基于论文分析Google的张量处理器TPU
本文转载自微信公众号CPUinNUDT,由《基于论文分析Google的张量处理器TPU》及《基于论文分析Google的张量处理器TPU(补充)》两篇文章合并而成,如有相关问题,请与原作者联系。
源起
2017年度的国际计算机体系结构年会(ISAC-2017)尚在投稿阶段时,类似“Google将公布其张量处理器的细节”的小道消息就在不停发酵。几天前,即2017年4月6日,Google在自家网站上公开了论文初稿,让大众可以在会议之前提前了解其中细节。由此Google、TPU和NN加速又再次成为热门话题。
NN加速在CPU@NUDT是一个极有历史感的话题,不光能够列举出20年前的项目方案,还能催促一份写了半年的内部技术报告。由于相关公开资料足够丰富,足以替代类似神经网络硬件加速器ASIC方案的专门章节。在公开讨论三天之后,我们特意以附件中该论文译本为基础,蹭一下讨论热度。
论文点评:
风格:
这篇论文并非是ISCA的传统论文风格。记得曾经有久远的数据分析和讨论,说明ISCA这样的体系结构界会议依赖于模拟器和原型,以创新设计(或脑洞大开、或幸运的拍对脑袋)著称。通常ISCA上的想法到可能被工业界实践量产大约要10年左右。
从这个意义上看,这篇TPU论文更符合HPCA上形成传统的工业界专题论文。即讨论的技术和研究实践在强调创新性的同时,包含工业界在量产案例中的取舍、折中极其原因分析。由于TPU已经是2016年公开过的设计,10多页的论文篇幅也不符合固态电路会议的风格。
启示:
虽然论文已经总结了很多技术亮点,并以“圆柱”一书的对话讨论风格提醒业界在讨论相关问题中的陷阱和现有设计缺憾。但那毕竟是属于论文作者的,而不属于围观群众。因此还是在开头汇总讨论下论文的启发或者心理安慰。
- 底层硬件设计,特别是以处理器设计为代表的研发工作门槛并未降低。但由于无论专用和通用处理器都需要得到最终用户的认可,考虑软件的真实需求,软硬件协同开发可能进一步提升设计门槛。(即:硅码农还是有市场需求的)
- 相比于神经网络模型、软件框架和应用的当前的进化速度,传统ASIC半定制或者全定制的开发周期和速度难以加速。但仍然有可能保持专用设计一定的寿命,并通过性能模型评估确定改进方案。(即:研发还是老套路,但会更困难。要硅马跑得快又少吃草或最好不吃草的情况只会恶化)
- 真实应用的部署和数据收集是必需的,而且有极强的说服力,当然最终目的是获得处理器目标用户的认可。(即:总有人能做出叫好又叫座的设计,有足够资源配合可能性更高些)
- 在关注论文的时候,更应该关注专利分析。在论文发布之前,甚至在初步阅读论文时很多评论表示,TPU设计没有细节,连照片都盖着散热篇。但仔细阅读论文能看到,Google在2015年就提交了相关的论文申请,在Alpha GO下棋的时候就可以通过专利局网站看到相关专利了。(即:先进商业公司和上市公司的知识产权保护,购并和调查并非是装样子的。)
补充:
公开论文中参考文献已经包含的详细的内容,但也引用的未来的文献,例如2018年将出第6版的《计算机系统结构:量化设计方法》[Hen18]。在这里要特别补充6个Google公司专利,供想关注例如:浮点单元与矩阵单元关系,DMA书传输等细节的同仁查证。
- [Ros15a] Neural Network Processor. Patent Application NO.62/164,931, US20160217368A1, WO2016186801A1
- [Ros15b] Computing Convolutions Using a Neural Network Processor. Patent Application NO.62/164,902, US20160342889A1, WO2016186811A1
- [Ros15c] Prefecting Weight for a Neural Network Processor. Patent Application NO.62/164,981, US20160342892, WO2016186810A1
- [Ros15d] Rotating Data for Neural Network Computation.
Patent Application NO.62/164,908, US20160342893, WO2016186826A1 - [Tho15] Vector Computing Unit in a Neural Network Processor. Patent Application NO.62/165,022, US20160342889, WO2016186813A1
- [You15] Batch Processing in a Neural Network Processor. Patent Application NO.62/165.020, US20160342890, WO2016186823A1.
不足:
由于其主页不可见,对这一公司的指责都快成为ZZ正确的举动了。但对于传统的工业界论文,仍然补充一句,性能模型不可获得(或者当前不可获得),对众多要毕业的Ph.d帮助是有限的。毕竟N.P Jouppi在HP参与开发并开源的众多工具是众多研究人员攒数据的利器。
对于初稿而言,尚不存在的参考文献,以及在28MB和24MB之间变换的片上存储容量,都不算是不足。
从这里才正式开始的引言:
神经网络加速大致可以分为四种形式(CPU、GPU、FPGA、ASIC)。已经成型的CPU和DSP(数字信号处理器,而非领域专用处理器)通过以扩展SIMD为主要加速方式。已有生态对NN加速是一把双刃剑,虽然CPU在上有开发环境丰富的优势,但也受限于传统通用化设计和兼容化要求。FPGA有灵活适应DNN算法变迁,能效比高等优点。但FPGA建立完善加速计算环境与研究平台需要软硬件配合实现,技术门槛要高于以Nvidia GPU为代表非可重构芯片。在成本上,平价FPGA芯片的计算能力远远不足,而高端高性能FPGA芯片售价远远超过相近计算能力的GPU。如果一个公司有足够的人力和财力资源,在FPGA上验证过的设计,如果具有较大规模的用量,通常都会寻求定制ASIC作为第二阶段方案。
虽然ASIC具有研发周期长,NRE费用高等风险,但作为硬件定制的最彻底方案,可以实现设计师的各类PPA目标,当然其过程与结果也包含了无尽的折中。
超大的附件《译文》1-8:
在数据中心中对张量处理器进行性能分析
In-Datacenter Performance Analysis of a Tensor Processor
