松本行弘谈Lisp元编程
Meta, Reflection
“元”这个词,是来自希腊语中表示“在……之间、在……之后、超过……”的前缀词 meta,具有超越、高阶等意思。从这个意思引申出来,在单词前面加上 meta,表示对自身的描述。例如,描述数据所具有的结构的数据,也就是关于数据本身的数据,被称为元数据(Metadata)。再举个比较特别的例子,小说中的角色如果知道自己所身处的故事是虚构的,这样的小说就被称为元小说(Metafiction)1。
1 更常用的中文译法是“后设小说”,也叫“超小说”、“自反小说”。
综上所述,我们可以推论,所谓元编程,就是“用程序来编写程序”的意思。那么,用程序来编写程序这件事有什么意义吗?
像 C 这样的编程语言中,语言本身所提供的数据,基本上都是通过指针(地址)和数值来表现的。在语言层面上虽然有数组和结构体的概念,但经过编译之后,这些信息就丢失了。
不过,“现代派”的语言在运行的时候,还会保留这样一些信息。例如在 C++ 中,一个对象是知道自己的数据类型的,通过这个信息,可以在调用虚拟成员函数时,选择与自己的类型(类)相匹配的函数。在 Java 中也是一样。
像这样获取和变更程序本身信息的功能,被称为反射(Reflection)。将程序获取自身信息的行为,用“看着(镜子中)反射出的身影来反省自己”这样的语境来表达,听起来还挺文艺的呢。
Lisp
Lisp 可以说是这种语言的老祖宗。Lisp 的历史相当悠久,其诞生可以追溯到 1958 年。说起 1958 年,在那个时候其他的编程语言几乎都还没有出现呢。在那个时代已经存在,并且现在还依然健在的编程语言,也就只有 FORTRAN(1954 年)和 COBOL(1959 年)而已了吧。Lisp 作为编程语言的特殊之处,在于它原本并不是作为一种编程语言,而是作为一种数学计算模型设计出来的。Lisp 的设计者约翰·麦卡锡,当时并没有设想过要将其用作一种计算机语言。麦卡锡实验室的一名研究生——史蒂芬·罗素,用 IBM 704 的机器语言实现了原本只是作为计算模型而编写的万能函数 eval,到这里,Lisp 才真正成为了一种编程语言。
Lisp 在编程语言中可以说是类似 OOPArts 2一样的东西。编程语言的历史是由机器语言、汇编语言开始,逐步发展到 FORTRAN、COBOL 这样的“高级语言”的。而在这样的历史中,作为最古老语言之一的 Lisp,居然一下子具备了超越当时时代的很多功能。
2 Out Of Place Artifacts 的缩写,意思是“与时代不符的(使用了先进技术的)遗物”。(注)
1995 年 Java 诞生的时候,虚拟机、异常处理、垃圾回收这些概念让很多人感到耳目一新。从将这些技术普及到“一般人”这个角度来说,Java 的功绩是相当伟大的。但实际上,所有这些技术,早在 Java 诞生的几十年前(真的是几十年前),就是已经在 Lisp 中得到了实现。很多人是通过 Java 才知道垃圾回收的,而 Lisp 早期的解释器中就已经具备了垃圾回收机制。由于在 Lisp 中数据是作为对象来处理的,内存分配也不是显式指定的,因此垃圾回收机制是不可或缺的。于是这又是一项 40 多年前的技术呢。
像虚拟机(Virtual machine)、字节码解释器(Bytecode interpreter)这些词汇,也是通过 Java 才普及开来的,但它们其实是 Smalltalk 所使用的技术。Smalltalk 的实现可以追溯到 20 世纪 70 年代末到 80 年代初,因此这一技术也受到了 Lisp 的影响,只要看看就会发现,Smalltalk 的解释器和 Lisp 的解释器简直是一个模子刻出来的。
数据和程序
凡是看过 Lisp 程序的人,恐怕都会感慨“这个语言里面怎么这么多括号啊”。图 1 显示的就是一个用于阶乘计算的 Lisp 程序,图 2 则是用 Ruby 写的功能相同的程序,大家可以比较一下,括号的确很多呢,尤其是表达式结束的部分那一大串括号,相当醒目。这种 Lisp 的表达式写法, 被称为 S 表达式。不过,除此之外的部分基本上是可以一一对应的。值得注意的有下面几点:
Lisp 编写的阶乘程序:
;;; 通过归纳法定义的阶乘计算
(defun fact(n)
(if (= 1 n)
1
(* n (fact (1- n)))))
(fact 6) ;; => 结果为720Ruby 编写的阶乘程序:
# 这里体现了Lisp和Ruby的相似性
def fact(n)
if n == 1
1
else
n * fact(n - 1)
end
end
fact(6) # => 结果为720Lisp 是通过括号来体现语句和表达式的
Lisp 中没有通常的运算符,而是全部采用由括号括起来的函数调用形式
“1-”是用来将参数减 1 的函数
在 Lisp 中,最重要的数据类型是表(List),甚至 Lisp 这个名字本身也是从 List Processor 而来的。一个表是由被称为单元(Cell)的数据连接起来所构成的(图 3)。一个单元包含两个值,一个叫做 car,另一个叫做 cdr。它们的值可以是对其他单元的引用,或者是被称为原子(Atom)的非单元值。例如,数值、字符串、符号等,都属于原子。
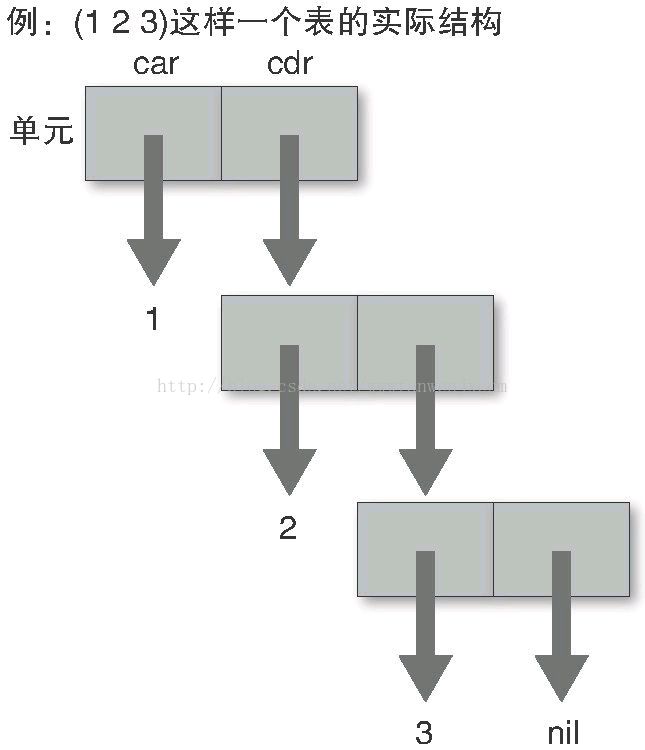
图3 Lisp 的表
S 表达式是用来描述这种表的记法,它遵循下述规则
(语法)。首先,单元是用点对(Dotted pair)来描述的。例如,car 和 cdr 都为数值 1 的单元,要写成下面这样。
(1 . 1)其次,cdr 部分如果是一个表,则省略点和括号,也就是说:
(1 . (2 . 3))应该写成:
(1 2 . 3)然后,如果 cdr 部分为 nil,则省略 cdr 部分。于是:
(1 2 3 . nil)应该写成:
(1 2 3)S 表达式的基本规则就只有上面这些。只要理解了上述规则,就可以通过“括号的罗列” 来想象出实际的表结构。掌握了规则之后再看图 5,应该就能够理解得更加清楚了吧。
那么这里重要的一点是,Lisp 程序是通过 S 表达式来进行表达的。换句话说,Lisp 程序正是通过 Lisp 本身最频繁操作的表的方式来表达的。这意味着程序和数据是完全等同的,在这一点上非常符合元编程的概念,实际上,元编程已经深深融入 Lisp 之中,成为其本质的一部分。
Lisp 程序
Lisp 程序是由形式(Form)排列起来构成的。形式就是 S 表达式,它通过下面的规则来进行求值。
符号(Symbol)会被解释为变量,求出该变量所绑定的值。
除符号以外的原子,则求出其自身的值。即:整数的话就是该整数本身,字符串的话就是该字符串本身。
如果形式为表,则头一个符号为“函数名”,表中剩余的元素为参数3。
3 这是 CommonLisp 等被称为 Lisp-2 系列的 Lisp 中的行为,Scheme 等属于 Lisp-1 系列的语言中,行为是有区别的。(注)
在形式中,表示函数名的部分,实际上还分为函数、特殊形式和宏三种类型,它们各自的行为都有所区别。函数相当于 C 语言中的函数,或者 Ruby 中的方法,在将参数求值后,函数就会被调用。特殊形式则相当于其他语言中的控制结构,这些结构是无法通过函数来表达的。例如,Lisp 中用于赋值的 setq 特殊形式,写法如下:
(setq a 128)假设 setq 是一个函数,那么 a 作为其参数会被求值,而不会对变量 a 进行赋值。setq 并不会对 a 进行求值,而是将其作为变量名来对待,这是 Lisp 语言中直接设定好的规则,像这样拥有特殊待遇的形式就被称为特殊形式。除了 setq 以外,特殊形式还有用于条件分支的 if 和用于定义局部变量的 let。
宏
对 Lisp 的介绍篇幅比预想的要长。其实,我真正想要介绍的就是这个“宏”(Macro)。Lisp 中的宏,可以在对表达式求值时,通过对构成程序的表进行操作,从而改写程序本身。首先,我们来将它和函数做个比较。
首先,我们来看看对参数进行平方计算的函数 square(图 4 上),以及将参数进行平方计算的宏 square2的定义。看出区别了吗?
