JML表达式
-
JML的表达式是对Java表达式的扩展
-
新增了一些操作符和原子表达式。
-
-
优先级
-
见JML语言手册12.3节(Expression)获得完整的优先级列表。
-
-
新增的表达式成分仅用于JML中的断言(assertion)语句和其他相关的注释体
-
特别注意
-
在JML断言中,不可以使用带有赋值语义的操作符,如 ++,--,+= 等操作符
-
原子表达式
-
\result表达式
-
个非 void 类型的方法执行所获得的结果,即方法执行后的返回值
-
-
\old( expr )表达式
-
一个表达式 expr 在相应方法执行前的取值。
-
遵从Java的引用规则
-
都应该使用\old把关心的表达式取值整体括起来。
-
-
-
\not_assigned(x,y,...)表达式
-
来表示括号中的变量是否在方法执行过程中被赋值。
-
没有被赋 值,返回为 true ,否则返回 false
-
-
主要用于后置条件的约束表示上
-
限制一个 方法的实现不能对列表中的变量进行赋值
-
-
-
\not_modified(x,y,...)表达式
-
限制括号中的变量在方法 执行期间的取值未发生变化
-
-
\nonnullelements( container )表达式
-
表示 container 对象中存储的对象不会有 null
-
-
\type(type)表达式
-
返回类型type对应的类型(Class)
-
JML 采用的缩略表示
-
等同于Java中的 java.lang.Class
-
-
-
\typeof(expr)表达式
-
式返回expr对应的准确类型。
-
量化表达式
-
\forall表达式
-
全称量词修饰的表达式
-
-
\exists表达式
-
存在量词修饰的表达式,
-
-
\sum表达式
-
返回给定范围内的表达式的和
-
-
\product表达式
-
返回给定范围内的表达式的连乘结果
-
-
\max表达式
-
\min表达式
-
num_of表达式
-
返回指定变量中满足相应条件的取值个数
-
集合表达式
-
