URI,URL概念和spring中的Resouce含义的探究
目录
1.前言
2.URI概念
1.1 Overview of URI
1.2 URI, URL and URN
1.3 URI的举例
1.4 URI Syntactic Components
1.4.1 Scheme Component
1.4.2 Authority Component
1.4.3 Path Component,Query Component
2. URI,URL和URLStreamHandler简单说明
3. spring中为什么要对资源封装
4. 小结
1.前言
之前因为看到spring源码深度解析中提到了对资源封装的来由,觉得比较困惑,而且我也是对URI和URL的概念比较混乱,才有了这篇的整理,源头起源于jdk说到了一篇rfc,事实证明即便英文再不好,也得硬着头皮看,会有意想不到的收获。此外还有一篇博客感觉不错,这里直接贴链接:https://www.cnblogs.com/throwable/p/9740425.html。
2.URI概念
URI,统一资源标识符,Uniform Resource Identifier。为了搞懂概念,参照机器翻译,觉得翻译有问题的可以去看原版:https://www.ietf.org/rfc/rfc2396.txt。感觉实在无法理解的不翻译,感觉看不懂而且感觉没必要看的跳过。翻译后面会加上个人的想法。
1.1 Overview of URI
URI为标识资源提供了一种简单且具有扩展性的方法(extensible means)。URL的语法和语义(semantics)规范(specification)源自World Wide Web global information initiative中引入的概念.
下面对URI这三个分别继续解释:
Uniform:统一性提供了几种好处:可以在同个上下文中使用不同类型的资源标识符,即便这些访问资源的机制并不相同;它允许不同类型的资源标识符可以有通用的语法和统一的语义解释;它允许引入新的资源标识符类型而不会妨碍(interfering with)到现有标识符到使用;而且,它可以在不同的上下文中对标识符进行复用,从而使得新的应用类型或协议可以重新利用现有的资源标识符( to leverage a pre-existing, large, and widely-used set of resource identifiers)。可以看到后面的的解释是说可以复用,说明在不同场景对标识符的释义都不同,这个取决于具体的协议和使用的场景。而且我们也可以自定义一个解析的规范,具有扩展性。那如果这样解释和统一有什么关系?统一的好处不就是方便使用么,难道是定义一个较为统一的规范和概念?
Resource:只要可以被标识,那就是一个资源。例如电子文档,图片,服务(如洛杉矶当天到天气预报)以及其他资源的集合。并不是所有资源都是指网络上可以被找到的(retrievable,检索)。例如人,公司,甚至是图书馆中的一本书也可以被视为资源。看来资源的定义范围很广泛。资源是到一个或一组实体的概念性的映射,该实体并不一定对应于任一时间点上的实体。比如说“人”这个概念是对我们这类高级动物在个体上的一种概念上的映射,但是人这个概念并不会随着我们年龄的变化而改变,感觉。。可以这么理解。因此,即使资源的内容(即资源当前对应的实体)随时间而变化,只要概念的映射在这个变化的过程中,没有发生变化,那么资源也可以保持不变。即便是资源本身随着时间消亡了。
Identifier:标识符是一个对象,它可以作为对可以被标识的对象的一种引用。在URI中,这个对象就是一个受到语法限制的(restricted)字符序列。也就是说,我们人为定义来一个规则来引用可以被标识的资源。
标识了资源后,系统就可以对该资源进行各种操作,这些操作的特征如带有:访问,更新,替换,查找属性等字样。
1.2 URI, URL and URN
一个URI可以被进一步分类为a locator, a name, or both。术语URL(Uniform Resource Locator,统一资源定位器)就是URI的子集,它的表示方式主要倾向于用访问机制来标识资源,如网络的”位置“(不过这个翻译和后面的这个他们的网络”位置“的举例感觉不是很搭,干脆直接理解为以位置来标识资源),而不是用资源的名称或者是其他属性来标识。术语URN(Uniform Resource Name,统一资源名称)也是他的一个子集,它要求即便是这个资源不复存在了或者不可用了,也不能复用,要保证一个全局的唯一性和持久性。
Although many URL schemes are named after protocols, this does not imply that the only way to access the URL's resource is via the named protocol. Gateways, proxies, caches, and name resolution services might be used to access some resources, independent of the protocol of their origin, and the resolution of some URL may require the use of more than one protocol (e.g., both DNS and HTTP are typically used to access an "http" URL's resource when it can't be found in a local cache).通过机器翻译,这段话要说明的感觉是访问一个资源有时候可能并不仅仅是只靠有一个协议。
1.3 URI的举例
下面列举了常用的URI:
- ftp,文件传输协议:ftp://ftp.is.co.za/rfc/rfc1808.txt;
- gopher和gopher+协议: gopher://spinaltap.micro.umn.edu/00/Weather/California/Los%20Angeles;在www出现之后就基本没人用了。
- http,超文本传输协议:http://www.math.uio.no/faq/compression-faq/part1.html
- mailto,用于电子邮件,mailto:[email protected]
- 新闻?news scheme for USENET news groups and articles:news:comp.infosystems.www.servers.unix
- 电话协议: telnet://melvyl.ucop.edu/
1.4 URI Syntactic Components
URI的语法取决于scheme。通常absolute URI如下所示:
: 冒号后面具体什么意思,取决于scheme。而且URI语法并不要求scheme-specific-part有通用的结构和语义。虽然如此,但是我们可以对URI的子集定义通用的语法,用于表示命名空间的层次关系:
://? 除了scheme之外,其余的可能不一定会用到。比如说一些URI scheme并不允许出现
本质上(in nature)分层的URI使用斜杆“/”字符来分割分层的组件,可能会觉得和文件系统中的文件路径很像,但是这并不就说明了资源就是文件,URI就是文件系统路径名。e,反正就是说,虽然URI用斜杆来对层次进行分割,和文件路径的分隔符一样,但是二者并不相同。
absoluteURI = scheme ":" ( hier_part | opaque_part )
hier_part = ( net_path | abs_path ) [ "?" query ]
net_path = "//" authority [ abs_path ]
abs_path = "/" path_segments
opaque_part = uric_no_slash *uric
uric_no_slash = unreserved | escaped | ";" | "?" | ":" | "@" | "&" | "=" | "+" | "$" | ","下面对组件一一解释。
1.4.1 Scheme Component
正如(just as)有许多不同访问资源的方法一样,我们可以用不同的scheme来标识这类资源。URI的语法由一系列(a sequence of)通过保留字符(reserved characters)所分割的组件构成,而第一个组件定义了URI剩余部分的语义。shcema的名称由一系列字符组成,开头是小写的字母,后面可以是小写字母,数字,加号,点号(period),-连字符(hyphen)。
scheme = alpha *( alpha | digit | "+" | "-" | "." )虽然我贴了很多这种,但是目前还没看懂意思
1.4.2 Authority Component
看起来说的是授权用的(a naming authority),有两种:Registry-based Naming Authority和Server-based Naming Authority。前面那种没看懂看名称说的是你只有注册了才能用,也就是说可能有一个权威的机构管理这个;后面的是基于ip协议的:
@: userinfo就是访问服务器所需的授权信息,可能是用户名密码等等,例如:user:password。但是因为是明文(clear text),所以不推荐。
1.4.3 Path Component,Query Component
路径组件标识了特定scheme或authority组件范围中的资源,这个资源路径不一定就是文件路径这个要看定义。查询组件的含义有资源本身来释义,比如说数据库查询服务,可能是就是传输查询条件。
需要注意的是到目前为止,说到的都是一个层次结构,是我们自己定义的一个通用的结构,属于URI的一个子集。
2. URI,URL和URLStreamHandler简单说明
看了上面的介绍,虽然后面有点混乱,但是基本上对URI有了个概念,现在看看java中的URI类。首先是URI的属性:
// -- Properties and components of this instance --
// Components of all URIs: [:][#]
private transient String scheme; // null ==> relative URI
private transient String fragment;
// Hierarchical URI components: [//][?]
private transient String authority; // Registry or server
// Server-based authority: [@][:]
private transient String userInfo;
private transient String host; // null ==> registry-based
private transient int port = -1; // -1 ==> undefined
// Remaining components of hierarchical URIs
private transient String path; // null ==> opaque
private transient String query;
// The remaining fields may be computed on demand
//... 可以看到这些属性和之前说的各个组件是对应的,说明URI是按照层次规范来实现的。
从构造函数进入,传入一个字符串会进行解析操作,这个解析器是一个内部类,目的在于校验其格式的合法,并将各个属性提取便于我们获取,至于如何校验就算了,主要是看的头疼,再者就是目前也没有必要非要去看懂:
// [:][#]
//
void parse(boolean rsa) throws URISyntaxException {
//...
} 也就是说URI本身并没有任何访问资源的能力。
而URL则不同,可以看到URL中除了一些组件属性之外,还有handler的处理,也就是说访问资源交给了URLStreamHandler的实现去处理:
//比较两个是否是标识同个资源,不过比较的时候不包括fragment
public boolean sameFile(URL other) {
return handler.sameFile(this, other);
}
//表示URL引用到资源的连接
//这里创建的连接并不是实际的,而是逻辑的,真正的连接实在connect的时候
//URLConnection也是有很多子类的,根据协议的不同
public URLConnection openConnection() throws java.io.IOException {
return handler.openConnection(this);
}具体的获取:
static URLStreamHandler getURLStreamHandler(String protocol) {
//初始化里面只有一个file协议的处理器
URLStreamHandler handler = handlers.get(protocol);
if (handler == null) {
boolean checkedWithFactory = false;
// Use the factory (if any) 使用工厂参加,默认情况下是空的,我们可以自己实现
if (factory != null) {
handler = factory.createURLStreamHandler(protocol);
checkedWithFactory = true;
}
// Try java protocol handler
if (handler == null) {
//后面就是计算包名:sun.net.www.protocol.协议.Handler,反射实例化
//...
}
}
//...
}可见具体的Handler都在这个包下面,协议的实现就是这些:
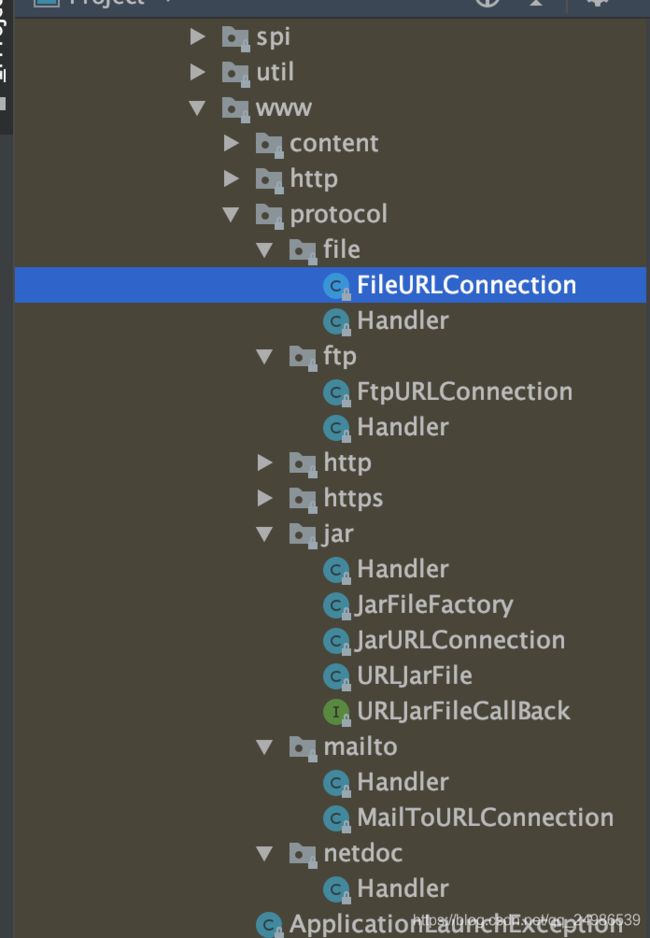
而对于工厂来说,也有一个默认的实现:
//工厂中只有一个接口,那就是创建url流处理器
public interface URLStreamHandlerFactory {
URLStreamHandler createURLStreamHandler(String protocol);
}
//Launcher,这个默认的实现也是从指定包名中反射实例化
private static class Factory implements URLStreamHandlerFactory {
private static String PREFIX = "sun.net.www.protocol";
private Factory() {
}
public URLStreamHandler createURLStreamHandler(String var1) {
String var2 = PREFIX + "." + var1 + ".Handler";
try {
Class var3 = Class.forName(var2);
return (URLStreamHandler)var3.newInstance();
} catch (ReflectiveOperationException var4) {
throw new InternalError("could not load " + var1 + "system protocol handler", var4);
}
}
}现在脑子里面现在可以形成一个uml图,因为不想画了:
- URL持有URLStreamHandler的接口,URL并不需要知道接口实现是什么,它只要利用处理器提供的创建接口,来构造一个连接URLConnection,获取输入输出流,或者是子类连接提供的特定接口进行操作,最后关闭。
- URLStreamHandler下面有很多子实现类Handler,根据协议类分包存放
- 同样URLConnection下面也有很多实现的子类
这里并不是要解析实现源码,而是为了衔接spring源码深度解析中,关于资源封装的概念。所以直接进入最后一步
