【APP爬虫】mitmproxy抓包工具和夜神模拟器爬虫
mitmproxy抓包工具和夜神模拟器爬取APP的数据
一、相关软件的安装
工欲善其事,必先利其器,要实现我们的需求,当然是先准备我们所需的工具,本次主要主要用的工具有:
查看更多python相关内容,可以查看我的个人网站:大圣的专属空间
- python(这个在此处不提,自行百度进行安装,注意环境变量的配置)
- pycharm(代码编辑器,博主采用的pycharm专业版)
- Visual Studio Code(这个也是个编辑器,安装也很简单,自行百度即可,根据自己喜好选择即可)
- Android SDK(安卓开发环境)
- java SDK(安卓开发依赖环境,其他抓包软件也需要安装)
- mitmproxy(抓包工具,安装方式下面说明)
- mongodb(非关系型数据库)
- RoboMongo/Robo 3T(可视化工具RoboMongo/Robo 3T,下载链接为可视化工具下载)
- 夜神模拟器(手机模拟器,博主开始采用的真机,后来因为老连接出问题及每次用数据线连接太麻烦,所以选择采用模拟器的形式,本次采用夜神模拟器)
安装包如下图所示:
注意(安装过程遇到问题请查看):
-
Android SDK安装
对于Android SDK的安装,博主主要参考崔大大的博客安卓SDK环境配置 -
Java SDK安装
此软件安装按照百度搜索出来的即可:JDK安装 -
mitmproxy安装过程中遇到的问题
- pip install mitmproxy安装过程中的问题
针对mitmproxy的安装,按照崔大大的博客安装教程mitmproxy的安装即可,不过博主的安装过程中运行pip install mitmproxy出现了以下问题:
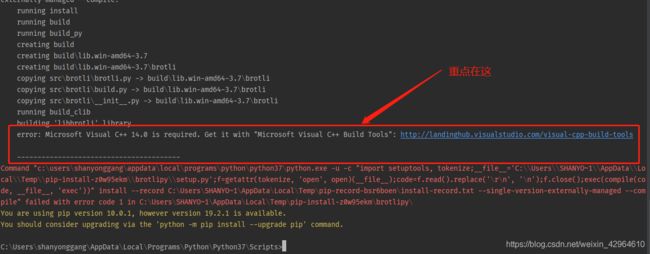
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": https://visualstudio.microsoft.com/downloads/
是因为安装这个包的 window 系统需要首先安装 Microsoft Visual C++ V14.0以上 才行。
目前直接点击蓝色界面已经找不到网页链接(网传该工具国内被墙了,无法直接下载)。
博主的解决方案是:在https://visualstudio.microsoft.com/zh-hans/downloads/直接下载即可,下载打开之后按照如下图所示的方式安装相关插件:
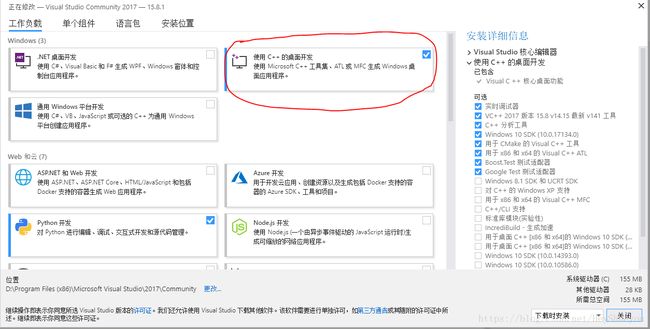
选择“使用 C++ 的桌面开发”,选择默认的安装内容即可(尽量自己定义安装位置),安装过程较慢,耐心等待,安装完成之后在命令行进行安装 mitmproxy即可。
- 证书配置过程中的问题
大致过程安装崔大大博客里介绍的安装即可,有几条提醒的:
- 证书位置(其中文中标记的位.p12文件):
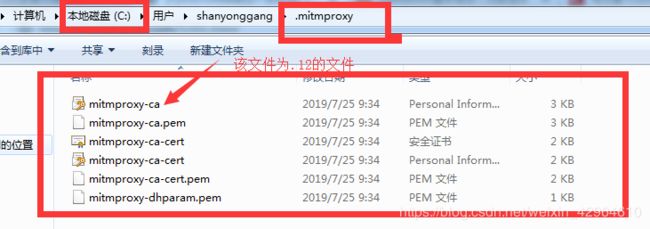
- 手机安装证书的方式:
首先将证书直接拖拽至夜神模拟器中,然后安装以下步骤安装:
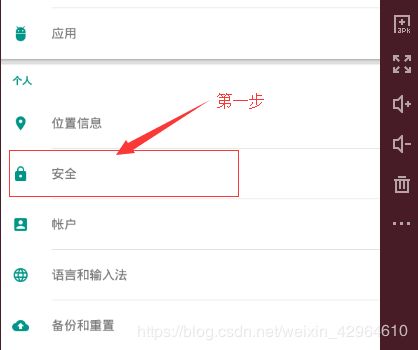
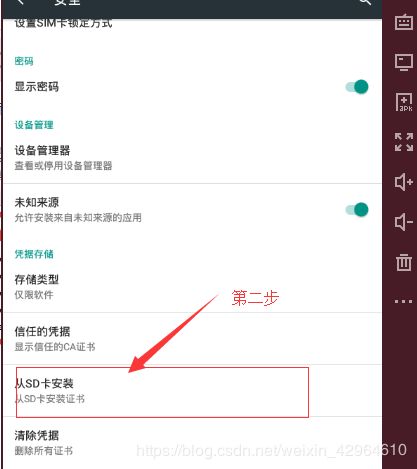
最后从SD卡中选择拖拽过来的证书文件安装即可(怎么选择应该不用教了吧!)