许多体系结构设计师相信在“成本–能耗–性能”上的主要提升方式必然来自于领域定制硬件(domain specific hardware)。Google的这篇论文评估了称为张量处理器(TPU: Tensor Processing Unit)的定制ASIC芯片。该芯片从2015年起开始部署在Google的数据中心中,用于加速神经网络的推理过程(译者注:本文中TPU的目标应用不包含训练过程。但从行文来看,并非TPU被特意设计为不能用于训练)。TPU的核心是一个64K的8位矩阵乘单元阵列和片上28MB的软件管理存储器,峰值计算能力为每秒92TOP/S。与CPU和GPU由于引入了Cache、乱序执行、多线程和预取等造成的执行时间不确定相比,TPU的确定性执行模型能够满足Google神经网络应用上99%响应时间需求。CPU/GPU的结构特性对平均吞吐率更有效,而TPU针对响应延迟设计。正是由于缺乏主流的CPU/GPU硬件特性,尽管拥有巨大数量的矩阵乘单元MACs和大容量的片上存储,TPU的芯片面积相对较小同时保持低功耗。Google的研究人员将TPU与部署在相同数据中心的服务器级的Intel Haswell CPU和Nvidia K80 GPU对比。测试负载为基于TensorFlow框架的高级描述,应用于实际产品的神经网络应用(包括MLPs,CNNs和LSTPs),代表了Google数据中心承载的95%推理需求。虽然在某些应用上利用率比较低,TPU平均比CPU/GPU快15倍到30倍,性能功耗比TOPS/W指标更高达30到80倍。进一步,在TPU上采用GPU常用的GDDR5存储器,能使得性能TOPS指标再翻三倍,而能效比指标TOPS/W将比GPU高70倍,达到CPU的200倍。
附件第1部分: 神经网络介绍
在云环境中的巨大数据集,以及支撑云的众多计算资源协同开启了机器学习的文艺复兴。特别,深度神经网络(DNN: Deep Neural Networks)实现了比传统方法在语音识别错误率上降低30%的突破,成为这一领域近20年来最大成就 [Dea16];并从2011年开始在图像识别大赛中将错误率从26%降低到3.5%[Kri12][Sze15][He16];并在围棋大赛中击败人类世界冠军[Sil16]。
神经网络(NN: Neural Networks)目标是类似大脑的功能,并基于简化的人工神经进行设计:即带权重多个输入之和的非线形函数(例如在max(0, value))。众多的人工神经被组织为层次,一层的输出顺序成为下面一层的输入。而DNN的“深度”来源于层次数量突破原有少数几层,主要的原因是在云平台上的大数据集允许用额外层次和更大规模来构建更加精确的模型,以不活更高级别的模式或概念,同时GPU提供的足够的计算能力开开发这些模型。
神经网络的两个主要阶段是训练(Training或者学习Learning)和推理(inference或者预测Prediction),也可以对应于开发和产品阶段。开发人员选择网络的层数和神经网络类型,并且通过训练来确定权重。实际上,当前的训练几乎都是基于浮点运行,这也是GPU为何如此流行的原因之一。一个称为量化(quantization)的步骤,将浮点数转换为很窄仅使用8个数据位的整数,对推理过程通常是足够了。8位的整数乘法比IEEE 754标准下16位浮点乘法降低6倍的能耗,占用的硅片面积也少6倍;而整数加法的收益是13倍的能耗与38倍的面积[Dal16]
当前的有三类流行的神经网络:
- 多层感知机(MLP: Multi-Layer Perceptrons):每一个新层次都是之前层次所有输出的(全相连)加权和的非线性函数,权值重用。
- 卷积神经网络(CNN: Convolutional Neural Networks): 每一个后继层次都是之前层次中在空间邻近输出子集的加权和的一组非线形函数,权值也重用;
- 循环神经网络(RNN:Recurrent Neural Networks):每一个后续层次是输出加权和与之前状态的一组非线性函数。最流行的RNN是长短期记忆(LSTM: Long Short-Term Memory)。LSTM的关键在于确定哪些状态应该忘记,而哪些状态应该传递到下一个层次。权值在时序步骤上被重用。
表1中,上述三种神经网络NN中给出了两个例子—代表了google数据中心中95%的NN推理负载—也作为这篇论文的测试程序Benchmarks。通常以TensorFlow[Aba6]来写得话,这些NN只需要100到1500行代码来描述,非常短。作者选取的测试程序仅选择了主机上所运行大型应用的一小部分,整个应用可能是数千到上百万行C++代码。这些应用通常直面用户并参与交互,因此有比较严格的响应时间限制。
表1: 6种NN应用(每类2个应用)代表了TPU上95%的负载。从左到右每一行依次是:NN的名字;代码行数;NN中不同网络类型和层数(FC是全互连层,Conv是卷积层,Vector是自解释层,Pool是在TPU上完成非线性尺寸缩减的池化层)。这些流行的TPU应用是在2016年7月选定的。一个DNN是RandBrain[Cla15];一个LSTM是GNM翻译的子集[Wu16];一个CNN是Inception;而另一个CNN是DeepMind的AlphaGo[Sil16][Jou15]
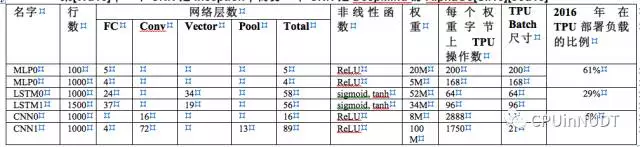
每一个模型需要5M到100M的权重(表1中的第9行),访问这些数据消耗了相当的时间与能量。为了分摊这一开销,在推理或者训练的过程中,单个用例在一个Batch批量过程中权重被重用,从而提高性能。
这篇论文描述和评价的张量处理单元,并且将其在推理过程中的性能和功耗与对应的CPUs和GPU对比,预期主要的关注点包括:
- 推理应用通常更关注于响应时间而不是吞吐率,因为他们通常与用户直接交互。
- 由于延迟限制的结果,K80 GPU在推理过程中利用率很低,并且仅比HaswellCPU快一点点。
- 虽然芯片尺寸很小,功耗很低,TPU上具备的MAC单元数量是K80 GPU上MAC数量的25倍,片上存储器容量是3.5倍。
- TPU在推理阶段比K80 GPU和Haswell CPU快15倍到30倍。
- 6个NN应用中的4个在TPU上是存储受限型的;如果修改TPU的设计,使之具备和K80 GPU相同的存储系统,将会比GPU和CPU快30倍到50倍。
- TPU的性能功耗比(每瓦性能)是对比产品的30倍到80倍;改进后具有类似K80存储器的TPU能效比可以到70倍到200倍。
- 虽然大量的体系结构被用于加速卷积神经网络CNN,但他们在Google的数据中心应用负载中仅占据5%的比例。
附件第2部分:TPU的来源,体系结构和实现
早至2006年,Google已经讨论在数据中心中部署GPU,FPGA或者定制的ASIC芯片。当时的结论是:极少有在专门硬件上运行的应用可以利用google丰富强大的数据中心能力,并且很难用很小代价进行性能提升。在2013年话风改变了,规划中的DNN可能流行到使数据中心的计算需求翻倍。因此Google启动了一个高优先级的项目:为推理投产一个定制的ASIC芯片(并购买市售的GPU用于训练)。目标是在GPU的基础上将成本—性能提高10倍。根据这一任务授权,TPU在仅仅15个月内完成了设计、验证[Ste15]和在数据中心内被部署。(由于篇幅的限制,TPU更多的细节可以看[Ros15a],[Ros15b],[Ros15c],[Ros15d],[Tho15]和[You15]。
与其选择与一个CPU紧密集成,为了降低可能对部署造成的拖延,TPU被设计为通过PCIE总线连接的协处理器,这使得它能够像GPU一样直接插入到现有服务器中使用。进一步,为了简化硬件设计和调试,由服务器主机向TPU发送它需要执行的指令,而不是由TPU自行取指。因此,在这一原则上,TPU更像是一个浮点协处理器(FPU: Floating Point Unit)而不是GPU。
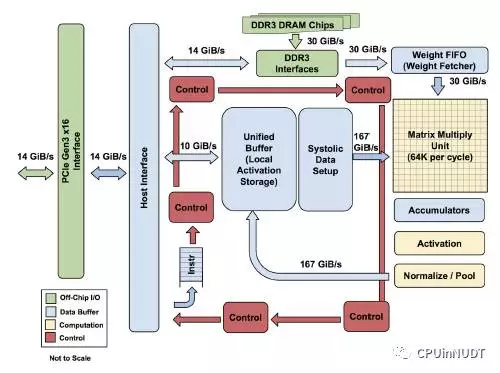
图1 TPU模块图。主要的计算部件是右上角的黄色矩阵乘单元。其输入是蓝色的权重数据队列FIFO和蓝色的统一缓冲(UB:Unified Buffer),而其输出是蓝色的累加器(Acc: Accumulators)。黄色的激活单元在累加之后执行非线性函数,然后数据返回统一缓冲。
设计目标是在TPU上运行整个推理过程,以减少与主机CPU的交互。并且TPU要足够灵活以能够符合2015年以及之后的神经网络NN需求,而不是仅满足2013年的NN需求。图1显示了TPU的模块图。
TPU的指令由主机通过PCIE Gen3的16 lane总线送入一个指令缓冲。所有的内部模块通常用一个256字节宽(即1024位宽)的通路相连。从右上角开始,矩阵乘单元(Matrix Multiply Unit)是TPU的中心。它包含256x256个MAC部件,每一个能够执行有符号或者无符号的8位乘加操作。16位结果被收集并传递到位于矩阵单元之下,4MiB的32位累加器。4MiB代表的是4096,但实际是256个32位累加器。矩阵单元每个时钟周期产生1个256元部分和。选择4096作为缩写开头是未来标记为了达到峰值性能(请参考第四部分)每个字节上需要进行的操作约是1350,设计师将这个放大到2048,并进一步翻倍,从而在按照峰值性能运行时,编译器可以使用双缓冲策略。
当混合使用8位权重和16位激活(或者反过来),矩阵乘单元以一半速度计算。而当两者都使用16位时,以1/4的速度运行。每个时钟周期,矩阵单元读取并写回256个值,同时执行一次矩阵乘或者一次卷积。矩阵单元保持一个64KiB的权重数据片段,另外还一个来自双缓冲(以隐藏将数据片段移入所需要的256个周期)。这一单元是为密集矩阵设计的。由于部署时间限制的原因,稀疏(矩阵)的体系结构支持被省略。稀疏性在未来设计中具有高优先级。
矩阵单元技术所需的权重分阶段从片外8GiBDRAM读入到片上的权重队列(片外DRAM被称为权重存储器WeightMemory。对于推理,权重数据是只读的;8GiB能够同时支持许多活跃的模型)。权重队列深度为4个数据片段。中间结果被保存在24MiB的片上统一缓冲UnifiedBuffer,也作为矩阵单元的输入。一个可编程的DMA控制器在CPU主机内存和统一缓冲中传输数据。

图2 TPU晶圆的布局规划。形状与图1中一致。亮(蓝)色的数据缓冲占据晶圆面积的37%,亮(黄)色的计算部分占据30%,中(绿)色I/O部分占10%,而暗(红)色的控制仅占2%。控制部分在CPU或者GPU中都比TPU更大(并且也更难设计)。
图2显示了TPU晶圆的布局规划。24MIB的统一缓冲几乎占据的1/3的硅片面积,而矩阵乘单元占据了1/4,因此数据通路占了接近2/3的硅片面积。选择24MiB容量部分是为了匹配矩阵单元在硅片上的间距尺寸,由于极短的开发周期,部分也是为了简化编译器(参照第7部分)。控制仅占2%。图3显示了在印制电路板上的TPU,可以向SATA硬盘一样的插入现有服务器中。

图3 TPU印制电路板。可以插入服务器的一个SATA盘位中,但卡使用的是PCIEGen3x16连接。
由于指令是通过相对较慢的PCIE总线传递的,TPU指令遵循CISC传统,包含一个重复域。这些CISC指令的平均每指令周期值(即CPI: clock Cycles Per Instruction)典型是10到20。总体而言约有一打指令,但关键指令是这5条:
- 读主机存储Read_Host_Memoy从CPU主机存储器中读入数据到统一缓冲;
- 读权重Read_Weights从权值存储器中读入权值数据到权值队列,作为矩阵单元的输入;
- 矩阵乘/卷积MatrixMultiply/Convolve驱动矩阵单元来执行一次矩阵乘或一次卷积,将统一缓冲中的数据计算为结果,输出给累加器。矩阵操作抽取统一缓冲中不定尺寸B*256输入,使之和256x256的常数权值输入相乘,并且产生一个B*256的输出,需要B个流水的周期来完成。
- 激活Activate执行人工神经的非线性函数,可选包括ReLU, Sigmoid等等。其输入是累加器结果,函数结果输出到统一缓冲。它同时也执行卷积所需要的池化操作,这使用晶圆上的专门硬件,正如它与非线性函数逻辑相连是一样的。
- 写主机存储器Write_Host_Memory将数据从统一缓冲写入到CPU主机存储器。
其他的指令包括可选的主机存储器读/写,组配置,两种版本的同步,中端主机,调试标签,空指令和停机。CISC风格的矩阵乘指令有12个字节,其中3个字节是统一缓冲地址;2个字节是累加器地址;4个字节都是长度(有时候对卷积是2维);剩余的是操作码和标记位。
TPU微体系结构的设计哲学是保持矩阵单元在忙碌状态。TPU为这些CISC指令使用了4级流水线,而每条指令都在一个分离的流水段执行。原来计划是通过与矩阵乘指令的重叠来隐藏其他指令的执行。为此目的,Read_Weights指令遵循了解耦访问/执行设计哲学[Smi82],因此该指令可以在将地址送出之后,但在权值从权值存储器取到之前就完成。如果输入激活或者权值数据没有准备好,矩阵单元将会暂停。
TPU并没有清晰的流水线重叠框图,因为其CISC指令可以占据一个流水站数千个时钟周期,而不像传统的RISC流水线一样只在每个流水站上占据一个时钟周期。当一个网络层次的激活操作,必需在下一个网络的矩阵乘开始之前完成时,就会产生有趣的现象;看起来和传统CPU中的“延迟槽”类似,矩阵单元必需等待明确的同步操作,以确保统一缓冲重点的数据以及安全准备好。
由于读取一个大尺寸SRAM耗费的功耗超过算术逻辑,矩阵单元通过减少统一缓冲对读和写的脉动执行(systolicexectution)[Kun80][Ram91][Ovt15b]来节约能耗。图4显示从左边流入的数据,而权值则从上部载入。一个给定的256元素乘-累加操作以对角波diagonal wavefront的方式通过矩阵。权值被预先载入,并与一个新数据库中第一组数据的先行波产生效应。控制与数据被流水化,以造成如下错觉:256个输入被立刻读入,并且他们立刻更新256个累加器对应的存储区域。从正确性的角度来看,软件完全不知道矩阵乘单元的脉动特性,但从性能的角度看,软件需要关心单元的延迟。
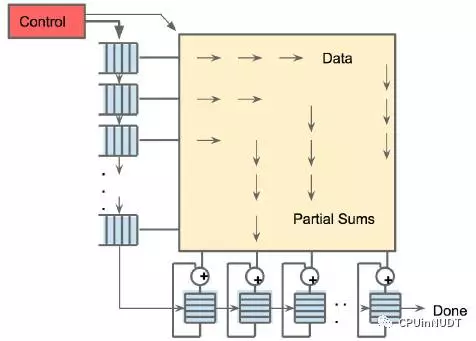
图4 矩阵乘单元的脉动数据流。给软件的错觉是每个256字节的输入都立刻读入,并且立即更新每个256累加器的RAM
TPU的软件堆栈必需和那些为CPU和GPU开发的软件兼容,从而使得应用能够迅速的移植到TPU上。运行在TPU上的那部分应用通常用TensorFlow书写,并被编译为面向GPU或者TPU上运行API[Lar16]。类似GPU,TPU软件堆栈被拆分为用户空间的驱动程序和内核空间驱动程序。内核驱动程序是轻量化的,并且仅处理存储管理和中断。其设计目标是长时间的稳定性。用户空间驱动程序则频繁改变。它负责建立并控制TPU执行,按照TPU的顺序要求重整数据格式,将API调用翻译为TPU指令,并将这些指令转化为应用二进制。用户空间驱动程序在它第一次计算一个模型的时候对其进行编译,将程序映像缓存,并将权重映像写入到TPU的权值存储器;第二次和接下来的所有计算都以全速运行。TPU完全按照从输入到输出的逻辑运行大多数NN模型,以最大化TPU的计算和I/O时间比值。一次计算通常完成一层逻辑,具有重叠的执行允许矩阵乘单元隐藏大部分非关键路径操作。