集合构造表达式
-
可以在JML规格中构造一个局部的集合(容器),,明确集合中可以包含的元素
-
:new ST {T x|R(x)&&P(x)},
-
R(x)对应集合中x的范围
-
P(x)对应x取值的约束
-
-
操作符
-
正常使用java中操作符
-
括算术操作符、逻辑预算操作符等
-
-
专门定义的操作符
-
子类型关系操作符
-
E1<:E2
-
子类型(sub type),则该表达式的结果为真
-
是相同的类型,该表达式的结果也为真
-
任意一个类X,都必然满足 X.TYPE<:Object.TYPE
-
-
-
等价关系操作
-
b_expr1<==>b_expr2 或者 b_expr1<=!=>b_expr2
-
中b_expr1和b_expr2都 是布尔表达式
-
<==> 比 == 的优先级要低
-
-
推理操作符
-
b_expr1==>b_expr2 或者 b_expr2<==b_expr1
-
-
变量引用操作
-
关键词
-
\nothing指示一个空集
-
\everything指示一个全集
-
-
变量引用操作符经常在assignable句子中使用
-
-
应用工具链
JMLUnitNG
可以根据JML生成一个java类文件测试的框架,结合openjml的-rac运行时检查选项,实现对代码的自动化测试。
OPENJML
在Intellij中安装openJML插件,可以进行规格检查。
JMLUnitNG测试
测试发现其能够构造一些数据,但是并没有构造边界数据的能力,一定程度上有作用,但是不能完全依靠自动评测。
架构设计
第一次作业
要求
第一次作业简单地实现了一个一个社交网络系统,包括两个接口Person和Network,我们需要根据JML规格实现对应的接口,完成相应的代码,并在main函数中运行以验证结果。
UML图
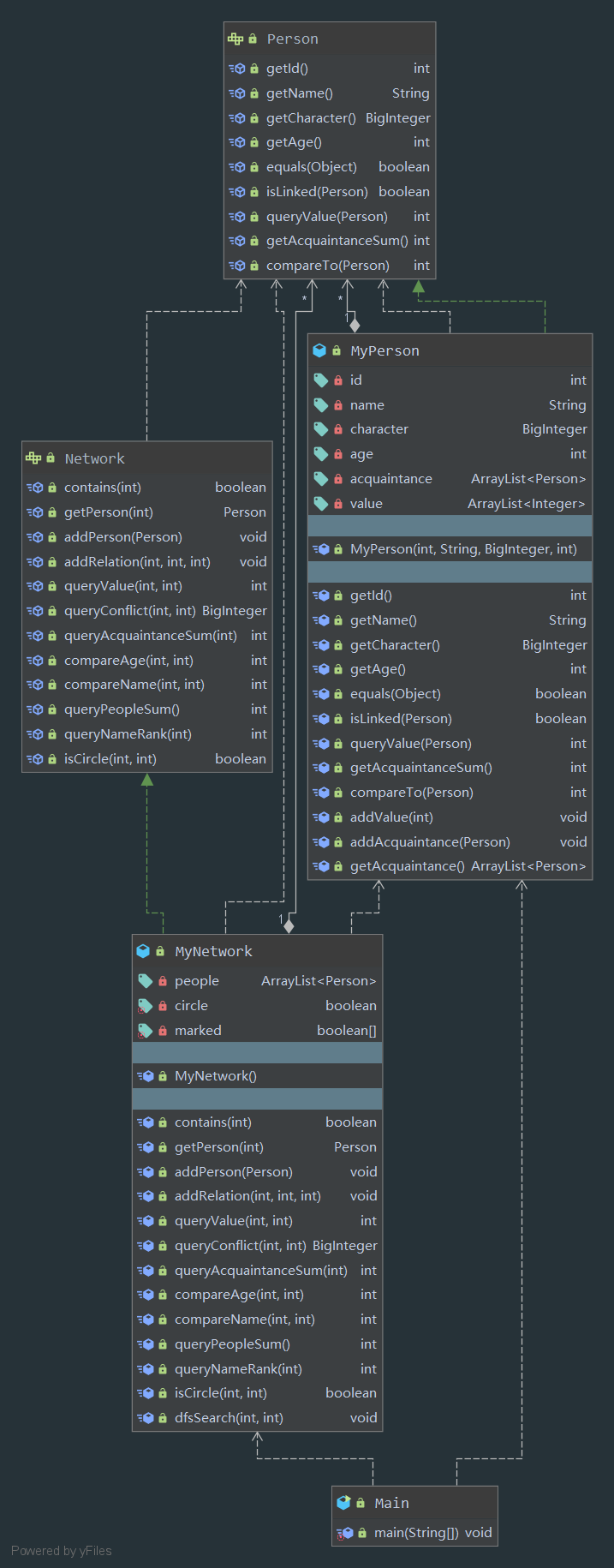
第一次作业比较简单,基本就是阅读JML然后写代码就行了。
大部分的集合类的数据结构我都是使用ArrayList来实现的。
唯一需要动心思的地方是isCir函数,这里我使用了数据结构课上学习过的深度优先搜索算法,在MyNetwork中我使用Boolean[] Marked来判定是否被访问过。
第二次作业
要求
第二次作业在第一次作业的基础上增加了Group接口,需要实现Group中的方法和Network中的增加的方法。
UML图
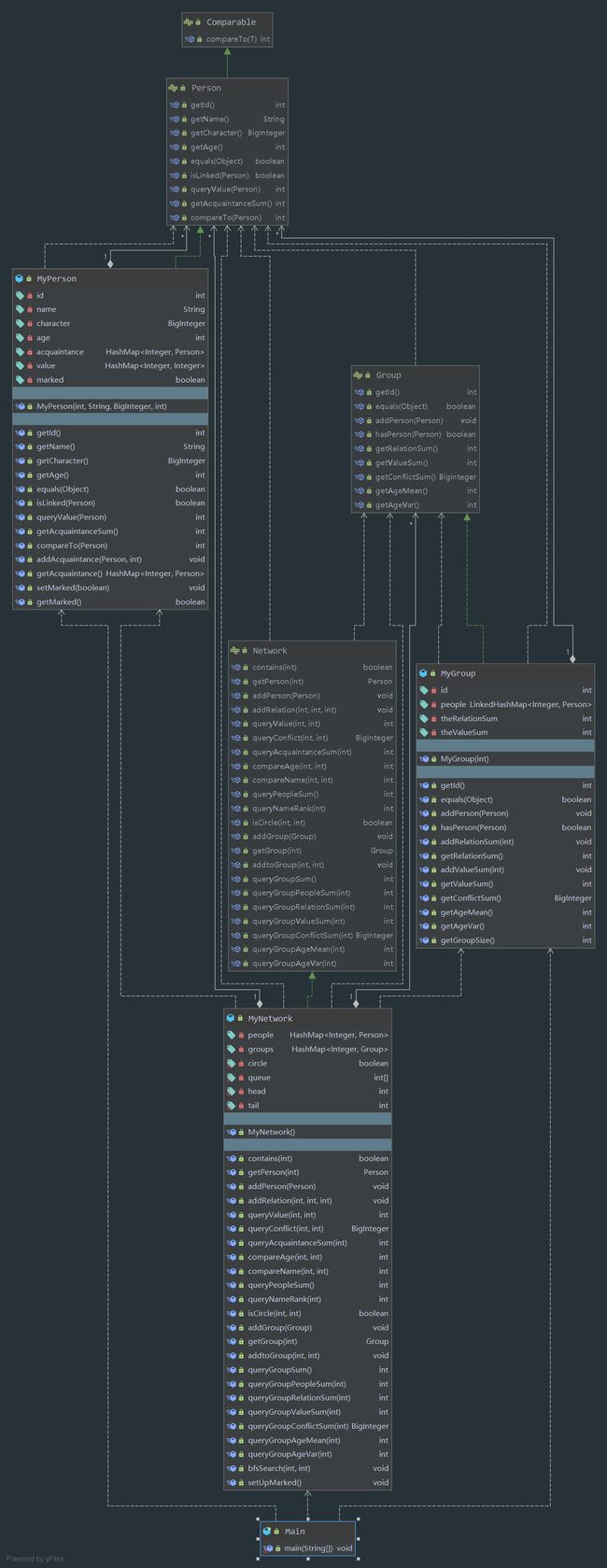
第二次作业看起来并不难,但是强测指令数量可达10万条,而且对CPU时间有了限制。
由于涉及到许多查询的操作,我放弃了ArrayList转而投向HashMap的怀抱,大部分的HashMap都是以PersonId为Key,这样就能减少时间复杂度。在了解到HashMap的复制和扩容机制后,我还设置了部分HashMap的初始化容量,以空间换时间。
另外,我听说深度优先搜索可能会爆栈,于是改用了广度优先搜索bfs,bfs实质上是一个栈的数据结构,不用递归。我还放弃使用了Boolean[] Marked,而是在每一个Person中都增加了一个Boolean Marked变量,便于管理。
第三次作业
要求
第三次作业没有增加新的接口,只增加了部分方法。
UML图
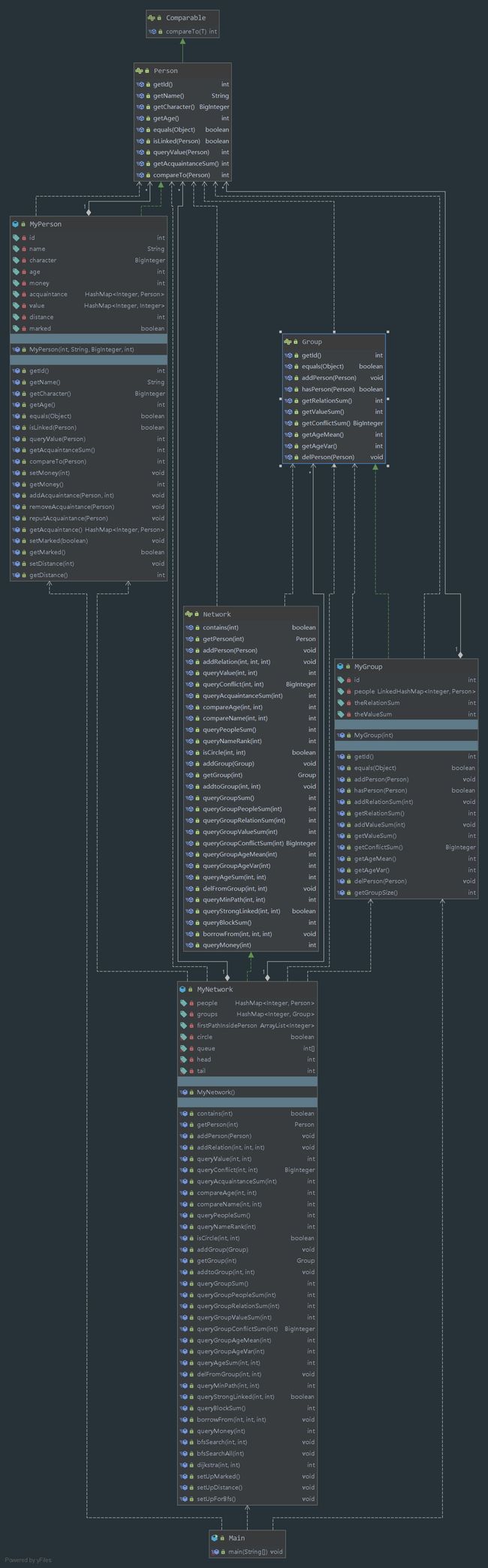
第三次作业大部分代码比较好写,需要注意的只有queryBlockSum、queryMinPath和queryStrongLinked方(以下使用缩写简称)。
qbs的JML阅读起来比较困难,一开始不太好懂,但稍加思考就会发现这就是求连通块的数量,再回头看方法名,不就是BlockSum吗?正解。我还是基于广度优先搜索实现的,采用填充的方式,对每个person遍历,如果该person没有被访问过,则进行广度优先搜索,并标记该person所有的acquaintance,这样进行广度优先搜索的次数刚好是连通块的数目。
qmp则是典型的迪杰斯特拉算法问题。在这里我并没有使用堆优化,当然这是由于我很菜。