- MongoDB安装
对于Android SDK的安装,博主主要参考崔大大的博客MongoDB安装,其中安装过程中:不要将软件安装在C盘,点击安装 一直执行Next下一步,当进入这个界面的时候,下面的√一定要去掉,不然会安装的特别的慢,如果不去掉,可能要等几个小时以上,博主亲身已经试验过了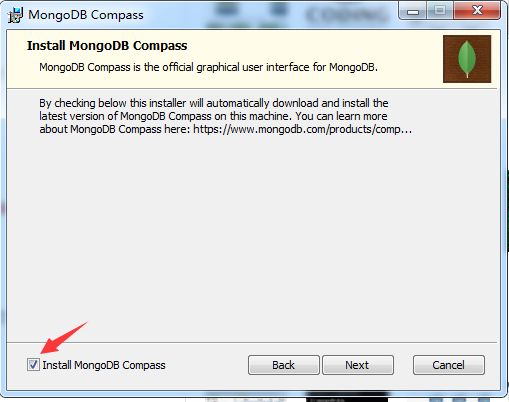
- 夜神模拟器的安装
在夜神模拟器官网下载安装包,然后点击安装即可,配置连接请查看博客夜神模拟器连接电脑配置
二、采用mitmproxy进行抓包处理
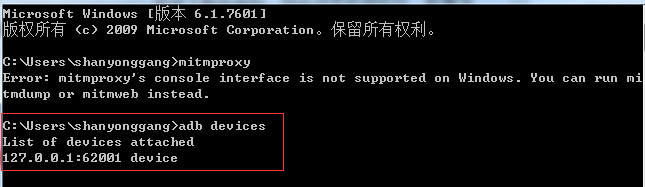
- 首先确保开发环境均已搭建成功同时模拟器已连接到电脑上:
据说配置好开发环境就已经干掉百分之七十的人了,相信自己一定可以的,而且你遇到的问题百分之百能在网上搜到解决方法,只是好多人遇到烦躁的问题就退缩了,我也是慢慢从坑里爬出来的,哈哈!!!继续…
-
然后配置模拟器的端口设置----WLAN,如下图所示:
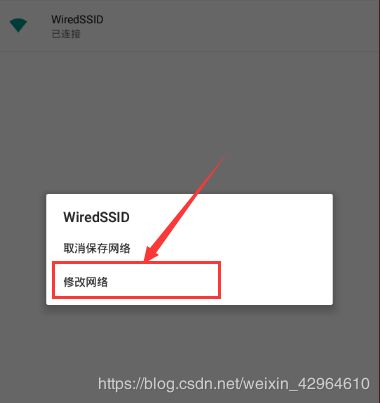
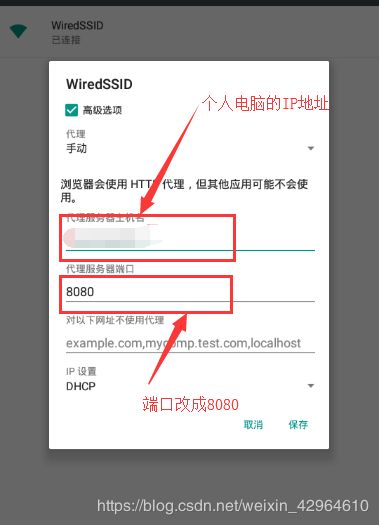
- 运行mitmproxy
在命令中运行mitmproxy报错:
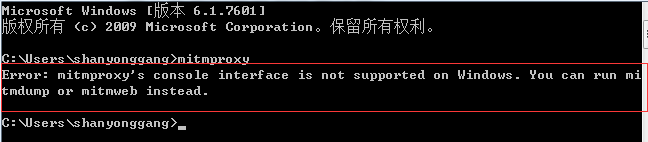
其主要是因为windows不支持mitmproxy,因此我们此采用mitmdump(只能在命令里面看到抓包信息)和mitmweb(可以在网页里看到抓信息)进行抓包处理,本文采用mitmweb进行抓包,在命令行输入:mitmweb,可以看到已经运行了:
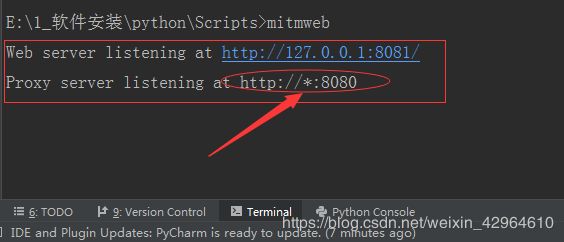
同时打开了个网站:

然后我们打开模拟器里的APP即可看到网站里的抓包信息
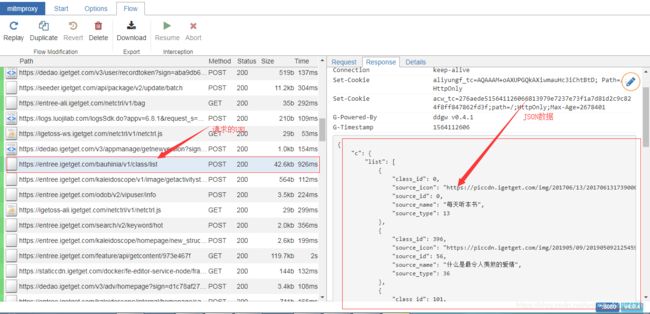
这样我们就获取了APP里的请求数据,接下来我们来实现数据的抓取并存储到数据库中。
三、采用mitmproxy进行抓包爬取得到APP的书籍信息数据
首先在模拟器上安装得到APP,安装方法很简单,下载apk安装包,将其拖拽至模拟器上,则模拟器进行自动解析安装。
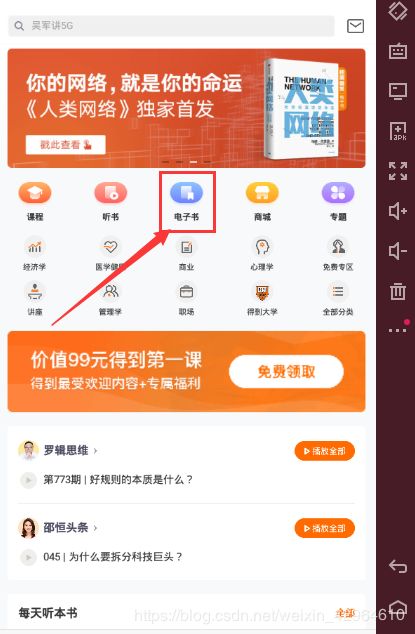
接下来需要我们写Python脚本来实现数据的抓取及存储,先依据第二步分析,打开得到APP,点击进入到电子书书籍列表模块,如下图所示:
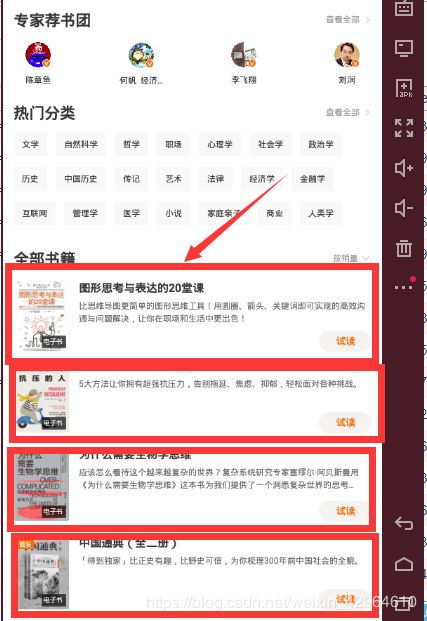
然后查看web页面中的抓包信息,查看mitmweb前端页面显示的抓包数据信息,我们会发现,链接https://entree.igetget.com/ebook2/v1/ebook/list显示可到查看到书籍信息的json数据,记住此URL后续会用到:
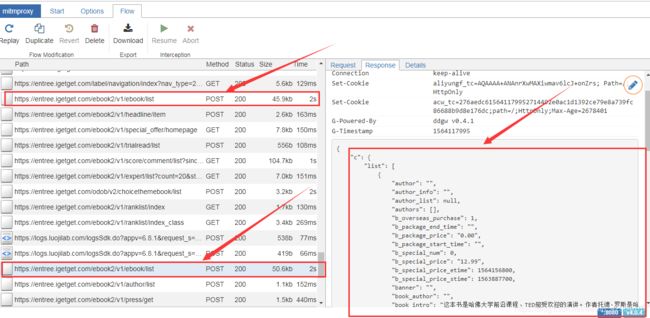
获取到了请求的url链接,接下来我们在pycharm里编写爬虫脚本,以获得数据,根据崔大大的教程编写脚本会如下(博主保存为spider.py):
import json
from mitmproxy import ctx
import pymongo
my_cilent = pymongo.MongoClient("mongodb://localhost:27017/")
my_db = my_cilent["getBook"]
my_collection = my_db["books"]
def response(flow):
global my_collection
url = 'https://entree.igetget.com/ebook2/v1/ebook/list'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'bookName': book.get('book_name'),
'bookIntroduce': book.get('book_intro'),
'currentPrice': book.get('current_price'),
'publishTime': book.get('publish_time'),
}
ctx.log.info(str(data))
my_collection.insert_one(data)
但是通过mitmweb -s spider.py运行后代码会报错:
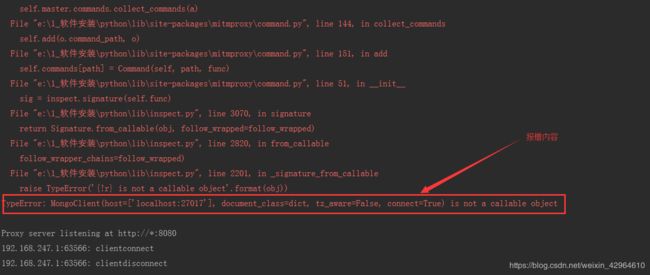
具体原因我也不清楚,但是针对原始代码进行了相应的改动,将连接数据库的三行代码放入到了def函数内,具体代码如下所示:
import json
from mitmproxy import ctx