(defun square (x)
(* x x))
(defmacro square2 (x)
(list '* x x))在函数定义中使用了 defun(def function 的缩写),而在宏定义中则用的是 defmacro,这是一点区别。另外,宏所返回的不是求值的结果,而是以表的形式返回要在宏被调用的地方嵌入的表达式。例如,如果要对:
(square2 2)进行求值的话,Lisp 会找到 square2,发现这是一个宏,首先,它会用 2 作为参数,对 square2 本身进行求值。list 是将作为参数传递的值以表的形式返回的函数。
(list '* x x) ;; => (* 2 2)然后,将这个结果嵌入到调用 square2 的地方,再进行实际的求值。
虽说就 square 和 square2 来说(如果参数没有副作用的话),两种方法基本上没什么区别,但通过使用获取参数、加工、然后再嵌入的技术,只要是遵循 S 表达式的语法,其可能性就几乎是无限的。无论是创建新的控制结构,还是在 Lisp 中创建其他的语言(内部 DSL)都十分得心应手。
由宏所实现的这种“只要在 S 表达式范围内便无所不能”的性质,是 Lisp 的重要特性之一。实际上,包括 CommonLisp 中用于函数定义的 defun 在内,其语言设计规格中有相当一部分就是通过宏来实现的。
那么,我们来想想看有没有只有通过宏才 能实现的例子呢?图 5 的程序是将指定变量内容加 1 的宏 inc。
(defmacro inc (var)
(list 'setq var (list' 1+ var)))“将变量的内容加 1”这样的操作,由于包含赋值操作,用一般的函数是无法实现的。但是,使用宏就可以很容易地实现这样的扩展操作。inc 宏实际使用的例子如图 6 的 (a) 部分所示。
宏的展开结果可以用 macroexpand 函数来查 看。图 6 的 (b) 部分中,我们就用 macroexpand 函数来查看了宏的展开结果,它的展开结果是一个 setq 赋值语句。我们的这个宏非常简单,但如果是复杂的宏,便很难想象出其展开结果会是什么样子,因此 macroexpand 函数对于宏的调试是非常有效的。
;;; (a) inc宏的调用
(setq a 41) ;; 变量a初始化
(inc a) ;; a的值变为42
;;; (b) 查看inc宏的实体
;;; 用macroexpand函数可以查看宏的展开结果
(macroexpand '(inc a))
;;; => (setq a (1+ a))宏的功与过
正如刚才讲过的,Lisp 的宏是非常强大的。要展现宏的强大,还有一个例子,就是 CLOS(Common Lisp Object System)。
在 CommonLisp 第一版中,并没有提供面向对象的功能。在第二版中则在其规格中默认包含了这个名为 CLOS 的面向对象功能,这个功能的实现,是通过宏等手段,仅由 CommonLisp 自身完成的。CommonLisp(及其宏)实在是太强大了,在语言本身没有进行增强的情况下,就可以定义出面向对象功能。而之所以默认包含在语言规格中,只是为了消除因为实现方法不同而产生的不安定因素,将这一实现方法用严密的格式写成了文档而已4。
由于 CLOS 是只用 CommonLisp 内置功能(如宏等)来实现的,因此实际上任何人都可以用不同的方法实现类似的功能,为了让 CLOS 能够跨解释器通用,因此在文档中对其实现方式进行了标准化。当然,并不是所有的 CommonLisp 解释器中的 CLOS 都是仅通过宏来实现的,出于速度方面的优化等考虑,将 CLOS 直接嵌入到解释器中的做法也很常见。
而且,CLOS 并不是只是一个做出来玩玩的玩具,而是一个真正意义上的,拥有大量丰富功能的复杂的面向对象系统,实现了同时代的其他语言到现在为止都未能实现的功能5。
5 CLOS 定义于 1988 年。(注)
例如,Ruby 虽然是一种非常灵活的动态语言,但它的面向对象功能也是用内嵌的方式来实现的,靠语言本身的能力来实现面向对象的功能是做不到的。而这样的功能,Lisp 却仅仅通过语言本身的能力定义了出来,不得不说 Lisp 和它的宏简直强大到令人发指。
既然宏如此强大,那为什么 Ruby 等其他语言中没有采用 Lisp 风格的宏呢?
其中一个原因是语法的问题。Lisp 宏的强大力量,源于程序和数据采用相同结构这一点。然而与此同时,Lisp 程序中充满了括号,并不是“一般的程序员”所熟悉和习惯的语法。
作为一个语言设计者,自己的语言是否要采用 S 表达式,是一个重大的决策。为了强大的宏而牺牲语法的易读和易懂性,做出这样的判断是十分困难的。
在没有采用 S 表达式的语言中,也有一些提供了宏功能。例如 C(和 C++)中的宏是用预处理器(Preprocessor)来实现的,不过,这种方式只能做简单的字符串替换,无法编写复杂的宏。以前,美国苹果公司开发过一种叫做 Dylan 6的语言,采用了和 Algol 类似的(比较一般的)语法,但也对宏的实现做出了尝试,不过由于诸多原因,它还没有普及就夭折了。
6 Dylan(名称来自 DYnamic LANguage 的缩写)是一种多范式跨平台编程语言,由苹果公司于 20 世纪 90 年代初开始开发,后来项目被终止,只发布了一个技术版本。后来 Harlequin 公司和卡内基梅隆大学的团队分别发布了 Dylan 的 Windows 和 Unix 版本,目前由开源社区 Open Dylan 运营维护。
另一个难点在于,如果采用了宏,程序的解读就会变得困难。
宏的优点在于,包括控制结构的定义在内,只要在 S 表达式语法的范围内就可以实现任何功能,但这些功能也仅限于增强语言的描述能力和提供内部 DSL(特定领域语言)而已,此外并没有什么更高级的用法了。不过,反过来说,这也意味着如果不具备宏所提供的新语法的相关知识,就很难把握程序的含义。如果你让 Lisp 高手谈谈关于宏的话题,他们大概会异口同声地说:“宏千万不能多用,只能在关键时刻用一下。”说起来,元编程本身也差不多是这样一个趋势吧。
不过,作为 Ruby 语言的设计者,依我看,宏的使用目的中很大的一部分,主观判断大约有六七成的情况,其实都可以通过 Ruby 的代码块来实现。我的看法是,从这个角度来说,在 Ruby 中提供宏功能,实际上是弊大于利的。然而,追求更强大的功能是程序员的天性,我也经常听到希望 Ruby 增加宏功能的意见,据说甚至有人通过修改 Ruby 的解释器,已经把宏功能给搞出来了。唔……
元编程的可能性与危险性
在 Ruby 和 Lisp 这样的语言中,由于程序本身的信息是可以被访问的,因此在程序运行过程中也可以对程序本身进行操作,这就是元编程。使用元编程技术,可以实现通常情况下无法实现的操作。例如,Ruby on Rails 的数据库适配器 ActiveRecord 可以读取数据库结构,通过元编程技术在运行时添加用于访问数据库记录的方法。这样一来,即便数据库结构发生变化,在软件一侧也没有必要做出任何修改。
再举一个例子,我们来看看 Builder 这个库。Builder 是用于生成标记语言(Mark-up language)代码的库,应用示例如代码所示。
require 'builder'
builder = Builder::XmlMarkup.new
xml = builder.person {|b|
b.name("Jim")
b.phone("555-1234")
}#
=> Jim 555-1234 在图7的示例中,person 和 name、phone 等标签是作为方法来调用的,但这些方法并不是由 Builder 库所定义的。由于 XML(Extensible Markup Language,可扩展标记语言)中并没有事先规定要使用哪些标签,因此在库中对标签进行预先定义是不可能的。于是,在 Builder 库中,是通过元编程技术,用钩子(Hook)截获要调用的方法,来生成所需的标签的。
无论是 ActiveRecord 的示例,还是 Builder 的示例,都通过元编程技术对无法预先确定的操作进行了应对,这样一来,未来的可能性就不会被禁锢,体现了语言的灵活性。我认为,这种灵活性正是元编程最大的力量。
另一方面,元编程技术如果用得太多,编写出来的程序就很难一下子看明白。例如,在 Builder 库的源代码中,怎么看也找不到定义 person 方法的部分,如果没有元编程知识的话,要理解源代码就很困难。和宏一样,元编程的使用也需要掌握充分的知识,并遵守用量和用法。