表2: 评测服务器使用Haswell CPU,K80 GPU和TPU。Haswell有18个核心,而K80具有13个SMX流处理簇。图10评价了功耗。低功耗的TPU使得其的机架密度要优于高功耗的GPU。每个GPU有8GiB的DRAM作为权值存储。GPU没有使用Boost Mode(见Sec.8)。SECDEC和非Boost模式将K80的带宽从240降低到160。非Boost模式和单晶圆对比双晶圆性能将K80得峰值TOPs从8.7降低到2.8(*TPU晶圆面积不超过Haswell晶圆的一半)

附件第3部分CPU,GPU和TPU平台
在表1中的6个生产力型程序是这篇论文的测试负载。如上所述,这6个应用代表了数据中心内TPU上95%的应用。具有讽刺意味的是,在生产力机器上部署和评测流行的小规模DNN,例如AlexNet或者VGG比较困难。但测试所用的一个CNN是源于被广泛使用的Inception V2。
测试平台式是2015年TPU部署之后可获得的主流服务器级计算机系统。这意味着强制各个平台包含至少对内部SRAM的SECDED保护,以及类似TPU外部DRAM的保护。因此排除了某些型号选择,例如Nvidia的Maxwell GPU。出于Google的购买与部署现状,这些平台也很难做成配置敏感的机器,基本杜绝了为赢得测试而人为组装一个平台的尴尬。
表2给出了配置选择。传统的CPU服务器服务器是来自Intel的双路18核Haswell处理器。这一平台同时也构成了GPU和TPU的主机平台。Haswell以Intel的22nm工艺生产。CPU和GPU都非常巨大的芯片晶圆尺寸,差不多600mm2。
2.3GHz的CPU主频并不包含超频模式,因为在数据中心的NN应用上这种情况非常罕见。依赖于程序是否使用AVX指令,Haswell有不同的时钟频率,在Google的NN应用中这很常见。超频模式下(程序中避免使用AVX)更高的主频也意味着并非所有核心被使用。因此,另外一个Google数据中心中超频模式很少出现的原因是其应用通常使用全部核心,更何况这些核心可以运行其它的数据中心任务来填满可能空闲核心。
GPU加速器是Nvidia的K80。每个K80卡上有两个芯片晶圆,并且提供对内部存储器和外部DRAM的SECDED保护。Nvidia宣称“K80能够急剧降低数据中心的成本,以更少、更强有力的服务器来提供应用性能”[Nvi16]。在2015年神经网络研究人员大多使用K80,而到2016年9月K80也是基于云平台的主要GPU加速选择。
在所选的测试平台服务器上可以安装4块GPU卡包含8个K80芯片。超频模式可以将主频增加到875Mhz。Haswell上的超频模式由硬件控制,并且在芯片温度急剧上升之前只能短暂的簇发运行于这一模式。但是K90的超频模式由软件驱动程序控制[Nvi15],因此持续时间至少是成百上千毫秒。因此对于K80的供电和散热必需按照其总是在超频模式来准备,否则芯片可能过热。而对于所选择的平台,开启Boost模式将强制减少单台服务器中K80卡的数量,反而导致成本上升。因此GPU的Boost模式被关闭。这也限制了GPU上可获得的峰值带宽和操作性能(参见表2说明)。在论文Sec.8部分评估了开启超频模式情况。
由于每个测试平台上的芯片晶圆数量不同(可能是2、4、8),作者通常用单芯片晶圆归一化数据(图5-8,图10-11,以及表3,4和6),但也会不时展现整个系统的数据(图9)。作者希望数据区分的足够清晰。
附件第4部分:性能:天花板,响应时间和吞吐率
为了展示3类处理器上6个应用的性能,作者采用的高性能计算(HPC: High Performance Computing)中的天花板性能模型[Wil09]。这一简单的可视模型并非完美,但可以获得对性能瓶颈的洞察。这一模型背后的假设是应用不会完全装载到高速缓存中,因此应用要么是计算受限型的,要么是存储受限型的。对于HPC,Y轴是每秒浮点操作数性能,因此峰值计算性能构成了天花板的平坦部分。X轴以每个DRAM字节上的浮点操作数目来衡量操作密集程度。存储带宽指标是每秒字节数(bytesper second),也是天花板倾斜指标,因为(FLOPS/sec)/(FLOPS/Byte)=(Bytes/sec),如果没有足够的操作烈度,一个程序就是存储带宽受限的,位置也就在倾斜的天花板之下。
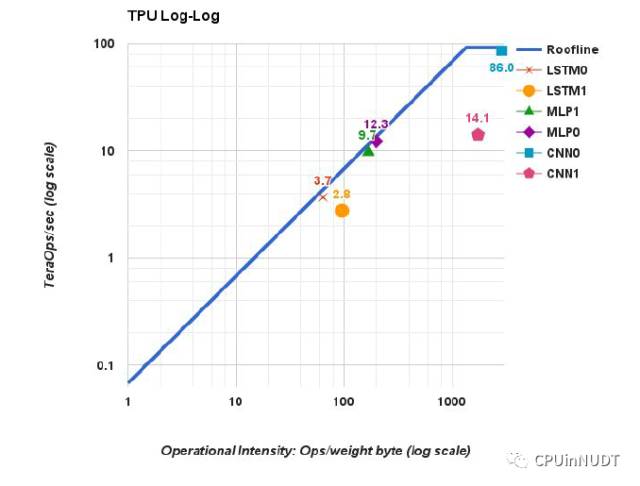
图5 TPU芯片的天花板。它的屋脊在很靠右的位置,即对每一个从权值存储器中获得字节上进行1350个操作
一个应用中实际每秒操作数与天花板之间的距离展示了在不增加操作烈度下进一步性能调优的可能收益;当然如何能够增加操作烈度(例如缓冲模块)可能带来更大的好处。
在TPU上使用天花板模型时,一旦量化计算NN应用,首先用整数操作替换浮点操作。由于NN应用中的权值通常超出片上存储器容量,第2个改变是重新定义操作烈度为每个读入权值字节上的整数操作数目(见表1中的第10行)。
图5显示了单个TPU芯片上双对数坐标系的天花板模型。TPU有很长的倾斜部分,这部分的操作烈度表示性能受限于存储带宽而不是峰值计算性能。6个应用中的5个处于屋檐之下:MLPs和LSTP是存储受限的,而CNN是计算受限的。CNN1虽然有很高的操作烈度,但性能只有14.1 TOPS,而CNN0性能有86 TOPS。
表3解释了CNN1中发生了什么,用性能计数器给出了TPU操作的部分视图。在CNN1中TPU花费了接近一半的时钟周期来运行矩阵操作(第1行第7列)。在所有这些活跃周期中,65536个MAC单元中仅有接近一半保存了有效权值,因为CNN1中某些层次特征深度较浅。约有36%的时钟周期被用于等待权值数据载入到矩阵单元,在4个全相连层次中仅有32的操作烈度(看Section8中的最后谬论)。这还留着约19%的周期没有在矩阵相关计数器中被解释。由于TPU上的重叠执行机制,并没有这些周期确切计数,但已经可以看到23%的周期由于流水线中的写后读相关暂停,而1%的周期用于等待输入在PCIE总线上传输。
表3: 基于硬件性能技术观察的NN负载上TPU性能限制因素。第1,4,5和6行总和是100%的矩阵单元活动时间。第2和3行将矩阵单元中的64K个进一步区分为在活跃周期中是否包含有用权值。TPU中的计数器并不能解释何时产生第6行的矩阵单元暂停;第7行与第8行的计数器值显示了两种可能的原因,包括写后读流水线相关和PCIE总线上的的输入暂停。第9行(TOPS)是基于生产力代码的测量结果,而其它行是性能计数器测量结果,因此它们并非完美一致相符。主机服务器的开销不包含在表中。MLP和LSTP是存储带宽受限的,而CNN不是,CNN1的结果在正文中进一步解释

图6和图7显示了单颗Haswell芯片和单颗K80芯片的天花板。所有6个NN应用都远远比图5中的TPU离天花板更远。响应时间是主要原因。许多这类NN应用是终端面向用户服务的一部分。研究人员已经展示如下结果:在响应时间上的些微增加将导致用户更少使用相关服务[Sch09]。因此,虽然训练可能没有确定的响应时间限制,推理却会有。也就是说,推理更追求延迟,而非吞吐率[Pat04]。

图6 Intel Haswell CPU的天花板,屋脊转折在13操作/字节,比图5要靠左非常多。LSTM0和MLP1在Haswell上比K80快,而其他DNN则是反过来
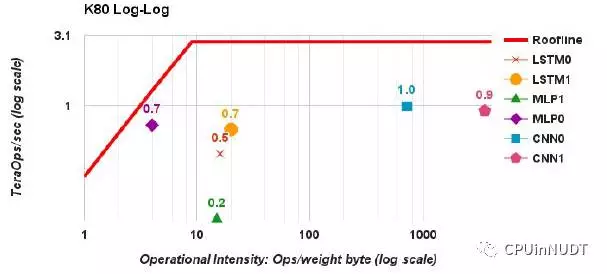
图7 NvidiaK80 GPU的天花板,更高的存储带宽是的屋脊转折在每个权值操作上9操作的位置,比图6还要靠左。由于响应时间的限制DNN要比天花板低很多(参见表4)
表4显示了限制99%的7ms响应时间对MLP0在Haswell和K80上的影响[Dea13],应用开发人员提出了这一需求。(每秒的推理数以及7毫秒的响应延迟包含了服务器主机和加速器两部分的时间)。在响应时间满足的情况下,CPU和GPU分别达到最高吞吐率的42%和37%。因此,虽然CPU和GPU有更大的吞吐率潜力,但如果不满足响应时间限制,这一能力被浪费了。这一限制对TPU也有效,但在表4中80%更加接近MLP0吞吐率的上届。与CPU和GPU相比,单线程的TPU没有精巧复杂的微体现结构,即没有消耗更多的晶体管和能量来提高平均使用性能而不是99%的推理案例;没有Cache,分支预测器,乱序执行,多处理,前瞻预取,地址合并,多线程,现场切换等等。极简主义在领域专用处理器是一种美德。
表4:99%响应时间和MLP0的单芯片吞吐率在不同批量下的变化。最长可允许的延迟是7毫秒。对GPU和TPU而言最大MLP0的吞吐率受限于主机服务器开销。更大的批量尺寸增加了吞吐率,但正如正文中解释的,这会导致响应时间超出限制,因此CPU和GPU都必须选择效率更低,更小的批量尺寸(16而不是200)

表3显示了TPU性能,但没有考虑主机服务器的运行时间,这一部分可以主机独立运行应用以及和TPU进行交互。表5显示了第二部分的时间,但第一部分很难获取。排队理论显示长输入队列提高吞吐率—通过保证计算机不暂停—但是压缩了响应时间。因此,大部分应用保持他们的输入队列为空。然而,TPU本身无法测量这部分时间,因为TPU这时也以及进入暂停状态等待CPU完成其自身应用处理,或者CPU自身也由于输入队列空而陷入暂停。
表5: 主机CPU与TPU的交互时间按照TPU执行时间的比例来折算(从TPU性能计数器获取)。这一部分是CPU和TPU在PCIE总线上的通信时间,不包含CPU独自运行应用但不与TPU交互的部分。如正文所解释的,很难用TPU来测量是否CPU是暂停或者在独立运行应用

表6给出了单个芯片相对推理性能的底线,用两个加速处理器与主机服务器的开销与纯CPU对比。倒数第2行显示了6个应用相对性能的几何平均,K80芯片是Haswell芯片的1.1倍,而TPU芯片则是14.1倍。因此TPU芯片性能比GPU快13.2倍。图8给出了相对速度的直观显示
表6:K80 GPU芯片和TPU芯片相对于CPU在神经网络NN负载上的性能。GM和WM分别是几何平均与加权平均(采用表1中真实的应用混合比例)。GPU和CPU的相对性能包含了主机服务器的开销。MLP和CNN在TPU上运行得很好。表4解释了TPU可以使用更大的批量规模尺寸并且同样也能够满足时间限制,即增加每字节上的操作数(表1),或者等效的,减少每操作所需要的存储访问。同样CNN天然具有更多的权重重用,并因此每字节上的操作数更高。所以TPU上较低的存储带宽并没有严重影响CNN的性能。

回想体系结构设计师在不知道程序混合比例的情况下使用几何平均[Hen18]。在本文研究中,设计师知道混合比例(表1)。表6中的最后一行的加权平均使用真实的混合比例,GPU性能提升增加到1.9倍,TPU增加到29.2倍,因此TPU芯片要比GPU芯片快15.3倍。
附件第5部分:性能成本,总拥有成本和能效比
当以成千上万的数量购买计算机时,性能成本(cost-performance)压倒性能。数据中心最佳的成本指标是总拥有成本(TCO:Total Cost of Ownership)。Google为大宗芯片购买付出的实际购买成本依赖于和相关公司的谈判。由于商业上的原因,作者不能发表相关的价格信息,或者任何能够推理出相关内容的数据。但是,功耗与TCO是相关的,而作者能够发布每台服务器的功耗数据,因此在论文中作者用能效比数据(性能/瓦performance/Watt)作为性能/TCO的代理数据。在这个部分,将比较整个服务器的性能而不是单个芯片,也就是表2中“测试服务器”那几列中的数据。

图8 将图5-7合并到一张对数关系图。星形是TPU,三角形是K80,而圆形是Haswell。所有的TPU星形都在其它两种类型的天花板之上
图9显示了K80GPU和TPU相对于Haswell CPU的能效比的几何平均和加权平均。作者展示两种不同的性能/功耗比技术方法。第一种(“总和”)在计算GPU和TPU性能功耗比的时候包含主机CPU服务器的功耗。第二种(“增量”)在前者中减去主机CPU服务器的功耗。
对于总性能功耗比,K80服务器是Haswell的1.2倍到2.1倍。对于增量性能功耗比,当主机服务器功耗省略是,K80服务器的性能提升为1.7倍到2.9倍。
TPU服务器的总性能功耗比是Haswell的17倍到34倍,也就是K80服务的14倍到16倍。相对的增量性能功耗比—也是Google公司定制ASIC的理由—TPU比CPU高41倍到83倍,也比GPU的性能功耗比高25倍到29倍。

图9 GPU服务器(蓝色条柱)和TPU服务器(红色条柱)相对于CPU服务器的能效比(功耗/瓦TDP),以及TPU服务器相对于GPU服务器的能效比。TPU’是改进的TPU(第7部分)。绿色条柱显示了与CPU服务器对比的性能,而薰衣草紫色部分显示了与GPU服务器对比性能。总和指标包含了主机服务器的功耗,而增量数据不包含。GM和WM是几何与加权平均数据。
附件第6部分:能量平衡
热设计功耗(TDP:Thermal Design Power)影响配置功耗的开销,因为必需提供足够的能源和散热以应对峰值功耗的硬件需求。但是,用电成本基于在一天当中不停变换负载的平均开销。[Bar07]发现服务器100%忙碌的时间少于10%,并提出能量平衡(energyproportionality)的主张:服务器应该消耗与其承担执行的负载相称的能量。上一章节中的功耗估计数据基于在Google数据中心中常见TDP分数。
可以看到TPU具有最低的功耗—每颗芯片总计118W(TPU+Haswell/2)以及增量48W(图10中的TPU)–但是它的能量平衡最差:在10%负载下,TPU应用了在100%负载下功耗的88%。(较短的设计周期导致没有保护任何节能特性。)毫无意外,Haswell是组中能量平衡最好的:在10%负载下,CPU消耗了100%负载功耗的56%。K80接近于CPU,也优于TPU,在10%负载下消耗100%负载功耗的66%。LSTM1虽然不是计算密集型应用,体现了相似的性能:在10%负载下,CPU使用全部功耗的47%,GPU使用78%,而TPU使用94%。
如果在CPU主机附加上加速处理器,运行CNN0是服务器功耗会如何变化?当GPU和TPU在100%负载下,CPU主机服务器在GPU情况下使用52%的总功耗,而在TPU情况下使用69%的功耗(CPU在于TPU配合时做更多工作,因为此时比与GPU配合时运行更快。)结果是,Haswell服务器加上4颗TPU增加功耗少于20%,但运行CNN0速度比仅有Haswell处理服务器快80倍(4个TPU对比2颗CPU)

图10 CNN0的Watts/Die数据作为目标平台利用率从0%到100%变化。总GPU功耗数据为红色线,PU数据为桔色线,而增量功耗数据分别为绿色和紫色。(蓝色线为Haswell,即CPU服务器的总功耗)。加速服务器具有2颗CPU芯片与8颗GPU芯片或者4颗TPU芯片,因此通过除以2、8或4来分别进行功耗归一化处理。
附件第7部分:评价可能的TPU设计选择
类似FPU,TPU协处理器是相对容易评价的微处理器体系结构,因此作者为6个目标应用建立了性能模型。表7显示了性能模型与硬件性能计数器的差异,平均低于10%。进一步作者模拟了不同存储带宽,时钟主频和累加器数量,以及矩阵乘单元尺寸下的性能。
表7: 按照时钟周期衡量的TPU硬件性能计数器与性能模型差距。平均8%

图11显示了将这些参数从0.25倍缩放到4倍时性能与TPU Die的相关敏感性。仅显示了加权平均的点线图,但几何平均的图非常类似。除了评估仅提升时钟主频的影响(图11中的Clock线),作者也显示了增加时钟主频并且累加器数量相应增加,从而编译器可以保持更多的存储访问在线的设计影响(图11中Clock+)。类似的,图11中的点线也包括了按照矩阵单元单一维度增长的平方增加累加器数量(matrix+),因为矩阵中的乘法器数量从两个维度同时增长,当然同时包含了仅仅增加矩阵单元(matrix)。
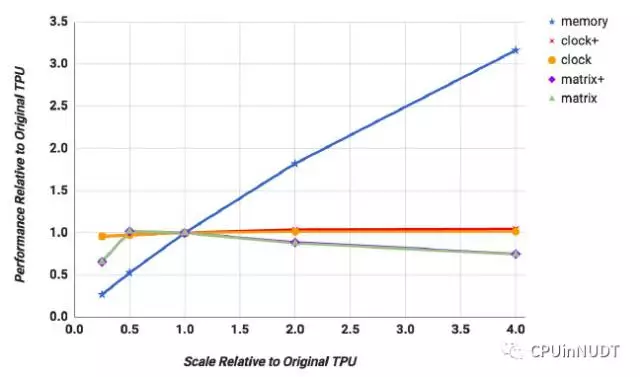
图11 TPU性能的加权平均从0.25倍增加到4倍:存储带宽,时钟主频+累加器,时钟主频,矩阵单元维度+加速器,以及矩阵单元维度。加权平均是的很难开除对单独DNN应用的贡献,但是4倍的存储带宽可以提高MLP和LSTM的性能3倍,但更高主频对他们毫无效果。对CNN而言则完全相反;4倍时钟主频可以提高性能2倍,但是更快的存储几乎没有收益。更大的矩阵乘单元对任何DNN都没有效果。
首先,增加存储带宽(memory)有最大的影响:在存储增加4倍的时候性能平均提高3倍。其次,无论有没有配置更多的累加器,平均下来主频提升几乎没有任何好处。原因是MLP和LSTM都是存储密集的,只有CNN是计算密集的。虽然从图11中很难直接看出,因为仅显示了所有6个DNN应用的加权平均,将时钟主频增加4倍对MLP和LSTM几乎没有影响,但CNN性能提高2倍。再次,图11 中所有应用的平均性能在矩阵单元从256x256扩展到512x512的时候,都轻度下降,无论是否有更多的累加器。这一问题类似于大页面中的内部碎片,在两维情况下只会更加恶化。考虑在LSTM1中使用的600x600矩阵,在256x256矩阵单元下,需要9步来切分600x600,总共需要18us时间。更大的512x512单元只需要4不,但是每步需要的时间增加4倍,需要32us时间。TPU的CISC指令虽长,但解码时间并不足以隐藏从DRAM中载入数据的开销。
表8显示了24MiB统一缓冲的利用率,初始的尺寸选择是为了允许MLP能够按2048的批量尺寸来运行。研究人员当前改进了统一缓冲的存储分配方法,将6个应用中最大的存储需求降低到14MiB。在部署的最开始18个月中,TPU使用了全部能力,而新的分配器也在同时开发。现在有额外的边际容量,导致可以容纳更大的模型。
表8: 各个神经网络应用在24MiB统一缓冲中的最大占用量,14MB容量足够

作者接下来以性能模型来评价虚构的TPU改进芯片(TPU’),假设以相同的工艺生产但有比15个月更多的时间用于设计。更复杂的逻辑综合以及模块设计可以让主频提高50%。类似K80一样,设计采用GDDR5存储接口电路,可以将权值存储器的带宽提高至少5倍,将天花板的屋檐转折点从1350移动到250。如图11所示。将主频增加到1050却不改进存储最终将一无所获。如果保留主频为700MHz不变,但使用GDDR5作为权值存储,几何平均显著增长到2.6,加权平均增长到3.9。两种改进都采用的话,几何平均增长到2.9,而加权平均无变化,因此改进的TPU’仅使用更快存储器。
图11不包含主机服务器的时间。用表5的数据来计算主机服务器与TPU的交互时间。加上相同的额外时间后TPU’的平均提升从2.6和3.9分别将到1.9和3.2。这一改变是最优的,因为没有包含CPU独自运行应用的时间。悲观的情况下,可以通过深度调优主机代码以实现TPU’上的3倍加速。
将目前的DDR3权值存储器替换成等效的GDDR5需要将存储通道翻倍到4个。这一改进将增加10%的芯片晶圆面积。但是更高的存储带宽也缓解了统一缓冲的压力,将统一缓冲减少到14MiB可以弥补10%的芯片面积。GDDR5将使得整个TPU服务器的功耗预算从861W提高到大约900W,仍然是单服务器4个TPU的配置。
图9显示在单芯片总性能功耗比上TPU’大约是Haswell的31倍到86倍,是K80的25倍到41倍。而增量指标则飙升到是Haswell的69倍到196倍,以及K80的42倍到68倍。
附件第8部分:讨论
这一部分是按照未来体系结构量化设计第6版[Hen18]中谬误fallacy与缺陷pitfall的辩论风格来撰写的。
- 谬误:在数据中心的神经网络推理应用像重视响应时间一样重视吞吐率
TPU的设计人员为NN开发人员强烈的响应时间需求所震惊,同时在2014年也有建议在TPU上用较大的批量尺寸以达到峰值性能或者延迟需求不会如此紧张。一个驱动的应用是离线的图像处理,并且直觉是如果交互服务也需要TPU,他们能够累积构成更大的批量。即使是关心响应时间的一个应用(LSTM1)开发人员在2014年说时间限制是10ms,而在他们移植到TPU的过程中缩减到7ms。许多这类应用对TPU出乎意料测需求都是对低响应时间的偏好和影响改变了计算公式,应用程序员经常选择减少延迟而不愿意等待累积形成大的批量。幸运的是,TPU有简单和可重现的执行模型,可以帮助满足交互式应用的响应时间目标,并且在相对较小的批量尺寸下也可以接近峰值吞吐率,获得高性能,而不像CPU和GPU。
- 谬误:在数据中心的神经网络推理应用像重视响应时间一样重视吞吐率
TPU的设计人员为NN开发人员强烈的响应时间需求所震惊,同时在2014年也有建议在TPU上用较大的批量尺寸以达到峰值性能或者延迟需求不会如此紧张。一个驱动的应用是离线的图像处理,并且直觉是如果交互服务也需要TPU,他们能够累积构成更大的批量。即使是关心响应时间的一个应用(LSTM1)开发人员在2014年说时间限制是10ms,而在他们移植到TPU的过程中缩减到7ms。许多这类应用对TPU出乎意料测需求都是对低响应时间的偏好和影响改变了计算公式,应用程序员经常选择减少延迟而不愿意等待累积形成大的批量。幸运的是,TPU有简单和可重现的执行模型,可以帮助满足交互式应用的响应时间目标,并且在相对较小的批量尺寸下也可以接近峰值吞吐率,获得高性能,而不像CPU和GPU。
- 谬误:K80 GU体系结构非常符合神经网络推理
GPU在传统上被视为高吞吐率体系结构,它依赖高带宽DRAM和成千上万的线程来达到这一目标。这也解释了为什么K80在推理的时候仅比Haswell处理器快一点点,而远落后于TPU。K80的后继产品必然会包含针对提高推理峰值性能的优化,但是基于其面向吞吐率的体系结构设计方法,使GPU满足严格的延迟限制是更加艰巨的挑战。正如第7部分所描述的,TPU还有足够的改进空间,因此符合NN推理并非是一个简单的处理器体系结构设计目标。
- 缺陷:体系结构设计师忽视了重要神经网络任务
Google研究人员非常高兴的看到体系结构社区关注神经网络:ISCA2016大会上15%的论文与神经网络的硬件加速器有关[Alb16][Che16a] [Chi16] [Han16] [Kim16] [LiK16] [Liu16] [Rea16] [Sha16]!但所有9篇论文都考虑了卷积神经网络CNN,而仅有2篇提到了其他类型的神经网络。CNN比MLP更复杂,并在神经网络竞赛中处于突出地位[Rus15],这或许能够解释其诱惑力,但CNN仅占据数据中心应用的5%。虽然CNN可能在(云计算)边缘端设备常见,但在数据中心上卷积网络的数量还无法与MLP和LSTM相比。Google的研究人员希望体系结构社区至少以相同的热度去加速MLP和LSTM。
- 缺陷:对神经网络硬件,每秒推理数(IPS: Inferences PerSecond)是一个不精确的综合性能度量
Google测试结果显示IPS对神经网络硬件而言是一个糟糕的总体性能指标,因为它能够非常简单颠覆在应用中典型推理的复杂度(例如,层数、尺寸和层次类型)。例如,TPU在4层MLP1上有360,000的IPS,但在89层的CNN1上仅有4,700的IPS,变化有75倍之多!因此,在神经网络加速器上使用IPS作为单一速度指标将比在传统处理器上使用MIPS或者FLOPS更容易误导[Hen18],IPS指标应该更加被鄙视。为了更好的比较神经网络机器,我们需要以高层次书写的测试程序集,并移植到各种题型结构上。Fathom是在测试程序集上较有希望的尝试[Ado16]。
- 谬误:如果采用超频模式K80 GPU的结果会更好
抛开K80超频模式在TCO上的负面影响(第3部分),用LSTM1来测试。超频模式提升主频到原来的1.6倍—从560到875MHz—性能提升了1.4倍,但也将功耗提升了1.3倍。性能功耗比的净收获是1.1倍,因此对于LSTM1而言在能量—速度综合分析的条件下超频的影响有限。
- 谬误:如果更有效的时候或者与新版本进行比较,CPU和GPU的结果可能接近TPU
原本Google有CPU上一个DNN应用的8位结果数据,在大量的针对AVX2整数支持工作之后。收益约是3.5杯。提供所有应用在CPU上的浮点结果并没有多少困惑(或者议论空间),除了一个例外,即天花板上的改变。如果所有的DNN有类似的加速比,性能功耗比比例将从41-83倍降低到12-24倍。最新16nm,1.5GHz,250W的P40数据中心GPU可以每秒执行47T个8位操作,但在2015年早期并无法获得,因此与论文中的三类平台并不冲突。在作者有限的时间中并无法或者P40的峰值性能。如果要与新的芯片进行比较,第7部分显示了使用K80的GDDR5后,28nm下,0.7GHz,40W的TPU性能也能提高三倍(代价是额外10W功耗)
- 缺陷:性能计数器作为神经网络硬件的事后补充而添加
TPU具有106个性能技术器,如果还有什么需要的话,那就是更多的计数器(参见表3)。神经网络加速器存在的理由就是性能,在它们的快速进化过程中现在还太早以至于不能简单的依靠直觉。
- 谬误:经过两年的软件调优,现在提升TPU性能的唯一途径是硬件升级
CNN1在TPU的性能还能进一步提升,如果模型开发人员和编译器开发人员能做更多的工作,让CNN1和TPU硬件匹配。例如,对4个全连接层,开发人员可以重新组织来自卷积层次中的多个小批量,聚集成一个更深的批量(从32到128)。类似的单一层次可以提高矩阵单元的利用率(表3)。由于CNN1当前在TPU上的运行速度比CPU快70倍,CNN1的开发人员已经非常高兴,因此并不清楚什么时候能够进行类似的优化。
附件第9部分:
回朔至少25年,有两篇综述性论文[Ien96][Asa02]记录了定制神经网络加速器。例如,CNAPS芯片包含64个16位的SIMD阵列,由8位乘法器构成,并且多个CNAPS芯片能够连接在一起构成序列[Ham90]。Synapse-1系统基于定制的脉动乘加芯片MA-16,一次执行16个16位乘法[Ram91]。该系统将多个MA-16芯片串联在一起,并用定制的硬件来完成激活功能。
配置T0定制ASIC加速器,25台SPERT-II工作站从1995年开始部署,同时进行面向语音识别的神经网络训练和推理[Asa98]。40MHz的T0在MIPS指令集结构上添加了向量指令。8-lane向量单元可以在每个周期产生16个32位算术结果,输入是8位和16位,这是的T0比SPARC-20工作站在训练时快20倍,在推理时快25倍。当时发现16位对训练是不够的,因此加入了双16位的机器字,导致训练时间翻倍。为了避免负面影响,开发人员引入了32位的”束bunches”(批量batchs)到1000个数据集来减少耗费在权值更新上的时间,使得双字比用单个16位字但没有批量更快。
更现代的例子是DianNao系列神经网络体系结构,用针对NN应用访存模式的有效结构设计来支持最小化片上和外部DRAM的存储访问[Keu16][Che16a]。均使用16位整数操作,并且所有的设计都深入到后端布线阶段,但没有制造芯片。原始的DianNao使用一组64个16位整数乘累加单元,配置44KB片上存储器,预计在65nm工艺面积为3mm2,主频1GHz,功耗0.5W[Che14a]。大多数能量被用于DRAM访问以获取权值,因此后继的DaDianNao采用36MiB的eDRAM将权值保存在片上[Che16b]。目的是在多芯片系统中有足够的片上存储来避免外部DRAM访问。接下来的PuDianNao超出DNN之外面向更为传统的机器学习算法,例如支持向量机[Liu15]。另外一个分支是ShiDianNao瞄准CNN,通过将加速器和感应器直接相连来避免DRAM访问[Du15]。
卷积引擎也关注图像处理中的CNN[Qad13]。这一设计包含了64个10位乘累加单元,定制的Tensilica处理器预计在45nm工艺能够运行在800MHz。预计比SIMD处理器的能源面积小了高8倍到15倍,并控制在特定核心定制硬件能源面积效率的2-3倍。
Fathom测试程序的论文看起来报告得结果和Google的相反,GPU运行推理的速度比CPU快很多[Ado16]。但是,他们论文中使用的CPU和GPU都不是服务器级别的,CPU仅有4核,应用也没有使用CPU的AVX指令,并且也没有响应时间的截断(见表4)[Bro16]。
微软的投石机计划(ProjectCatapult)是众多建议使用可重构机制[Far09] [Cha10] [Far11] [Pee13][Cav15] [Zha15]支持DNN中部署最为广泛的例子。他们选择FPGA而不是GPU是为了减少功耗,同时也是为了减少延迟敏感应用不能有效映射到GPU上的风险。FPGA也能够用作其他目的,例如搜索、压缩和网络接口卡[Put15]。TPU项目实际上是以FPGA开始的,但当Google的人员发现当时的GPU在性能上完全无法和GPU进行竞争时就放弃了这一技术,并且定制TPU能够以比GPU更低的功耗做到一样快或者更快,这使得它对FPGA和GPU都有巨大优势。
虽然最早在2014年发表[Put14],Catapult是TPU同时的项目,因为与TPU一样在2015年向数据中心部署28纳米的Stratix V FPGA。Catapult主频为200MHz,3926个18位的MACs,5MiB的片上存储,11GB/s的存储带宽,功耗25瓦。而TPU主频为700MHz,65536个8位的MACs,28MiB片上存储,34GB/s存储带宽,典型功耗40W。新版本的Catapult使用更新的FPGA,并从2016年开始以更大规模部署。
Catapult V1运行CNN—使用脉动矩阵乘法器—是2.1GHz双路16核服务器性能的2.3倍。在Catapult V2上使用了新一代FPGA(14纳米Arria10),性能增长到7倍,采用更仔细的布局之后性能可能涨到17倍[Ovt15b]。虽然是像苹果与桔子这样不合适的对比,现在的TPU芯片运行其目标CNN比更快的服务器快40倍到70倍(表2和表6)。可能最大的区别在于为了获得最佳的性能,用户需要用低级别的Verilog硬件描述语言书写大段程序[Met16][Put16],而在TPU上用TensorFlow框架的高级支持书写更短的代码。也就是说,再编程能力在TPU体现在软件层,而在FPGA则体现在固件层。
当前的研究,在TPU已经部署之后,主要是通过优化权重和数据非常少甚至为零的情况来加速DNN。TPU团队紧张的安排排除了类似的优化,但已经在研究中看到了类似的机会。有效的推理引擎基于第一遍执行可以将权重数据减少10倍[Han15],用一个分离的步骤滤掉太小的值,接下来使用哈夫曼编码进一步缩减数据[Han16]。Cnvlutin[Alb16]在激活的输入为零时避免乘法—44%情况是这样的,看起来部分原因在于非线性函数ReLU将所有负值转换为0—能够平均提高性能1.4倍。
Eyeriss是一种全新、低功耗的数据流体系结构,利用运行步长编码数据来减少存储占用,并且在输入为0时避免计算来节约功耗。使用Eyeriss的术语,一个TPU的卷积层将C和M映射到矩阵单元的行和列,使用HWN周期来执行一遍。对于高C/M值,TPU用RS遍来处理层次;对低C/M,一些技术可以用减少运行遍并提高利用率。(在线参考文献可以发现更多内容[Ros15a][Ros15b] [Ros15c] [Ros15f] [Tho15] [You15]).
Minerva是一个跨越算法、体系结构和电路描述的协同设计系统,通过裁剪值小的活跃数据且部分量化数据将功耗降低8倍[Rea16]。[Gup15]考察了在训练中使用16位定点算术而不是推理。其他改进低精度DNN计算的方式包括在技术中使用模拟电路来改进能耗和性能[LiK16][Sha16]。通过裁剪指令集适用于DNN,寒武纪裁剪了代码尺寸[Liu16]。当前的工作还考虑了对神经网络的存储器中处理体系结构(PIM: Processor-In-Memory)[Chi16][Kim16].
将TPU与其中部分结构比较:
- [Che14a]通过DMA将数据从DRAM传到输入和权重缓冲。通过三段流水的NFU会准备好乘法、加法和非线性函数;结果进入输出缓冲,接下来进入DRAM。NFU没有存储,并且不是脉动方式。
- [Gup15]看起来将两个矩阵输入都流化处理,并以脉动阵列方式存储部分和;TPU存储权重矩阵数据片段但将其他输入流化,并且预先激活部分和。TPU并不支持完善的舍入。
- [Zha15]构建计算单元相当于一个4x2版本的TPU矩阵单元。在ASIC中,交叉开关连接输入和输出缓冲到这些计算引擎的连线资源非常可观。非常奇怪的是在[Zha15]中没有体系结构支持来进一步减少计算引擎产生的结果。
所有三种结构[Gup15][Che14a][Zha15]在技术扩展中都在DRAM中保存激活;TPU的统一缓冲尺寸就是为保证没有数据溢出到DRAM或在正常操作过程中发生重载。
附件第10部分:
虽然依赖于I/O总线,并且只有相对很少的存储带宽,限制了TPU的利用率—6个神经网络中的4个是存储密集型—一个大数据中的一小部分也可以相对非常大,正如天花板模型所展示的。这一结果导致了Amdahl法则的“聚宝盆结构Cornucopia Corollary”:一个巨大廉价资源的低利用率仍然可以高性能并且成本有效。
TPU数量级降低了能耗和面积,主要是因为用8位整数脉动矩阵乘法器替代了K80 GPU中的32位浮点数据通路,集成了25倍的MAC单元(65536个8位MAC vs. 2496个32位MAC),与3.5倍的片上存储(28MiBvs. 8MiB), 占据相对较小的芯片面积使用不到K80功耗的一半。更大的存储帮助增加应用中的操作密度,使得应用能够更加充足的利用MAC单元。
作者发现尽管当前体系结构社区重点关注CNN,但他们仅占据Google数据中心代表性神经网络负载的5%,建议给MLP和LSTM更多的关注。回顾历史,这看起来和许多体系结构师关注于浮点性能,然而主流负载被整数操作所主导。
作者观察到每秒推理(IPS:Inferences Per Second)更像是神经网络的一个功能,而不是底层硬件目标,并且对NN处理器而言IPS是比MIPS和MFLOPS对CPU和GPU更糟糕的单一性能尺度。
作者也学习到推理应用具有严格响应时间限制,因为他们经常是面向用户的应用的一部分,因此神经网络体系结构需要面对在99%的延迟截止时间是执行良好。虽然K80在训练中可能很好,平均下来在Google的负载上仅比Haswell快一点点,可能源于GPU重点是吞吐率而不是延迟;这与Google的推理应用中严格的响应时间。
TPU芯片借助MAC和片上存储的优势来运行用领域专用的TensorFlow框架书写较短的程序,能够比K80 GPU芯片快15倍,最终性能功耗比优势是29倍,这与性能和总拥有成本之比相关。与HaswellCPU芯片相比,对应比例是29和83。虽然未来的CPU和GPU显然能够更快运行推理,重新设计TPU使用2015年的GPU存储器将再快2到3倍,并将性能功耗比优势提高到K80的70倍与Haswell的200倍。
总体来说,TPU的成功在于很大—但不是过大—的矩阵乘单元;实际上用软件控制的片上存储;运行整个推理模型以减少对主机CPU依赖的能力;单线程确定的执行模型被证明能够很好匹配99%的响应时间;足够的灵活性是的能够像2013年的神经网络一样匹配2017年的神经网络;剔除了一些通用的特性降低芯片面积和功耗,即便有更大的数据通路和存储器;用量化应用来使用8位整数;并且这些应用以TensorFlow书写,是的他们能够较容易的一直到TPU上获得高性能,而不是为不同的TPU硬件完全重写。
在计算机体系结构中商业产品的数量级差距非常少见,这使得TPU成为领域专用体系结构的原型样片。作者希望后继能够进一步抬升门槛。
附件第11部分:
作者感谢Google公司的领导层认可TPU的需求,并且提供资源来构建、分发、评价和发表工作。特别感谢Luiz Barroso和JamesLaudon帮助启动了项目。设计、验证和实现类似TPU的软件和硬件,同时制造、部署和批量使用动用了一个村子的力量,这也是作者如此之多的原因。(除了DavidPatterson之外所有的作者都一直为TPU工作,而David在2016年才加入)。论文的前4位作者做了大量的实验评估工作,这也是他们排在前面的原因,其他的作者则是按照字母序排列。Jouppi同时也是整个项目的资深体系结构师,对他辛勤工作的嘉奖则是领头第一作者。
本文转载自微信公众号CPUinNUDT,由《基于论文分析Google的张量处理器TPU》及《基于论文分析Google的张量处理器TPU(补充)》两篇文章合并而成,如有相关问题,请与原作者联系。