R语言 - 数据预处理
前段时间写数据挖掘作业,用R语言,踩了不少坑,特此记录一下。
1. R语言包的加载:
library("package_name")建议在windows配合RStudio使用R语言,linux下的支持不太友好。
如果显示没有“package_name”这个包,可以在RStudio中使用install.packages("package_name")下载。
可能会遇到下载完“package_name”这个包却无法使用的情况,需要把包的压缩文件拷到R的安装目录下的library目录下解压。
2. 读取某个目录下的所有文件的文件名:
file_names = list.files("./testdir/")file_names中存储了当前目录下testdir文件夹下所有文件的文件名,是一个vector。
3. 读取目录下的xml文件:
xml_name = "test.xml"
xml_path = paste("./testdir/", xml_name, sep = "")
xml = xmlParse(xml_path)paste()函数将两个字符串连接,默认中间是以空格连接,加上sep=""可以去掉空格。
对于R语言中不理解的函数可以再RStudio的console中输入help(function)进行查询,R语言的文档写的还是比较好的。
4. 获取xml中特定标签下对应的值:
获取
***
标签下的所有内容。tag_text <- getNodeSet(xml, "//p")
print(tag_text)tag_text: "
***
"获取
***
下的内容tag_text <- getNodeSet(xml, "//p[@class = 'test']")5. Data clean
去除一段文本中的标点,数字:
text = "This is an article. Maybe it is useful. 2018 04 07"
text.clean_pun = gsub('[[:punct:]]+', ' ', text)
text.clean = gsub('[[:digit:]]+', '', text.clean_pun)gsub()函数将text中所有标点替换为空格,将text.clean_pun中所有数字替换为“”
text.clean: "This is an article Maybe it is usefull "
可以用tm的函数,具体教程可以百度。我暂时没学会
去除停用词:
stopwords_regex = paste(stopwords('en'), collapse = '\\b|\\b')
stopwords_regex = paste0('\\b', stopwords_regex, '\\b')
text.clean = stringr::str_replace_all(text, stopwords_regex, '')这段代码是我在网上copy的,实测能用。将text中的停用词去除。源于stackoverflow的一条回答,具体网址:https://stackoverflow.com/questions/37526550/removing-stopwords-from-a-user-defined-corpus-in-r
6. 文本词干化
library("tm")
library("parallel")
library("SnowballC") stem_text <- function(text, language = "porter", mc.cores = 1){
stem_string <- function(str, language) {
str <- strsplit(x = str, split = " ")
str <- wordStem(unlist(str), language = language)
str <- paste(str, collapse = " ")
return(str)
}
x <- mclapply(X = text, FUN = stem_string, language, mc.cores = mc.cores)
return(unlist(x))
}
stem.news = stem_text(text, language = 'en')R中 = 和 <- 均表示赋值。固定套路,实测可用。还有利用“tm”包实现的一种方法,没学会,大家可以自己百度尝试一下。答案来源:http://tagteam.harvard.edu/hub_feeds/1981/feed_items/1613113
7. 简单云图实现
library("wordcloud")加载所需包wordcloud
text = "this is test and punctuation has been removed test is import"
wordcloud(text, max.word = 100, random.order=FALSE)最简单的云图实现,wordcloud会自动选出词频最高的100个单词进行云图的绘制。
效果如下:

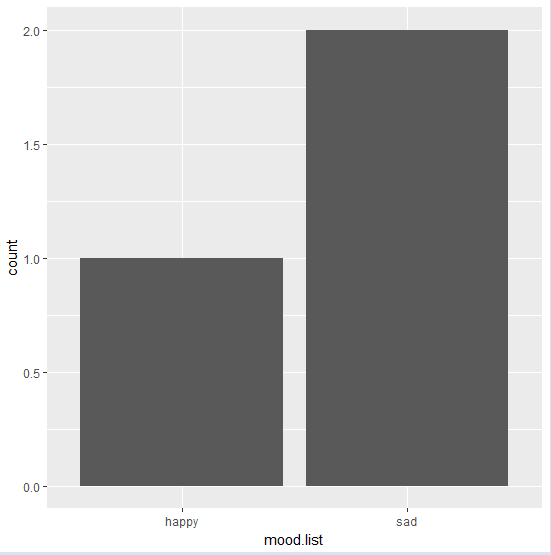
8. ggplot2绘制直方图
library("ggplot2")mood.list = c("sad", "happy", "sad")
mood.dataframe = as.data.frame(table(mood.list))
print(mood.dataframe)
mood.data <- data.frame(mood.list)
ggplot(mood.data, aes(x = mood.list)) + geom_bar() 第二行和第三行可不要,只是便于查看。as.data.frame(table(vector))可以将字符向量组织成单词-词频的形式,非常有用。效果如下:
mood.list Freq
1 happy 1
2 sad 2
data.frame(mood.list)将mood.list转变为数据框类型,因为ggplot()第一个参数的类型必须是data.frame,aes(x = mood.list)确定横坐标,必须是原vector。效果如下: