数据探索与数据清洗
一 数据探索
数据探索的目的是及早的发现数据的一些简单规律或特征,数据清洗的目的是留下可靠的数据,避免脏数据的干扰.
数据探索的核心是:
- 数据质量分析(跟数据清洗密切联系)
- 数据特征分析(分布,对比,周期性,相关性,常见统计量等)
二 数据清洗
数据清洗可以按如下步骤进行
- 缺失值处理(通过describe与len发现,通过0数据发现)
- 异常值处理(通过散点图发现)
- 异常值处理(通过散点图发现)
缺失值,处理方式为(删除,插补,不处理);
插补的方式主要有:均值插补,中位数插补,众数插补,固定值插补,最近数据插补,回归插补,拉格朗日插值,牛顿插值法,分段插值等等.
遇到异常值,一般处理方式为视为缺失值,删除,修补(平均数,中位数等),不处理.
插补法处理(中位数)
# coding=utf-8
import pandas as pd
import numpy as np
data = pd.read_csv("taobao.csv")
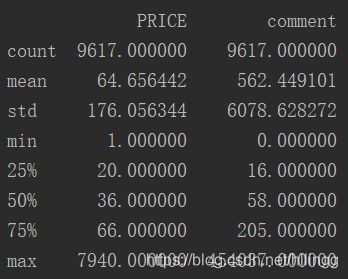
print(data.describe())结果为:

由输出结果可知PRICE和comment的均值,标准差,最大值,各个中位数,最大值,且从图中知价格为0的数据是有问题的,接下来我们对其进行处理.
data["PRICE"][(data["PRICE"] == 0)] = None # 把价格为0的数据用None代替
# 把价格为None的数据用中位数进行插补
for i in data.columns:
for j in range(len(data)):
if(data[i].isnull())[j]:
data[i][j] = 36
缺失值处理后的数据描述为:
print(data.describe())结果为:
异常值的处理(中位数)
1.画散点图(横轴为价格,纵轴为评论数)
import matplotlib.pylab as plt
price = data.iloc[:, 2]
comt = data.iloc[:, 3]
plt.plot(price, comt, "o")
plt.show()输出结果为:
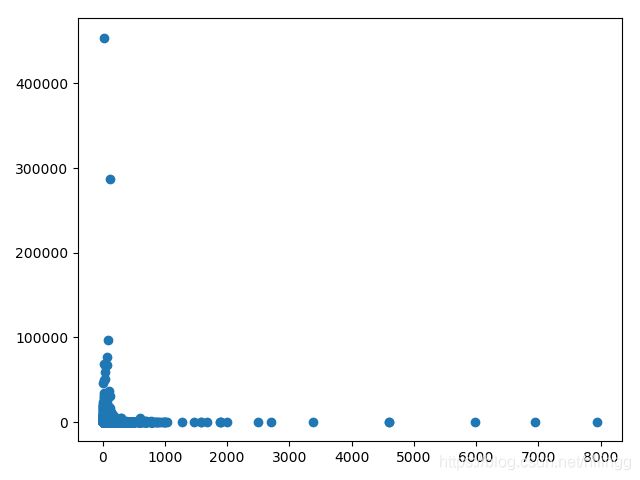
由图我们可以把知评论数大于200000的点作为异常点,把价格大于2000的点作为异常点,并且分别用各自的中位数替换异常点,如下:
# 评论数异常>200000,价格异常>3000
line = data.shape[0] # data的行数
column = data.shape[1] # data的列数
da = data.values
for i in range(line):
for j in range(column):
if (da[i][2] > 2000):
da[i][j] = 36
if (da[i][3]) > 200000:
da[i][j] = 58异常点处理后的散点图:
plt.plot(da[:, 2], da[:, 3], 'o')
plt.show()