基于pandas、matplotlib、pyecharts的人工智能相关职位招聘市场数据分析
pandas是python中的数据分析库,matplotlib、pyecharts是python中的数据可视化库。
容大教育人工智能班数据分析阶段实战项目:人工智能相关职位数据分析
小组成员:雷坤、韦民童、李波、陶宇
项目周期5天,数据分析为第2天的需求。
0.下载数据集
小组成员利用爬虫收集各大招聘网站的人工智能相关岗位信息,小组分工:
| 姓名 | 网站 | 网址 |
|---|---|---|
| 雷坤 | 中华英才网 | www.chinahr.com |
| 李波 | 智联招聘 | www.zhaopin.com |
| 韦民童 | 拉勾网 | www.lagou.com |
| 陶宇 | 前程无忧51job | www.51job.com |
本文中使用的数据集是前程无忧51job网站爬虫收集的职位信息。
数据集下载链接: https://pan.baidu.com/s/1XyKcm_KlV5jO6aQSQMWb7A 密码: wyar
1.观察数据
1.1解压压缩文件
将压缩文件解压,如下图所示:
1.2打开jupyter notebook
在人工智能职位信息_前程无忧51job文件夹同级目录下打开powershell
powershell输入命令并运行:jupyter notebook
1.3新建dataAnalysis.ipynb文件

新建ipynb文件完成后重命名,重命名按钮位置如下图所示:

1.4.查看数据
import pandas as pd
df = pd.read_csv('人工智能.csv', engine='python', encoding='utf8')
print(df.shape)
print(len(df.columns), df.columns)
df.head()
上面一段代码的运行结果如下:

2.数据处理
2.1 删除空行
print('删除空行前共有%d行' %len(df))
df = df.dropna(how='all')
print('删除空行后共有%d行' %len(df))
上面一段代码的运行结果如下:
删除空行前共有14383行
删除空行后共有14304行
从上面的运行结果可以看出,一共删除了14383-14304=79行。
3.绘制词云图
3.1 词频统计
利用jieba库进行中文分词,jieba.cut方法的返回值数据类型为生成器generator。
import pandas as pd
import jieba
df = pd.read_csv('人工智能.csv', engine='python', encoding='utf8')
allText = ' '.join(df.jobRequirement.dropna().map(str.lower))
top200_keyword = pd.value_counts(list(jieba.cut(allText))).iloc[:200]
print(top200_keyword.iloc[:50])
通过上面一段代码运行可以查看分词后统计词频排名前50的关键词。
本文作者通过分词统计词频和手动添加关键词的方法形成关键词词库。
3.2 下载人工智能关键词词库
此词库是本文作者观察数据后根据现实情况编辑的词库,只有43个关键词。
读者绘制词云图时可以自行尝试多添加关键词。
关键词词库下载链接: https://pan.baidu.com/s/1o-yrnZe6cyqJaYTuLcR1HA 密码: q6yi
下载后将词库放到人工智能职位信息_前程无忧51job文件夹中。
3.3 编写代码
利用str对象的count方法可以统计字符串中某个子字符串出现的次数,这个方法效率非常高。
from pyecharts import WordCloud
import pandas as pd
def drawWordCloud(allText):
with open('keyword.txt', encoding='utf-8') as file:
keyword_list = [k.strip() for k in file.readlines()]
count_list = []
for keyword in keyword_list:
count_list.append(allText.count(keyword))
top20_keyword = pd.Series(count_list, index=keyword_list).sort_values(ascending=False).iloc[:10]
print(top20_keyword)
wordcloud = WordCloud(width=900, height=600)
wordcloud.add('', keyword_list, count_list, word_size_range=[20,100])
return wordcloud
df = pd.read_csv('人工智能.csv', engine='python', encoding='utf8')
allText = ' '.join(df.jobRequirement.dropna().map(str.lower))
print('字符串allText变量的长度:',len(allText))
drawWordCloud(allText)
上面一段代码的运行结果如下:
字符串allText变量的长度: 7164775
人工智能 13262
培训 12148
算法 6389
大数据 5486
科技 5249
计算机 5145
互联网 4954
上海 3597
北京 3139
机器学习 2681
dtype: int64
绘制的词云图:

分析结论:
人工智能培训很火热,工作中对算法要求多,与大数据相关度高。
4.全国城市的岗位需求量分析
4.1 数据处理
招聘信息当中的工作地点信息在tags字段中,该字段以“|”为分隔符,包含工作地点workPlace、工作经验要求experienceRequirement、学历要求educationRequirement、招聘人数、发布时间publishTime这5个字段。
工作地点workPlace以“-”为分隔符,包含市和区。
import pandas as pd
df = pd.read_csv('人工智能.csv', engine='python', encoding='utf8')
workPlace = df.tags.dropna().map(lambda x:x.split('|')[0].strip())
city = workPlace.map(lambda x:x.split('-')[0])
region = workPlace.map(lambda x:x.split('-')[1] if len(x.split('-'))>1 else '')
4.2 统计地区岗位需求量
city_jobCount = city.value_counts(ascending=False).iloc[:10]
city_jobCount
上面一段代码的运行结果如下:
上海 3027
北京 1835
深圳 1647
广州 1259
杭州 1158
成都 553
武汉 545
南京 448
苏州 406
石家庄 290
Name: tags, dtype: int64
4.3 数据可视化-柱形图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.figure(figsize=(10,6))
city_jobCount.plot(kind='bar')
plt.show()
上面一段代码的运行结果如下:

4.4 分析结论
从上面的运行结果可以看出,人工智能相关职位上海需求量最高,之后分别是北京、深圳、广州、杭州、成都等城市。
5.上海地区的岗位需求量分析
5.1 统计上海各区岗位需求量
import pandas as pd
df = pd.read_csv('人工智能.csv', engine='python', encoding='utf8')
workPlace = df.tags.dropna().map(lambda x:x.split('|')[0].strip())
city = workPlace.map(lambda x:x.split('-')[0])
region = workPlace.map(lambda x:x.split('-')[1] if len(x.split('-'))>1 else '')
shanghai_region = region[city=='上海']
region_count_series = shanghai_region.value_counts().drop([''])
region_count_series
上面一段代码的运行结果如下:
浦东新区 579
徐汇区 347
嘉定区 266
杨浦区 224
静安区 162
闵行区 148
宝山区 131
普陀区 106
黄浦区 103
松江区 99
奉贤区 77
长宁区 72
虹口区 63
青浦区 54
金山区 28
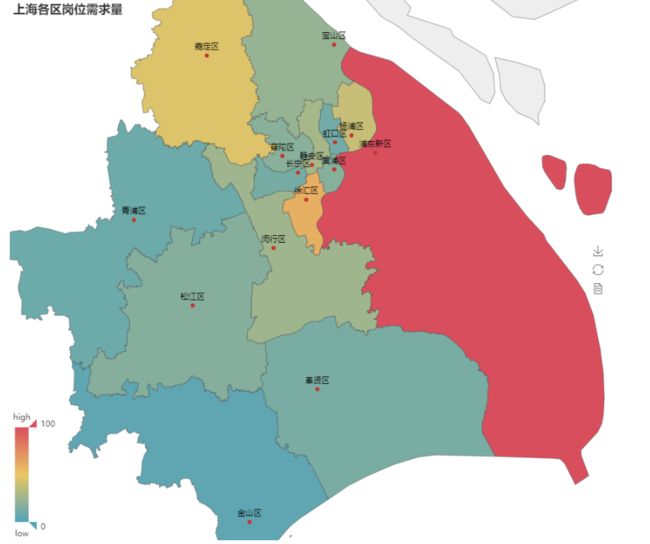
5.2 数据可视化-热力图
安装pyecharts库绘制热力图需要的中国城市地图库,cmd命令:pip install echarts-china-cities-pypkg
from pyecharts import Map
map1 = Map('上海各区岗位需求量', width=900, height=800)
attr = region_count_series.index
value = region_count_series.values/region_count_series.max() * 100
map1.add('', attr, value, maptype='上海', is_visualmap=True, is_label_show=True)
map1
上面一段代码的运行结果如下:
5.3 数据可视化-饼图
from pyecharts import Pie
attr = region_count_series.index
value = region_count_series.values
pie = Pie('上海各区岗位需求占比', title_pos='center', width = 900, height=600)
pie.add('', attr, value, is_label_show=True, legend_pos='left', legend_orient="vertical",)
pie
上面一段代码的运行结果如下:

5.4 分析结论
从上面的运行结果可以看出,上海市的人工智能相关职位需求量浦东新区最高,之后分别是徐汇区、嘉定区、杨浦区、静安区等。
6.学历要求分析
该数据分析部分由李波完成,使用pyecharts库绘制饼图。
数据集为智联招聘网站爬虫收集的数据。
数据集下载链接: https://pan.baidu.com/s/1W5F9OZph3PnunAahj68fUw 密码: bf8t
6.1 定义绘制饼图函数
定义drawPie函数,需要传入2个参数,第1个参数series是传入的可迭代对象,第2个参数title是图的标题。
from pyecharts import Pie
import pandas as pd
def drawPie(series, title):
series = pd.Series(series)
count_series = series.value_counts(ascending=False)
count_series = count_series[count_series/count_series.sum()>0.01]
pie = Pie(title, title_pos='center', width=900, height=600)
pie.add("", count_series.index, count_series.values,
radius=[30, 75],
is_label_show=True,
legend_orient='vertical',
legend_pos='left')
return pie
6.2 数据处理和可视化-饼图
df = pd.read_excel('人工智能_李波.xls')
df.columns = [k.strip() for k in df.columns]
drawPie(df.educationRequirement, '学历要求占比饼图')
上面一段代码的运行结果如下:
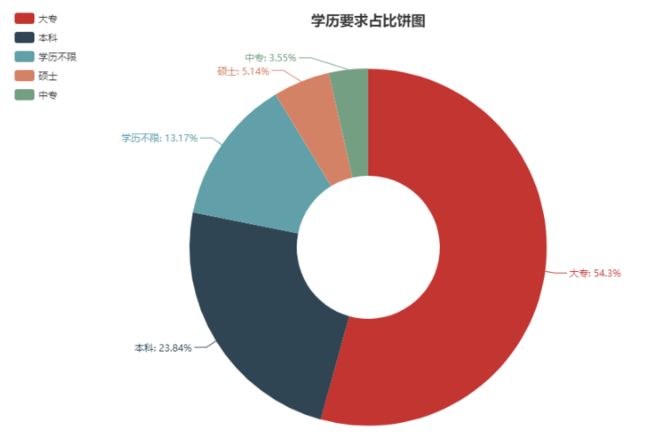
6.3 分析结论
人工智能相关岗位的学历要求占比最大的为大专,明显违背实际情况。
造成此结果的可能原因如下:
1.智联招聘网站对于招聘信息的审核不严格。
2.智联招聘网站搜索的返回结果混乱,不能给求职者带来有效信息。
3.没有做删除非人工智能岗位信息条目的数据清洗操作。
6.4 前程无忧51job网站对比
项目第4天重新进行了数据处理
前程无忧51job网站经过数据处理的数据集下载链接: https://pan.baidu.com/s/1KGvJ8ZtN37kL5y05-dC-Kg 密码: wa92
import pandas as pd
df = pd.read_csv('51job.csv')
drawPie(df.educationRequirement, '学历要求占比饼图')
上面一段代码的运行结果如下:

通过上面2个网站的对比分析,51job网站的职位学历要求更符合人工智能岗位的实际情况。
6.5 拉勾网对比
下面代码成功运行的前提是6.1节的画饼图函数drawPie先运行。
拉勾网数据集下载链接: https://pan.baidu.com/s/1nxaVTsPKttgleZ5oY1139w 密码: 7cm6
在数据集文件夹中编辑代码文件,代码如下:
keyword_list = ['NLP', '机器学习', '人工智能', '人脸识别', '深度学习',
'算法研究员', '图像识别', '无人驾驶', '语音识别']
fileName_list = [k+'.csv' for k in keyword_list]
df_list = [pd.read_csv(open(fileName, encoding='utf8')) for fileName in fileName_list]
df_all = pd.concat(df_list)
df_all = df_all.reset_index(drop=True)
drawPie(df_all['学历要求'].str.strip('及以上'), '学历要求占比饼图-拉勾网')
上面一段代码的运行结果如下:

对比分析结论:
1.51job网站的职位学历要求更符合人工智能岗位的实际情况。
2.拉勾网的职位学历要求更高,可以在拉勾网找较高标准的工作。
7.人工智能相关职位的薪资对比
数据集是拉勾网人工智能相关职位招聘信息,即6.5节的数据集。
7.1 数据处理
import pandas as pd
keyword_list = ['NLP', '机器学习', '人工智能', '人脸识别', '深度学习',
'算法研究员', '图像识别', '无人驾驶', '语音识别']
fileName_list = [k+'.csv' for k in keyword_list]
df_list = [pd.read_csv(open(fileName, encoding='utf8')) for fileName in fileName_list]
salary_list = [df['薪资区间'].dropna() for df in df_list]
salary_list2 = [salary[salary.str.contains('-')] for salary in salary_list]
salary_list3 = [salary.map(lambda x:x.lower().replace('k','000')) for salary in salary_list2]
7.2 查看数据
for salary in salary_list3:
print(len(salary))
上面一段代码的运行结果如下:
445
897
448
450
447
448
899
235
445
7.3 数据转换
获取各种人工智能相关职位薪酬的较低值、较高值、平均值。
对于列表推导式、匿名函数要比较熟练才能看懂下面的代码。
Series对象的map方法需要传入一个参数,参数数据类型为函数对象,返回值数据类型也为Series。
Seies对象的quantile方法可以得到从小到大排序位置的数,例如quantile(0.5)得到从小到大排序50%位置的数,即中位数;quantile(0.25)得到从小到大排序25%位置的数,即下四分位数;quantile(0.75)得到从小到大排序75%位置的数,即上四分位数。
import numpy as np
salaryLow_list = [salary.map(lambda x:int(x.split('-')[0])).quantile(0.5) for salary in salary_list3]
salaryHigh_list = [salary.map(lambda x:int(x.split('-')[1])).quantile(0.5) for salary in salary_list3]
salaryAvg_list = [salary.map(lambda x:np.average([int(k) for k in x.split('-')])).quantile(0.5) for salary in salary_list3]
7.4 数据可视化-柱状图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.figure(figsize=(18,8))
min_x = range(1, 42, 5)
max_x = range(2, 43, 5)
avg_x = range(3, 44, 5)
plt.bar(min_x, salaryLow_list, color='b', label='薪酬较低值')
plt.bar(max_x, salaryHigh_list, color='r', label='薪酬较高值')
plt.bar(avg_x, salaryAvg_list, color='g', label='薪酬平均值')
plt.xticks(range(2, 58, 5), keyword_list, fontsize=16)
plt.xlabel('人工智能相关职位', fontsize=12)
plt.ylabel('薪酬', fontsize=20)
plt.legend(fontsize=16)
plt.show()
上面一段代码的运行结果如下:

7.5 取薪酬平均值作图
import numpy as np
salaryLow_list = [salary.map(lambda x:int(x.split('-')[0])).mean() for salary in salary_list3]
salaryHigh_list = [salary.map(lambda x:int(x.split('-')[1])).mean() for salary in salary_list3]
salaryAvg_list = [salary.map(lambda x:np.average([int(k) for k in x.split('-')])).mean() for salary in salary_list3]
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.figure(figsize=(18,8))
min_x = range(1, 42, 5)
max_x = range(2, 43, 5)
avg_x = range(3, 44, 5)
plt.bar(min_x, salaryLow_list, color='b', label='薪酬较低值')
plt.bar(max_x, salaryHigh_list, color='r', label='薪酬较高值')
plt.bar(avg_x, salaryAvg_list, color='g', label='薪酬平均值')
plt.xticks(range(2, 44, 5), keyword_list, fontsize=16)
plt.xlabel('人工智能相关职位', fontsize=12)
plt.ylabel('薪酬', fontsize=20)
plt.legend(fontsize=16)
plt.show()
上面一段代码的运行结果如下:

从上面的运行结果可以看出,采用数据的平均值和中值作图相差不大,比较具有可信度。
结论如下:
1.9种人工智能相关职位中,NLP的薪资待遇最高
2.深度学习、算法研究员的薪资待遇也不错
3.人工智能相关职位的较低薪资在1.5万左右
4.人工智能相关职位的平均薪资在2万左右
5.人工智能相关职位的较高薪资在3万左右
8.项目经理心得
1.分配给组员的需求要明确
2.表格名字段名统一
3.说明文档需要配图