qsl则是一个点双连通分量的问题,分为两种情况来处理。第一种情况是p1和p2是朋友关系,则先删除其朋友关系,再判断是否linked,最后恢复朋友关系。第二种情况是,p1和p2不是直接朋友关系,但他们之间通过一些其他人联系着,这时p1和p2之间有很多中间朋友,删除任意一个朋友,看p1和p2是否仍isCircle,如果是则返回true,否则返回false。
bug分析
第一次作业
第一次作业强测只拿了20分,互测未被hack。
原因出在深度优先搜索dfs上,我将当时数据结构上课的代码生搬硬套地拿了过来,当时是基于链表实现的有向图,而作业中是无向图,有向图可以采用marked=true;dfs();marked=false;这样的结构来优化,而无向图可能会出现死循环,我没有注意到这一点。
后来我发现其实是不用这么“优化”的,直接dfs就好了,我可能是个撒贝吧。
第二次作业
第二次作业强测拿到80分,互测被hack1次。
原因果然出在时间复杂度上,在queryGroupValueSum和queryGroupRelationSum的时候,我单纯地就照着JML的写了,每次查询都用了若干个循环。
后来我用了缓存和更新制,只在初始化和变化时才更新值,查询就直接返回,减少了时间复杂度。
第三次作业
第三次作业强测拿到85分,互测未被hack。
原因出在queryMinPath上,我没写堆优化的迪杰斯特拉算法,然后就被卡时间了,当时确实没搞懂怎么堆优化。
可能我就是菜吧。
心得体会
在刚刚接触JML时我确实是有一点抵触的,这不就是纯阴间玩意儿嘛。但是写作业时却发现,作业还挺好写的。
这几次作业的难点其实都在数据结构和离散上面,看来所有的知识都是互通的,前面欠的总有一天要还的。
JML在于给出规范,可能在目前来说对我们没有特别明显的作用,但是相信在工程开发中,一个严格的规范是开发的必然标准,学习规范绝对有非常有用的。
不知不觉OO课程就过去一大半了,这一路,我虽然并不是很出色,但是大部分作业都还能拿一个高分,也从来没有出现过无效作业,他们说OO很难,每周熬几天的夜,可是我基本没有熬过夜。不知道怎么说,我感觉自己好像什么也没学到,但是什么作业都完成了,这学期很快既要结束了,我就这样在家度过了OO,度过了大二下学期,真是有够神奇的,有点像做梦。