python 数据分析(数据清洗与准备——处理缺失值)
数据清洗与准备——处理缺失值
一、NA 处理方法
1、NA 处理方法说明:
| 函数名 | 描述 |
|---|---|
| dropna | 根据每个标签的值是否是缺失数据来筛选轴标签,并根据允许丢失的数据量来确定阙值 |
| fillna | 用某些值填充缺失的数据或使用插值方法(如 “ffill” 或 “bfill”) |
| isnull | 返回表明哪些值是缺失值的布尔值 |
| notnull | 返回表明哪些值不是缺失值的布尔值 |
2、NA 处理方法实例:
(1) dropna():根据每个标签的值是否是缺失数据来筛选轴标签,并根据允许丢失的数据量来确定阙值



默认 aixs=0,how="any",删除带有空值的行,只要有一个空值,就删除整行:

axis=1,删除带有空值的列,只要有一个空值,就删除整列(不支持 Series 结构的数据):

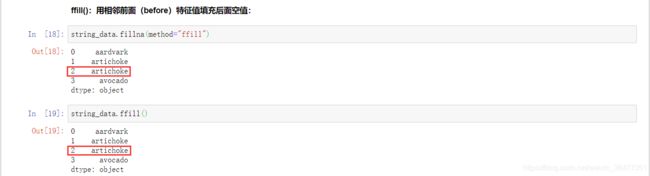
(2) fillna():用某些值填充缺失的数据或使用插值方法(如 “ffill” 或 “bfill”)



bfill():用相邻后面(back)特征值填充前面空值:
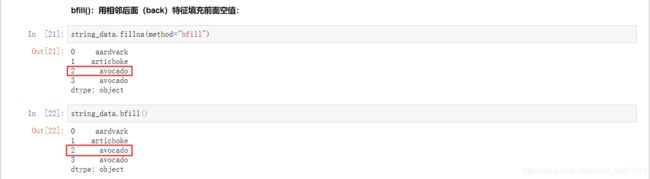
ffill():用相邻前面(before)特征值填充后面空值:
(3) isnull():返回表明哪些值是缺失值的布尔值

Python 内建的 None 值在对象数组中也被当做 NA 处理:

(4) notnull():返回表明哪些值不是缺失值的布尔值

二、过滤缺失值
有多种过滤缺失值的方法。虽然我们可以使用 pandas.isnull 和 布尔值索引 手动地过滤缺失值,但 dropna 在过滤缺失值时是非常有用的。
1、使用 dropna 在 Series 数据集中过滤缺失值数据



等价于:

2、使用 dropna 在 DataFrame 数据集中过滤缺失值数据
(1) 过滤行数据:


dropna 默认情况下会删除包含缺失值的行:
![]()

传入 how="all" 时,将删除所有值均为 NA 的行:

(2) 过滤列数据:
![]()

传入 axis=1,删除包含缺失值的列:

传入 axis=1, how="all" 时,将删除所有值均为 NA 的列:

(3) 往 dropna 中传入参数 thresh,保留包含一定数量的观察值的行(thresh=n,保留至少有 n 个非 NA 数的行)


设置前 0、1、2、3 行 1 列的特征值为 NA:

设置前 0、1 行 2 列的特征值为 NA:
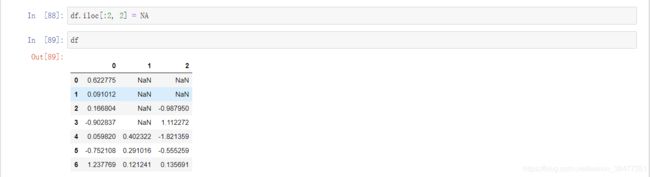
调用 dropna 函数,不传参:

调用 dropna 函数,传入参数 thresh=1,保留至少有 1 个非 NA 数的行:

调用 dropna 函数,传入参数 thresh=2,保留至少有 2 个非 NA 数的行:

调用 dropna 函数,传入参数 thresh=3,保留至少有 3 个非 NA 数的行:

调用 dropna 函数,传入参数 thresh=4,保留至少有 4 个非 NA 数的行:

三、补全缺失值
1、使用 fillna 方法补全缺失值
fillna 函数参数:
| 参数 | 描述 |
|---|---|
| value | 标量值或字典型对象用于填充缺失值 |
| method | 插值方法,如果没有其他参数,默认是“ffill” |
| axis | 需要填充的轴,默认 axis=0 |
| inplace | 修改被调用的对象,而不是生成一个备份 |
| limit | 用于前向或后向填充时最大的填充范围 |
(1) 调用 fillna 时,使用一个常数来替代缺失值:


设置前 0、1、2、3 行 1 列的特征值为 NA:

设置前 0、1 行 2 列的特征值为 NA:

使用常数 0 替代缺失值:

(2) 调用 fillna 时,使用字典,可以为不同的列设定不同的填充值:
设置前 0、1、2、3 行 1 列的特征值为 NA:
设置前 0、1 行 2 列的特征值为 NA:
使用字典 {1: 0.5, 2: 0} 替代缺失值:(第1列的缺失值使用0.5填充,第2列的缺失值使用0填充)

(3) fillna 返回的是一个新的对象,但我们也可以修改已经存在的对象
设置前 0、1、2、3 行 1 列的特征值为 NA:
设置前 0、1 行 2 列的特征值为 NA:
修改已经存在的 df 对象:

(4) 用于重建索引的相同插值方法也可以用于 fillna:


设置 2、3、4、5 行 1 列的特征值为 NA,设置 4、5 行 2 列的特征值为 NA:


使用 method 插值方法,如果没有其他参数,默认是“ffill”:


使用 method 插值方法,传入 limit 参数设置向前或向后填充时最大的填充范围:

(5) 使用 fillna 完成带有一点创造性的工作(例如,将 Series 的平均值 或 中位数 用于填充缺失值):


将 Series 的平均值用于填充缺失值:

将 Series 的中位数用于填充缺失值:
