + no3 + "; len3 = " + len3 + "; " + entity3);
}
}
/**
* 从输入流中读取指定长度的字节,保存到字节数组中
* @param in 输入流
* @param len 读取的字节数
* @return 返回字节数组
* @throws IOException
*/
private static byte[] readAccurateLenBytesFromInStream(ObjectInputStream in, int len) throws IOException {
byte[] bs = new byte[len];
int tempLen = 0;
int readLen = 0;
while (true) {
tempLen = in.read(bs, readLen, len - readLen);
readLen += tempLen;
if (readLen == len) break;
}
return bs;
}
}
运行结果为:
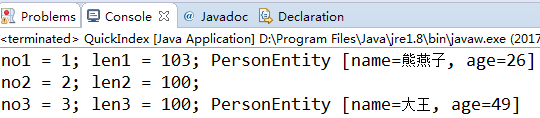
可以发现,读取流的过程中,成功跳过第二条记录的数据部分,正确读出第三条记录。
代码中的相关说明已经很详细,我这里也不做过多阐述,不过其中有一点值得一提,java从输入流以阻塞方式读取数据时,受操作系统保存文件的分区或网络传输的影响,一次读取的字节数组大小并不确定,因此提取readAccurateLenBytesFromInStream方法从流中读取指定大小的字节数组,从而正确转化为对象。
代码下载地址:http://pan.baidu.com/s/1dE5HMH7,密码:h7hl