3. spring中为什么要对资源封装
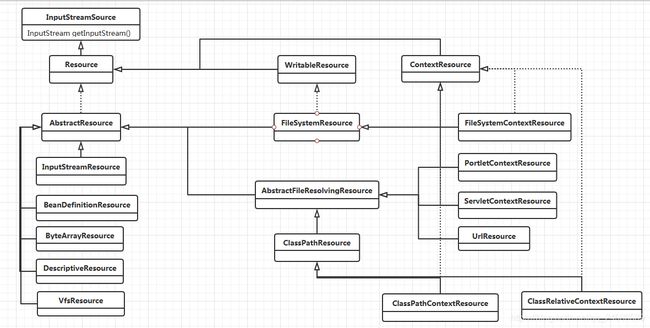
spring源码深度解析中提到:
在Java中,将不同来源的资源抽象成URL,通过注册不同的handler(URLStreamHandler)来处理不同来源的资源读取逻辑,一般来说,通过不同的前缀来进行识别,如file:,http:,jar:。
但是URL并没有默认定义对classpath或ServletContext等资源的的handler,虽然我们可以注册自己的URLStreamHandler来解析特定的前缀,如classpath:,但是这就需要了解URL的实现机制,而且URL并没有提供可以检查当前资源是否可读,是否存在的方法。
基于上面的原因,spring对内部使用的资源实现了自己的抽象结构,也就是Resource。
这段话我之前看到的时候就很困惑,直到我整理出上面的那些。这个时候我们就可以很清楚的知道,标识符并不能说明资源是否存在,是否可读等,而且也并没有提供关于classpath的协议解析。也就是说一切为了便捷,和符合需求,而且为了可以复用代码他也提供了和URL和URI的转换。
public interface InputStreamSource {
InputStream getInputStream() throws IOException;
}InputStreamSource封装任何可以返回InputStream的类,比如File,ClassPath下的资源和ByteArray资源等。
Resource接口抽象了所有Spring内部使用到的底层资源:File,URL,Classpath等。
public interface Resource extends InputStreamSource {
boolean exists(); //存在性
boolean isReadable(); //可读性
boolean isOpen(); //是否处于打开状态
//提供了不同资源到URL,URI,File之间的转换,以便获取下面的信息
URL getURL() throws IOException;
URI getURI() throws IOException;
File getFile() throws IOException;
long contentLength() throws IOException;
long lastModified() throws IOException;
//为了便于操作,提供了基于当前资源,创建相对资源的方法
Resource createRelative(String relativePath) throws IOException;
String getFilename();
//可以在错误信息中使用,打印描述符信息
String getDescription();
}对于不同来源的资源文件,都有对应的Resouce实现,如File资源(FileSystemResource)等。
4. 小结
上面虽然有翻译了一小部分,但是比较重要的就只有那个对URI的解释比较有用,其他的目前不怎么关心。下面整理一下理解:
只要可以被标识,就可以当成资源,这个不局限于计算机的世界,现实世界也是。同理URI及其子集也不仅仅局限于计算机世界。资源是一种概念的抽象,它映射的实体可以是一个也可以是一组。而根据使用的方式不同或者说资源的属性,可以分为URL和URN或者其他子集。资源一旦被标识,我就可以据此进行访问和操作,比如说我们的住址就可以进行快递传输,身份证的标识,就可以刷票等。资源等访问方式有很多种,条条大路通罗马,因为访问的机制,我们才需要定义各种scheme。
回到java上,我们为URL的子集定义了一个通用的具有层次性的规范,可以看到java中的URI和rfc中说明的很多是一样的。对于URL,它本身里面实现了一些默认的协议,对资源的访问,将其抽象为了连接URLConnection,通过这个对连接进行操作。但是可以看到这些协议并没有对classpath进行解析,而且URL本身并不能说明资源是否存在是否可以交互,所以自己封装Resouce,但是其实在真正用的时候,很多地方也是用jdk封装的,毕竟重复造轮子没必要,一切为了需求。