import pymongo
def response(flow):
my_cilent = pymongo.MongoClient("mongodb://localhost:27017/")
my_db = my_cilent["getBook"]
my_collection = my_db["books"]
# global my_collection
url = 'https://entree.igetget.com/ebook2/v1/ebook/list'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'bookName': book.get('book_name'),
'bookIntroduce': book.get('book_intro'),
'currentPrice': book.get('current_price'),
'publishTime': book.get('publish_time'),
}
ctx.log.info(str(data))
my_collection.insert_one(data)
然后运行mitmweb -s spider.py不显示错误,然后重复上面的步骤:打开app、进入电子书栏目,进入书单列表,手动下拉(目前需要人手动下拉进行数据的刷新,后续可与appium结合起来,实现自动化的下拉),我们可以看到命令栏已经显示我们所需爬取的数据:
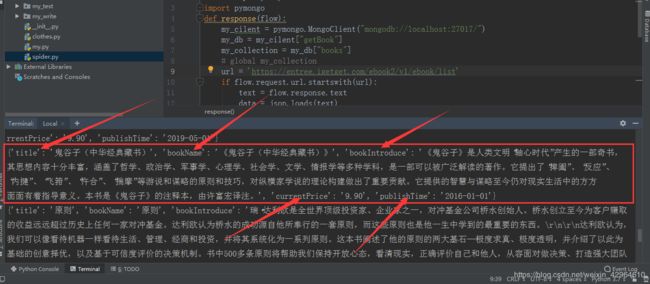
此时我们用可视化工具打开数据库,即可看到数据已保存至数据库中:
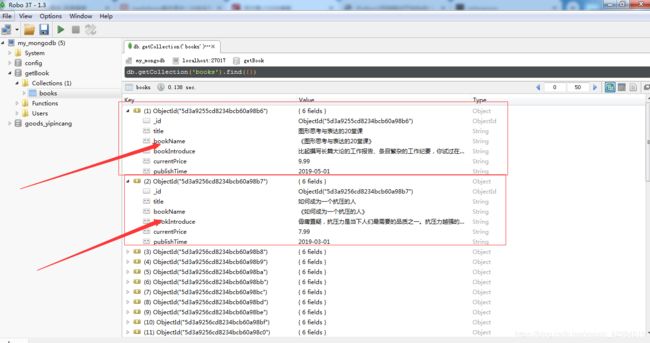
至此,我们采用mitmproxy抓包工具和夜神模拟器就实现了APP数据的简单抓取,目前是需要手动进行下拉刷新,后续采用自动化工具Appium进行数据的自动化抓取。
四、总结
学习爬虫主要参考的崔大大的《Python3网络爬虫开发实战》,本此只是实现了APP数据的简单抓取,算是对APP数据爬虫的入门,针对此文后续还有更多的内容学习:
- mongoDB数据库的操作学习
- mitmproxy的详细使用教程
- Appium 自动化爬虫的学习
- 获取的数据的价值:爬取成功的数据如何发挥数据的价值
- 爬虫框架:学习爬虫框架
- 分布式:实现分布式爬取大量数据
等等!
完结!!!!