高级数据结构之猝死攻略(二)
接上一篇《高级数据结构之猝死攻略(一)》https://blog.csdn.net/wydyd110/article/details/82190471
坚持不易,奖励一个小白脸来养养眼。

目录
3 Trie树
3.1 等长字符树——26叉Trie
3.2 不等长的字符树,加 “ * ” 标记
3.3 压缩trie树
3.4 二叉Trie树
3.5 后缀树
3.6 后缀数组 (Suffix Array)
4. 应用
4.1 Trie树应用于搜索提示服务
4.2 Trie树应用于路由转发
4.3 后缀树的应用
4.3.1 精准字符串匹配(ESM)
4.3.2 最长重复子串(LRS)
4.3.3 最长公共子串(LCS)
4.3.4 DNA污染问题
4.3.5 遇难者身份识别问题
4.3.6 回文问题
3 Trie树
Trie ,来源于retrieval检索。
Trie树:字典树,单词查找树,前缀树。
下图是一棵由“北京”、“北京大学”、“北平”、“大便”、“便捷”五个中文词构成的 Trie 树。

根节点不包含字符,除根节点外每一个节点都只包含一个字符
从根节点到叶子节点,路径上经过的字符连接起来,构成一个词。
而叶子节点内的数字代表该词在字典树中所处的链路(字典中有多少个词就有多少条链路),具有共同前缀的链路称为串。
Trie 树中任何一个完整的词,都必须是从根节点开始至叶子节点结束。
3.1 等长字符树——26叉Trie
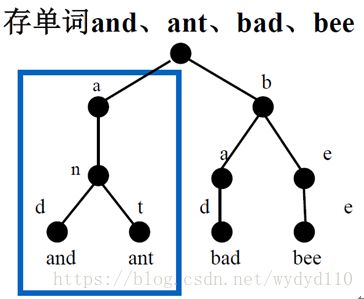
一棵子树代表具有相同前缀的关键码的集合
“an”子树代表相同前缀an-具有的关键码集合{and,ant}
注意:该字符树中,所有的单词都是等长的。即任何一个单词都不是其他单词的前缀。
3.2 不等长的字符树,加 “ * ” 标记

该树中,存在某个单词是另一个单词的前缀,需要加 " * " 来表示结尾。
3.3 压缩trie树
存储单词 an, and, ant, bad, bee
压缩前 压缩后
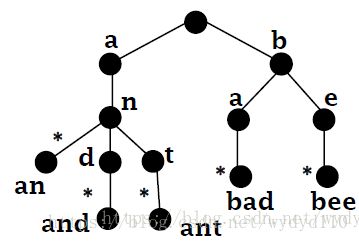
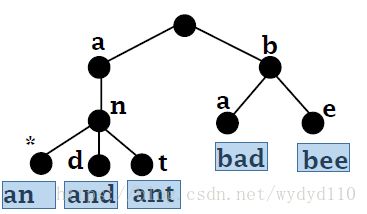
对靠近叶节点的进行压缩。因为叶节点负责存储信息,中间节点起到索引的作用。
3.4 二叉Trie树
• 每个字母或数值采用的二进制编码来表示
• 编码只有0和1
例:存储 2(000010)、5(000101)、9(001001)、17(010001)、41(101001)、45(101101)、63(111111)
按空间折半划分

按编码划分
压缩前 压缩后
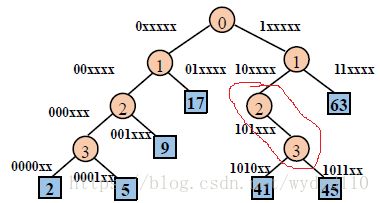
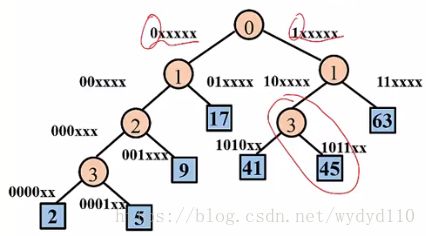
0则在左分支继续划分
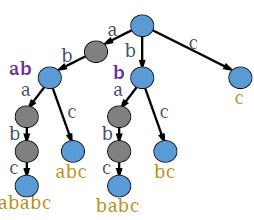
3.5 后缀树
ababc的非空后缀子树:ababc, babc, abc, bc, c
压缩前 压缩后

3.6 后缀数组 (Suffix Array)
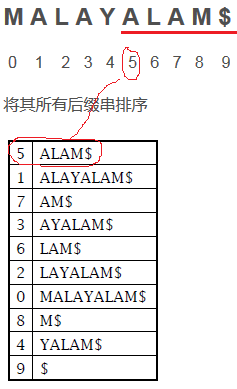

构建后缀树
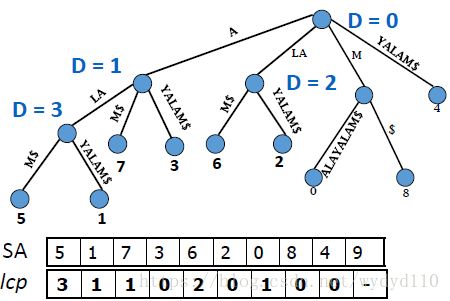
构建后缀树的算法:UKK
构建后缀数组的算法:DC3
时间复杂度均为O(k),其中k为字符串的长度
4. 应用
4.1 Trie树应用于搜索提示服务

如果是Google,Baidu这种大型搜索系统,或者京东淘宝这种电商系统,搜索提示的调用量是搜索服务本身调用量的几倍,因为你每输入一个键盘,就要调用一次搜索提示服务,这算得上是个标准的高并发系统吧?那么它是怎么实现的呢?
可能很多人脑子里立刻出现了缓存+哈希的系统,把搜索的搜索提示词存在Redis集群中,每次来了请求直接Redis集群中查找Key,然后返回相应的value值就行了,完美解决,虽然耗费点内存,但是空间换时间嘛,也能接受,这么做行不行?恩,我觉得是可以的,但有人这么做吗?没有。
这种搜索提示的功能一般用trie树来做,耗费的内存不多,查找速度为O(k),其中k为字符串的长度,虽然看上去没有哈希表的O(1)好,但是少了网络开销,节约了很多内存,并且实际查找时间还要不比缓存+哈希慢多少。此外,Trie相比Hash具有“路径”信息,于是可以很方便的把有联系的Node遍历出来,这样就很方便的能够实现诸如“联想词”“纠错”“补全”等功能,这是Hash表不具备的。
(参考自《坑:缓存 + 哈希 = 高并发?》—吳YH堅http://blog.jobbole.com/109905/)
4.2 Trie树应用于路由转发
试想我们有上百台提供服务的机器组成的集群,彼此提供的服务各不相同,前端一个请求过来,其中url是http://yiduowen.com/xxx/yyy/zzz 如何进行调度呢?如果使用Trie,可以直接略过前缀“http://yiduowen.com/”,只需要查询xxx/yyy/zzz就能定位到Node,而Node的Data就是能够提供该服务的IP List,取其一,进行转发代理。
此外还有
- IDE代码补全和提示
- 搜索框的高频词补全比如百度主页
- 文本字典序排序
- 浏览器地址栏浏览历史补全
4.3 后缀树的应用
4.3.1 精准字符串匹配(ESM)
生物应用
识别DNA序列中的起始密码子ATG(RNA的转录翻译起始点)
问题定义
求长度为m的字符串Q在长度为n的字符串S中出现的位置。

4.3.2 最长重复子串(LRS)
生物应用
DNA序列中的重复子串,可以相邻,也可以分离,常被用来作为“标记位点”。许多疾病也是由于具有某种结构的重复序列引起的。
解决方案

.............................................................................................................

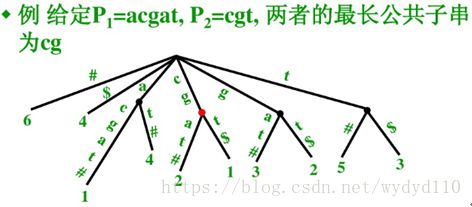
4.3.3 最长公共子串(LCS)
生物应用
发现多个序列的同源性。
问题定义

解决方案

.............................................................................................
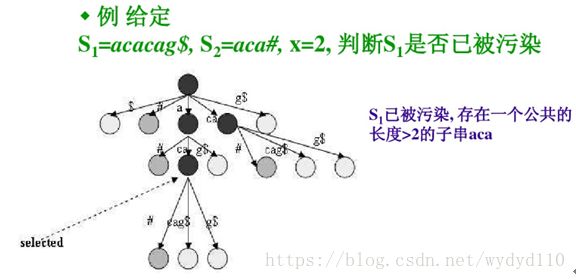
4.3.4 DNA污染问题
生物应用
如何准确的测定DNA序列?(难道恐龙更接近人?)
问题定义
给定一个新测序的DNA序列S1和一个来自可能的污染物的DNA序列S2,若S2中的某个子串出现在S1中,则S1可能已经被污染了。
解决方案

.................................................................................................
4.3.5 遇难者身份识别问题
生物应用
识别遇难者(如:在战争中死亡的士兵)的身份
问题定义
给定一个长度为m的字符串Q和一个字符串数据库,查找该字符串数据库中包含Q的字符串
解决方案

4.3.6 回文问题
生物应用
特殊位点识别(如:限制性酶剪切位点)
问题定义


(来源于《生物信息学概论讲义》https://wenku.baidu.com/view/b74e9cec0975f46527d3e1d9.html)