Django动态传值给scrapy进行爬虫
dajngo是同步的,而scrapy是异步的.集合起来并不是很理想。
效果如下
B站
S90415-10391650
整个项目在我的github上面,项目结构有点乱
cmzzGithub
再寻找资料的过程中,找到一种代替的方法.就是
把scrapy爬虫框架部署在scrapyd上面,django框架在view通过requests包动态传值,调用scrapy爬虫框架爬取数据然后存入数据库.然后view再从数据库中取出数据.(这里会有一个挺大的问题就是view取数据会比scrapy爬取要快,可以在view使用sleep()解决)
一个动态传值的spider爬虫的写法
class TaobaoSpider(scrapy.Spider):
name = 'taobao'
allowed_domains = ['taobao.com', 'rate.tmall.com']
# 这里初始化这个类,可以动态传值并开始爬虫,这里传的是keyword
def __init__(self, keyword=None, *args, **kwargs):
super(TaobaoSpider, self).__init__(*args, **kwargs)
self.start_urls = ['https://s.taobao.com/search?q={}'.format(keyword)]
self.keyword = keyword
def parse(self, response):
pass
官方文档:
scrapyd,ubuntu使用apt-get install scrapyd,Windows 下pip install scrapyd
一个比较好的scrapyd部署教程
安装之后,在scrapy.cfg同级目录下命令scrapyd,然后服务就开启了.

然后目录会多出twistd.pid和setup.py,build目录.
然后部署scrapy爬虫,下载scrapyd-client
pip install scrapyd-client
安装完scrapy-client之后,配置一下scrapy.cfg
在deploy后面加上名字[deploy:***]可以自己定义,window会出现scrapyd-deploy无法使用。
解决办法:在虚拟环境的Scripts中新建scrapyd-deploy.bat文件
写入
@echo off
"自己虚拟环境的全路径\Scripts\python.exe" "自己虚拟环境全路径\Scripts\scrapyd-deploy" %*
就可以通过scrapyd-deploy
参数解释
target :depoly 后面的名称(自己之前写的)
project :建议使用项目名字(应该是可以不用)
version 版本,自己定义,不写为当前时间
ex
scrapyd-deploy 100 -p taobao --version 1.0
scrapy部署这里不多说了,网上自己搜索.要是部署没有出错的话,我们scrapyd的api查看项目状态.
浏览器输入http://localhost:6800/listprojects.json查看爬虫项目信息
![]()
这里面有一个很重要的信息,就是这个projects的名字.我一开始部署完之后,并不知project的名字是是什么,导致后来找了很久,我们动态传值的时候,要以字典的形式传这个projects的值
通过requests传值如下

可以使用scrapy-djangoitem将scrapy的item存入到django的数据库中,scrapy框架的items.py和pipelines.py都很简单地写
ex
from scrapy_djangoitem import DjangoItem
from taobao.models import *
class ProductName(DjangoItem):
django_model = ProductName
class JDProductsItem(DjangoItem):
django_model = JDProductsItem
class JDCommentSummaryItem(DjangoItem):
django_model = JDCommentSummaryItem
class JDHotCommentTagItem(DjangoItem):
django_model = JDHotCommentTagItem
class JDCommentItem(DjangoItem):
django_model = JDCommentItem
在pipelines.py中直接用item.save()就可以代替一大串的sql语句
if isinstance(item, ProductName):
try:
item.save()
# cur = self.conn.cursor()
# sql = '''insert into product values (%s,%s,%s,%s,%s,%s,%s)'''
# self.conn.ping(reconnect=True)
# cur.execute(sql,(item['productid'],item['category'],item['description'],item['name'],item['imgurl'],item['reallyPrice'],item['url']))
# cur.close()
# self.conn.commit()
# self.conn.close()
except Exception as e:
print(e)
elif isinstance(item, JDProductsItem):
try:
item.save()
# cur = self.conn.cursor()
# sql = '''insert into productlink values (%s,%s)'''
# self.conn.ping(reconnect=True)
# cur.execute(sql,(item['id'], item['imgurl']))
# cur.close()
# self.conn.commit()
# self.conn.close()
except Exception as e:
print(e)
此外国外有人做一个django-dynamic-scraper的项目,有兴趣的同学,可以进行尝试一下.
2020/5/5更新
在看了一下scrapy文档和scrapyd的代码之后,可以不使用django web框架
在scrapy文档中
添加链接描述
是支持web service的,但是我想这个会比较简单。
而在scrapyd中,scrapyd是基于python的Twisted异步事务框架的。
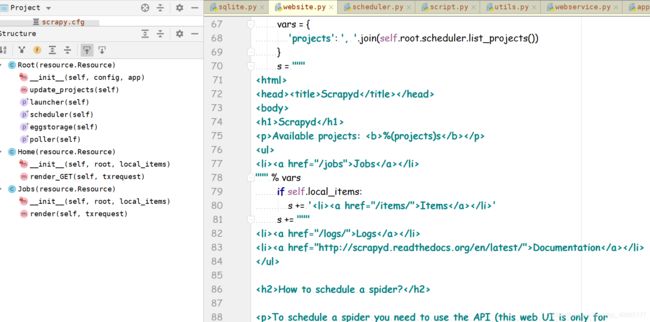
在找到源码中相应的代码。
webservice.py包含了web的所有api

website.py这是web的入口

所以我们也就可以用Twisted来代替django,写出相应的web服务,Twisted没有相应的model模块,大家可以使用别的代替如(我之前用过的peewee模块,或者可以参考廖雪峰教程中自己写出来)
