(相似度、邻近及聚类)Similarity, Neighbors, and Clusters
主要内容:
- 相似度(Similarity) (can be used for classification and regression)
- 距离函数(Distance Function)
- Nearest - Neighbor
- Hierarchical Clustering
- K-Mean
——————————————————————————————————
(一)相似度
相似度是很多数据科学方法和商业解决方案的基础。如果对象之间相似,那么它们共享着很多其他的属性。利用相似度我们可以对事物进行归类,并在此基础上做出各种决策。以下是几个例子:
- 寻找与优质客户相似的客户
- 对用户进行分类
- 推荐系统
- 医学和法律中,依据相似案例来解决问题
将分析的对象数据化之后,我们便可以引进距离函数来衡量对象之间的相似程度。利用对象之间的距离我们便可以对对象空间进行划分,进而得到不同的组别。
Note:
对象属性数据化时会有Heterogeneous Attributes
主要是 Numeric 和 Categorical 两大类
其中Numeric 型数据需要注意的是数据的Scale 和 Range
(二)距离函数
- L1-norm(曼哈顿距离)
![]()
- L2-norm(欧拉距离)
![]()
- Jaccard distance(将两个对象看成集合,运用集合运算、集合中元素数量来构造)
![]()
- Cosine distance (余弦函数距离,可以忽略向量大小)[ignore differences in scale]
![]()
- edit distance
用于度量两个字符串之间的差异
例如:【1113 Bleaker St. 】 【113 Bleecker St.】
最主要思想是:记录将一个字符串转变为另一个字符串所需要的最小改变步数
(counts the minimum number of edit operations required to convert one string into the other)
(三)Nearest-Neighbor Method
思想:
给定一个样本后,我们遍历所有训练集,寻找出几个和新样本最为接近的训练样本,然后基于选出的这些样本来预测新样本的属性
- Classification(nearest - neighbor 的直观解释)
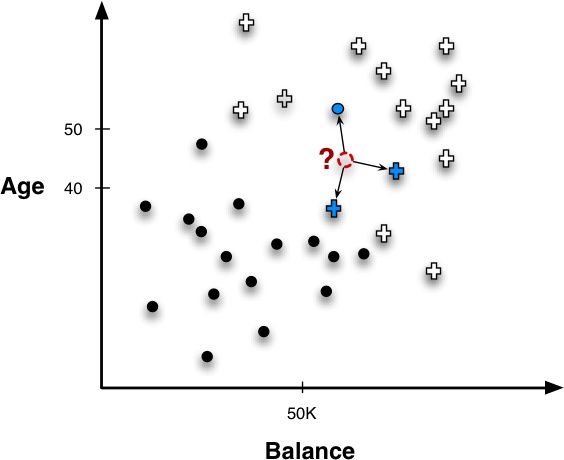
如图‘?’所示样本点是我们需要预测的点,寻找到离它最近的三个点得到两个‘+’一个‘·’的结果,基于这个结果,如果我们采用投票(majority vote)的原则,那么新样本点应当属于‘+’
PS:进一步我们需要考虑我们应该取多少个最近点(k),每个点是否应该有不同的权重
上面的例子我们只是给出了属于哪个类别的结论,现实运用中我们往往需要样本属于各个类别的概率值,所以接下来我们讨论概率估计
- Probability Estimation
在上面的例子中,我们取k=3,属于‘+’的有两个,属于‘·’的有一个,所以我们可以估计(假定权重一致)
![]()
- Regression
Nearest - neighbor Method 不仅仅可以用来分类,其实还可以用来预测对象的数值(类似回归预测)
例如新样本的最近三个训练样本的A属性值(numeric)分别为1,2,3 (假设设定相同的权重),那么我们可以预测新样本的A属性值为(1+2+3)/3 = 2
(Note: 与传统回归不同的是,我们在选取新样本的邻近样本是并未用到属性A)
关于 K 值选取的讨论
权重计分方式可以较好地权衡K值选取的问题,距离较远的点其权重降低,自动将不重要的点去除(约等于)【Weighted scoring has a nice consequence in that it reduces the importance of deciding how many neighbors to use. Because the contribution of each neighbor is moderated by its distance, the influence of neighbors naturally drops off the farther they are from the instance. Consequently, when using weighted scoring the exact value of k is much less critical than with majority voting or unweighted averaging.】
两个特例:
- 1-NN 过拟合
- n-NN 每个新样本的预测值都是训练集的平均值
Nearest-Neighbor Method 的公式化表示:(Combination Function)
Majority vote classification
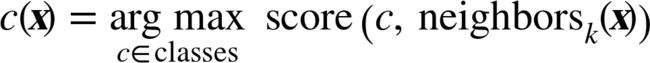
【Here neighborsk(x) returns thek nearest neighbors of instancex】
Majority scoring function
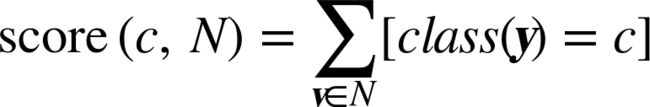
Similarity-moderated classification
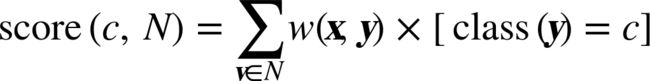
the distance is commonly used:

Similarity-moderated scoring
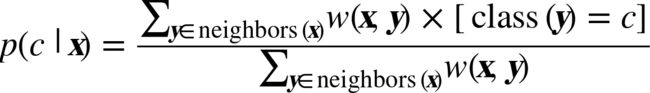
Similarity-moderated regression

Nearest - Neighbor 方法注意点
可解释性(Intelligibility)
可解释性问题主要表现在两个方面
- (依据模型做某项决策的理由)the justification of a specificdecision
- 多数情况下是可以解释清楚的,也能被大众接受,例如Amazon和Netflix的推荐系统
- 但是有的情况下却无法让用户信服,例如抵押贷款申请被拒绝的理由是:我们发现您和王某某和李某某比较像,而且他们两个都有违约情况(回归模型就不存在这样的问题,例如模型中有一个参数是收入水平,那么我们可以和客户说,如果你的收入达到了XXX水平我们就不仅拒绝你的申请)
- (整体模型的解释)the intelligibility of an entiremodel
综上:如果模型的可解释性和决策理由受到质疑时,我们应当尽量避免使用这个模型
维度问题和领域知识(Dimensionality and domain knowledge)
有太多的特征,或者说有太多的与相似度计算无关的变量会成为一个问题,因为那些无关变量会对距离计算产生误导,也即计算出来的距离不能很好地衡量我们希望看到的相似度。
在高纬度情况下这种现象可以称为‘维度的诅咒’(curse of dimensionality)
解决办法:
- 变量选取(Feature selection)
- 基于应用背景做出判断(Background knowledge)
- 自动选择变量的一些方法(Automated feature selection method:例如主成分分析【PCA】)
- 依据领域知识给变量人工赋予不同权重
Nearest-Neighbor Method 的效率
- 该模型的优势是训练比较快,因为模型训练部分只涉及到训练样本的存储
- 该模型的主要计算量集中在模型预测环节(这个环节Cost 较大)
(四)Hierarchical Clustering
- This idea of finding natural groupings in the data may be called unsupervised segmentation, or more simplyclustering.
- Supervised modeling involves discovering patterns to predict the value of a specified target variable, based on data where we know the values of the target variable. Unsupervised modeling does not focus on a target variable. Instead it looks for other sorts of regularities in a set of data.
Hierarchical cluster 的思想

- Hierarchical cluster 的优势是不用事先确定类别的数量,就可以观察类别间的相似情况
(五)k-means method
对于聚类而言,最普遍的方法便是将每个类别用他们的聚类中心来表示
|
|
|


基于聚类中心的算法中,我们最为熟悉的当属 k-means cluster
- k-means 的第一步:
算法开始的时候初始化k的聚类中心,一般是随机生成,有时候会从数据点中选取出k个点,或者用户自己认为给定k个点,或者利用一些预处理的方式选出k个点
- k-means 的第二步:
重新计算每个类别的聚类中心,替代掉原有的中心,一直迭代直到不再变动(或者到达迭代的阈值)
- 由于k-means 方法 与初始点的选取有关(可能会得到局部最优解),所以一般要多次执行k-means 算法
|
|
|

- 结果的判断(使用偏离的距离平方和)
The results can be compared by examining the clusters(more on that in a minute), or by a numeric measure such as the clusters’ distortion,which is the sum of the squared differences between each data point and itscorresponding centroid. In the latter case, the clustering with the lowestdistortion value can be deemed the best clustering.
- 就运行时间而言,k-means 要比 hierarchical cluster 效率更高
- k-means 每次迭代只需要所有点与中心点的距离,而hierarchical cluster 则需要计算两两之间的所有距离
- k-means 的关键在于如何确定k值
- 尝试不同的k值,查看模型效果
Understand cluster
- clustering often is used in exploratory analysis, so the whole point is to understand whether something was discovered, and if so, what?
Multiple cluster
We have k clusters so wecould set up a k-class task (one classper cluster). Alternatively, we could set up a kseparate learning tasks, each trying to differentiate one cluster from all theother (k–1) clusters.
Recall
- As we have emphasized, one of the fundamental concepts of data science is that one should work to define as precisely as possible the goal of any data mining.
- we would like to explore our data, possibly with only a vague notion of the exact problem we are solving? The problems to which we apply clustering often fall into this category. We want to perform unsupervised segmentation: finding groups that “naturally” occur (subject, of course, to how we define our similarity measures).