hive-metastore结构
Hive MetaStore数据库表结构图
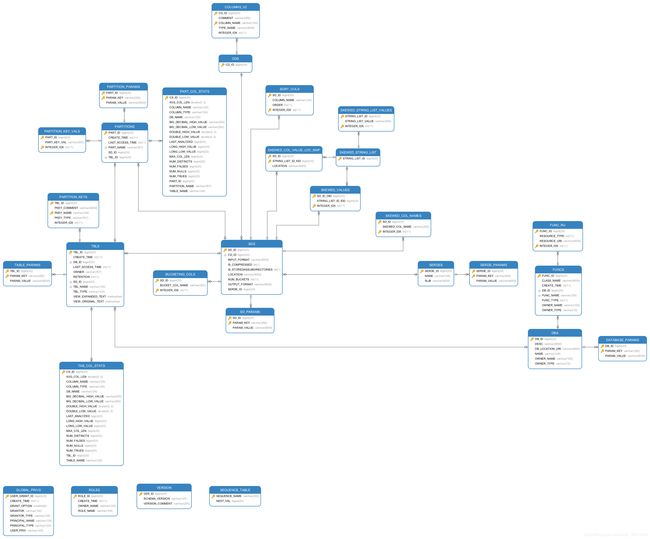
整体概括
DBS
Columns: DB_ID、DESC、DB_LOCATION_URI、NAME、OWNER_NAME、OWNER_TYPE
DBS 表记录基本的db信息,其中DB_ID为其主键,同时也是FUNC_RU、FUNCS、DB_PRIVS、DATABASE_PARAMS、以及TBLS的外键。
一般来说,在hive meta初始化时都会自动创建一个名叫default的库,随后通过业务发展以及数据治理等需求,可进行不同业务域库的划分。
FUNC 表是用来存储udf的基本信息,一个UDF只能对应一个库下的表。FUNC_RU表,用于存储该udf的类型及指向的路径。
DB_PRIVS 表记录该DB下的权限记录信息,具体没怎么研究,因为现在更多的集成开源的类似于sentry、range等成熟的权限框架。
DATABASE_PARAMS 表记录DB的一些扩展信息,便于进行特殊属性的扩展。
TBLS 表自然是记录该DB下的所有Table信息。对应唯一的DB_ID。
TBLS
Columns: TBL_ID、CREATE_TIME、DB_ID,LAST_ACCESS_TIME、OWNER、RETENTION、SD_ID、TBL_NAME、TBL_TYPE、VIEW_EXPANDED_TEXT、VIEW_ORIGNAL_TEXT
首先,TBLS表,这个表主要记录了table的一些基本信息,包括表名、创建时间、类型,以及SD_ID等信息。tbl_id为TBLS的主键,同时也是TABLE_PARAMS、TBL_COL_PRIVS、IDXS、TBL_PRIVS、SDS、PARTITIONS、PARTITION_KEYS、TAB_COL_STATS表的外键。
每个TBLS都对应唯一的DB_ID,取决于你在哪个db下创建的表。在创建表写入meta的同时,也会创建相应的物理路径。同时会在SDS表中加入DDL时设置的input output、表的location以及SERDE信息(具体下面再说)
TBL_PRIVS、TBL_COL_PRIVS表记录该hive表的表及列权限认证信息。PARTITIONS表记录该表的DDL分区的信息,对于PARTITION_KEYS以及PARTITION_VALUES都是用于PartName的拼接获取。(可查看本博客 hive metadata源码解析)
(IDXS 与 TAB_COL_STATS还没有深入研究,后续添加)
PARTITIONS
Columns: PART_ID、CREATE_TIME、LAST_ACCESS_TIME、PART_NAME、SD_ID、TBL_ID
PARTITIONS表,通过表名也能才想到,它是partition分区存储的元数据信息。
PART_ID为PARTITIONS表的主键,同时也是PART_COL_STATS、PART_PRIVS、PARTITION_KEY_VALS、PARTITION_PARAMS、DATABASE_PARAMS表的外键。
Partition表在metastore中是相当重要的表,关系到partition的元数据存取(具体可参考本博客hive metastore partition篇)
SDS
Columns: SD_ID、CD_ID、INPUT_FORMAT、IS_COMPRESSED、IS_STOREDASSUBDIRECTORIES、LOCATION\NUM_BUCKETS、OUTPUT_FORMAT、SERDE_ID
SDS表主要包含计算引擎运行时需要的input与output 、location路径以及序列化的class信息。SD_ID为该表的主键,同时也是PARTITIONS、BUCKETING_COLS、SKEWD_COL_NAMES、SD_PARAMS、SORT_COLS、SKEWED_VALUES、IDXS的外键。
TBLS
记录数据表的信息
| 字段 | 解释 |
|---|---|
| TBL_ID | 在hive中创建表的时候自动生成的一个id,用来表示,主键 |
| CREATE_TIME | 创建的数据表的时间,使用的是时间戳 |
| DBS_ID | 这个表是在那个数据库里面 |
| LAST_ACCESS_TIME | 最后一次访问的时间戳 |
| OWNER | 数据表的所有者 |
| RETENTION | 保留时间 |
| SD_ID | 标记物理存储信息的id |
| TBL_NAME | 数据表的名称 |
| TBL_TYPE | 数据表的类型,MANAGED_TABLE, EXTERNAL_TABLE, VIRTUAL_VIEW, INDEX_TABLE |
| VIEW_EXPANDED_TEXT | 展开视图文本,非视图为null |
| VIEW_ORIGINAL_TEXT | 原始视图文本,非视图为null |
TBLS的SD_ID与SDS的SD_ID进行关联,TBLS的DB_ID与DBS的DB_ID进行关联,相关的thrift类为Table,StorageDescriptor。
//由于TBLS与DBS有关联,可以看到当前表是数据那个数据库。
//表的信息
mysql> select * from tbls where tbl_id=71 and db_id=1;
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
| 71 | 1548340018 | 1 | 0 | hadoop | 0 | 91 | emp | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+--------+-----------+-------+----------+---------------+--------------------+--------------------+
//数据库的信息
mysql> select * from dbs where db_id=1;
+-------+-----------------------+-------------------------------------------+---------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+
| 1 | Default Hive database | hdfs://hadoop001:9000/user/hive/warehouse | default | public | ROLE |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+
Version
这个表是记录Hive的版本,这个表里面只能有一条记录,这样Hive才能启动。在创建源数据表的时候,自动写入的信息。相关的thrift类为version。
在初始化源数据表的时候,插入一条数据。
INSERT INTO VERSION (VER_ID, SCHEMA_VERSION, VERSION_COMMENT) VALUES (1, '1.1.0', 'Hive release version 1.1.0');
//获取到的结果为:
mysql> select * from version;
+--------+----------------+--------------------------------------+
| VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+--------+----------------+--------------------------------------+
| 1 | 1.1.0 | Set by MetaStore hadoop@10.140.42.16 |
+--------+----------------+--------------------------------------+
DBS
记录数据库的信息
| 字段 | 解释 |
|---|---|
| DB_ID | 数据库的编号,默认的数据库编号为1,如果创建其他数据库的时候,这个字段会自增,主键 |
| DESC | 对数据库进行一个简单的介绍 |
| DB_LOCATION_URI | 数据库的存放位置,默认是存放在hdfs://ip:9000/user/hive/warehouse,如果是其他数据库,就在后面添加目录,默认位置可以通过参数hive.metastore.warehouse.dir来设置 |
| NAME | 数据库的名称 |
| OWNER_NAME | 数据库所有者名称 |
| OWNER_TYPE | 数据库所有者的类型 |
DBS的DB_ID与DATABASE_PARAMS的DB_ID进行关联。
相关的thrift类为Database
#查看所有的数据库
mysql> select * from dbs;
+-------+-----------------------+------------------------------------------------------+---------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+------------------------------------------------------+---------+------------+------------+
| 1 | Default Hive database | hdfs://hadoop001:9000/user/hive/warehouse | default | public | ROLE |
| 2 | NULL | hdfs://hadoop001:9000/user/hive/warehouse/xiaoyao.db | xiaoyao | hadoop | USER |
+-------+-----------------------+------------------------------------------------------+---------+------------+------------+
TABLE_PARAMS
| 字段 | 解释 |
|---|---|
| TBL_ID | 数据的编号 |
| PARAM_KEY | 参数 |
| PARAM_VALUE | 参数的值 |
TABLE_PARAMS的TBL_ID与TBLS的TBL_ID的进行关联,TBL_ID与PARAM_KEY作为联合主键。
每个表的信息基本上都有如下属性:
| 参数 | 值 |
|---|---|
| COLUMN_STATS_ACCURATE | 精确统计列 |
| numFiles | 文件数 |
| numRows | 行数 |
| rawDataSize | 原始数据大小 |
| totalSize | 当前大小 |
| transient_lastDdlTime | 最近一次操作的时间戳 |
//对tbls中的数据表进行一个介绍:文件的数量、数据行数、数据总的大小等介绍
mysql> select * from table_params where tbl_id=71;
+--------+-----------------------+-------------+
| TBL_ID | PARAM_KEY | PARAM_VALUE |
+--------+-----------------------+-------------+
| 71 | COLUMN_STATS_ACCURATE | true |
| 71 | numFiles | 1 |
| 71 | numRows | 0 |
| 71 | rawDataSize | 0 |
| 71 | totalSize | 701 |
| 71 | transient_lastDdlTime | 1548340028 |
+--------+-----------------------+-------------+
SDS
此对象包含有关属于表的数据的物理存储的所有信息,数据表的存储描述
| 字段 | 解释 |
|---|---|
| SD_ID | 主键 |
| CD_ID | 数据表编号 |
| INPUT_FORMAT | 数据输入格式 |
| IS_COMPRESSED | 是否对数据进行了压缩 |
| IS_STOREDASSUBDIRECTORIES | 是否进行存储在子目录 |
| LOCATION | 数据存放位置 |
| NUM_BUCKETS | 分桶的数量 |
| OUTPUT_FORMAT | 数据的输出格式 |
| SERDE_ID | 序列和反序列的信息 |
SDS的SERDE_ID与SERDES的SERDE_ID进行关联,SDS的CD_ID与CDS的CD_ID进行关联。相关的thrift表为StorageDescriptor。
//数据的存储格式
mysql> select * from sds where sd_id=91;
+-------+-------+------------------------------------------+---------------+---------------------------+-----------------------------------------------+-------------+------------------------------------------------------------+----------+
| SD_ID | CD_ID | INPUT_FORMAT | IS_COMPRESSED | IS_STOREDASSUBDIRECTORIES | LOCATION | NUM_BUCKETS | OUTPUT_FORMAT | SERDE_ID |
+-------+-------+------------------------------------------+---------------+---------------------------+-----------------------------------------------+-------------+------------------------------------------------------------+----------+
| 91 | 71 | org.apache.hadoop.mapred.TextInputFormat | | | hdfs://hadoop001:9000/user/hive/warehouse/emp | -1 | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | 91 |
+-------+-------+------------------------------------------+---------------+---------------------------+-----------------------------------------------+-------------+------------------------------------------------------------+----------+
CDS
记录数据表的编号
| 字段 | 解释 |
|---|---|
| CD_ID | 主键,记录数据表的编号 |
这个是一个自增的序列,就是一个标识。
SERDES
记录序列化和反序列化信息
| 字段 | 解释 |
|---|---|
| SERDE_ID | 主键,记录序列化的编号 |
| NAME | 序列化和反序列化名称,默认为表名 |
| SLIB | 使用的是哪种序列化方式 |
相关的thrift表为SerDeInfo
//使用何种序列化
mysql> select * from serdes where serde_id=91;
+----------+------+----------------------------------------------------+
| SERDE_ID | NAME | SLIB |
+----------+------+----------------------------------------------------+
| 91 | NULL | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
+----------+------+----------------------------------------------------+
SERDES_PARAMS
| 字段 | 解释 |
|---|---|
| SERDE_ID | 主键,记录序列化的编号 |
| PARAM_KEY | 参数名称 |
| PARAM_VALUE | 参数的值 |
SERDES_PARAMS的SERDE_ID与SERDES的SERDE_ID进行关联。
//序列化的方式
mysql> select * from serde_params where serde_id=91;
+----------+----------------------+-------------+
| SERDE_ID | PARAM_KEY | PARAM_VALUE |
+----------+----------------------+-------------+
| 91 | field.delim | |
| 91 | serialization.format | |
+----------+----------------------+-------------+
#DATABASE_PARAMS
| 字段 | 解释 |
|---|---|
| DB_ID | 数据库的编号 |
| PARAM_KEY | 参数名称 |
| PARAM_VALUE | 参数值 |
DB_ID是一个主键,使得DBS与DATABASE_PARAMS关联。
TAB_COL_STATS
数据表的列信息统计
| 字段 | 解释 |
|---|---|
| CS_ID | 列统计编号 |
| AVG_COL_LEN | 数据的平均长度 |
| MAX_COL_LEN | 数据的最大长度 |
| COLUMN_NAME | 列的名字 |
| COLUMN_TYPE | 列的类型 |
| DB_NAME 数据库的名称 | |
| BIG_DECIMAL_HIGH_VALUE | 数据中最大的Decimal值 |
| BIG_DECIMAL_LOW_VALUE | 数据中最小的Decimal值 |
| DOUBLE_HIGH_VALUE | 数据中最大的Double值 |
| DOUBLE_LOW_VALUE | 数据中最小的Double值 |
| LAST_ANALYZED | 最新一次解析的时间戳 |
| LONG_HIGH_VALUE | 数据中最大的Long值 |
| LONG_LOW_VALUE | 数据中最小的Long值 |
| NUM_DISTINCTS | 不同记录的数量 |
| NUM_FALSES | 为false的数量 |
| NUM_NULLS | 为null的数量 |
| NUM_TRUES | 为true的数量 |
| TBL_ID | 数据表的编号 |
| TABLE_NAME | 数据表的名称 |
通过tbl_id使得TAB_COL_STATS与tbls关联。
相关的thrift类有:BooleanColumnStatsData、DoubleColumnStatsData、LongColumnStatsData、StringColumnStatsData、BinaryColumnStatsData、
Decimal、DecimalColumnStatsData、ColumnStatisticsData、ColumnStatisticsObj、ColumnStatisticsDesc、ColumnStatistics
Sort_COLS
记录要进行排序的列
| 字段 | 解释 |
|---|---|
| SD_ID | 数据表物理信息描述的编号 |
| COLUMN_NAME | 列的名称 |
| ORDER | 排序方式 |
COLUMNS_V2
用于描述列的信息
| 字段 | 解释 |
|---|---|
| CD_ID | 表的编号 |
| COMMENT | 相关描述信息 |
| COLUMN_NAME | 列的名称 |
| TYPE_NAME | 类的类型 |
这个表与cds通过cd_id关联。
mysql> select * from columns_v2 where cd_id=71;
+-------+---------+-------------+-----------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-------------+-----------+-------------+
| 71 | NULL | common | double | 6 |
| 71 | NULL | deptno | int | 7 |
| 71 | NULL | empno | int | 0 |
| 71 | NULL | ename | string | 1 |
| 71 | NULL | hiredate | string | 4 |
| 71 | NULL | job | string | 2 |
| 71 | NULL | mgr | int | 3 |
| 71 | NULL | sal | double | 5 |
+-------+---------+-------------+-----------+-------------+
FUNCS
记录hive中函数的信息
| 字段 | 解释 |
|---|---|
| FUNC_ID | 函数的编号 |
| CLASS_NAME | 自定义函数的类的名称 |
| CREATE_TIME | 函数创建时间 |
| DB_ID | 作用于那个数据库 |
| FUNC_NAME | 方法名称 |
| FUNC_TYPE | 方法类型 |
| OWNER_NAME | 所有者名称 |
| OWNER_TYPE | 所有者类型 |
这个表里面记录一些hive自带的函数和用户自定义的函数。
相关的thrift类为Function。
FUNC_RU
对函数的相关参数进行描述。
| 字段 | 解释 |
|---|---|
| FUNC_ID | 函数的编号 |
| RESOURCE_TYPE | 资源的类型 |
| RESOURCE_URI | 资源的uri |
相关的thrift类为:ResourceUri、ResourceType。
分区表
PARTITIONS
| 字段 | 解释 |
|---|---|
| PART_ID | 分区的编号 |
| CREATE_TIME | 创建分区的时间 |
| LAST_ACCESS_TIME | 最近一次访问时间 |
| PART_NAME | 分区的名字 |
| SD_ID | 存储描述的id |
| TBL_ID | 数据表的id |
相关的thrift类为:Partition。
#记录要按照某个字段的值进行分区
mysql> select * from partitions;
+---------+-------------+------------------+-----------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+-----------------+-------+--------+
| 16 | 1543046086 | 0 | pt=xiaoyao | 46 | 26 |
| 21 | 1543071202 | 0 | date=2016-05-05 | 56 | 32 |
+---------+-------------+------------------+-----------------+-------+--------+
PARTITION_PARAMS
| 字段 | 解释 |
|---|---|
| PART_ID | 分区的编号 |
| PARAM_KEY | 参数 |
| PARAM_VALUE | 参数的值 |
mysql> select * from partition_params where part_id=21;
+---------+-----------------------+-------------+
| PART_ID | PARAM_KEY | PARAM_VALUE |
+---------+-----------------------+-------------+
| 21 | COLUMN_STATS_ACCURATE | true |
| 21 | numFiles | 1 |
| 21 | numRows | 0 |
| 21 | rawDataSize | 0 |
| 21 | totalSize | 604236 |
| 21 | transient_lastDdlTime | 1543071202 |
+---------+-----------------------+-------------+
PARTITION_KEYS
| 字段 | 解释 |
|---|---|
| TBL_ID | 数据表的编号 |
| PKEY_COMMENT | 分区字段的描述 |
| PKEY_NAME | 分区字段的名称 |
| PKEY_TYPE | 分区字段的类型 |
相关的thrift类为:FieldSchema。
//指定按照那个字段进行分区
mysql> select * from partition_keys;
+--------+--------------+-----------+-----------+-------------+
| TBL_ID | PKEY_COMMENT | PKEY_NAME | PKEY_TYPE | INTEGER_IDX |
+--------+--------------+-----------+-----------+-------------+
| 26 | NULL | pt | string | 0 |
| 32 | NULL | date | string | 0 |
+--------+--------------+-----------+-----------+-------------+
PARTITION_KEY_VALS
| 字段 | 解释 |
|---|---|
| PART_ID | 分区编号 |
| PART_KEY_VAL | 分区字段的值 |
//按照值分区之后,这是第几个分区
mysql> select * from partition_key_vals;
+---------+--------------+-------------+
| PART_ID | PART_KEY_VAL | INTEGER_IDX |
+---------+--------------+-------------+
| 16 | xiaoyao | 0 |
| 21 | 2016-05-05 | 0 |
+---------+--------------+-------------+
查看表的信息
//可以使用命令查看表的所有信息,分区表亦如是。
hive (default)> desc formatted emp;
#表类的信息,对应的表为:COLUMNS_V2
# col_name data_type comment
empno int
ename string
job string
mgr int
hiredate string
sal double
common double
deptno int
# 数据表的详细信息 ,对应的数据表为:TBLS
Database: default
Owner: hadoop
CreateTime: Thu Jan 24 22:26:58 CST 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop001:9000/user/hive/warehouse/emp
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE true
numFiles 1
numRows 0
rawDataSize 0
totalSize 701
transient_lastDdlTime 1548340028
# 表的存储信息 对应的数据表为:TBLS
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.253 seconds, Fetched: 39 row(s)
分区表信息
hive (xiaoyao)> desc formatted emp_test_p;
#列的信息
# col_name data_type comment
empno int
ename string
job string
mgr int
hiredate string
sal double
common double
deptno int
# 分区信息
# col_name data_type comment
pt string
# 表信息
Database: xiaoyao
Owner: hadoop
CreateTime: Sat Nov 24 15:50:25 CST 2018
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop001:9000/user/hive/warehouse/xiaoyao.db/emp_test_p
Table Type: MANAGED_TABLE
Table Parameters:
transient_lastDdlTime 1543045825
# 存储信息
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
删除表
- Hive中删除
drop table emp; - 在MetaStore删除数据表
drop procedure if exists t1;
create procedure t1 ( in tbinput int)
begin
declare v_sd_id int ;
declare v_part_id int ;
declare v_cd_id int ;
declare v_serde_id int ;
select tbinput;
select SD_ID into v_sd_id from tbls where TBL_ID = tbinput;
select part_id into v_part_id from partitions where tbl_id = tbinput;
select cd_id , serde_id into v_cd_id,v_serde_id from sds where sd_id = v_sd_id;
select v_sd_id,v_part_id,v_cd_id,v_serde_id;
if v_part_id is not null then
delete from partition_params where part_id = v_part_id;
delete from partition_key_vals where part_id = v_part_id;
end if;
delete from serdes where serde_id = v_serde_id;
delete from serde_params where serde_id = v_serde_id;
delete from columns_v2 where cd_id = v_cd_id;
delete from sds where sd_id = v_sd_id;
delete from partitions where tbl_id = tbinput;
delete from partition_keys where tbl_id = tbinput;
delete from table_params where tbl_id = tbinput;
delete from tbls where tbl_id = tbinput;
end ;
存放sql语句的位置:hive-1.1.0-cdh5.7.0/metastore/scripts/upgrade/mysql/hive-schema-1.1.0.mysql.sql
存放thrift相关文件的位置:hive-1.1.0-cdh5.7.0/metastore/if/hive_metastore.thrift
存放java相关文件的位置:hive-1.1.0-cdh5.7.0/metastore/src/gen/thrift/gen-javabean/org/apache/hadoop/hive/metastore/api
参考文档
https://crazymatrix.iteye.com/blog/2088338
http://www.icode9.com/content-2-120314.html
https://blog.csdn.net/Gavin_chun/article/details/78416037
https://blog.csdn.net/qq_32252917/article/details/78458115
https://mp.weixin.qq.com/s?__biz=MzA3ODUxMzQxMA==&mid=2663993556&idx=1&sn=0e5291bd63426d747f32a7fd05128caa&scene=21#wechat_redirect