SIGIR 2020最佳论文公布,清华大学揽多个奖项,大三学生摘得最佳短论文奖
7月29日晚,第43届国际 “信息检索研究与发展” 年会(SIGIR - The International ACM SIGIR Conference on Research and Development in Information Retrieval)最佳论文正式公布。
本届会议最佳论文奖由康奈尔大学Thorsten Joachims团队获得,共同一作是Marco Morik和Ashudeep Singh。
清华大学本次获得了多个奖项:最佳论文荣誉提名奖由清华大学张帆(一作)等获得,智源学者刘奕群也是作者之一;两个最佳短论文奖也都被清华大学摘取,第一作者分别是常健新和于是。值得一提的是,于是目前是大三学生,智源学者刘知远是指导老师之一。
作为 CCF 推荐的 A 类国际学术会议,SIGIR 历来都是互联网业内关注的焦点,会议覆盖了信息检索领域相关的各类前沿成果,包括基础理论、算法应用以及评估分析。本届SIGIR 2020(会议官网:https://sigir.org/sigir2020/)于7月25日-30日在线上召开,通过智源社区向全球同步直播(点击「阅读原文」观看回放)。
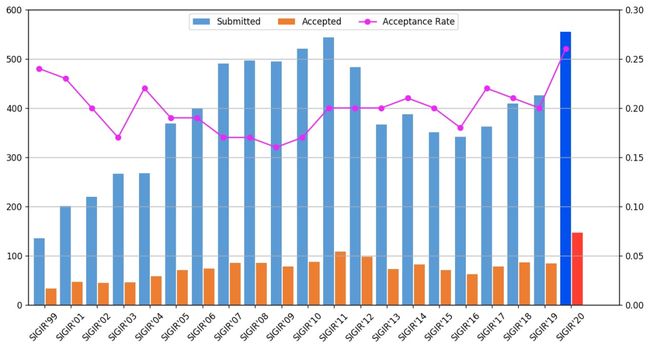
本次会议共收到论文投稿总数 1180 篇,总共录取 340 篇。其中,长文投稿555 篇,最终录用 147 篇,录用率约 26%;短文投稿507 篇,最终录用 152 篇,录取率约 30%。这是SIGIR继2011年于北京刷新该会议论文投稿记录后,时隔9年回到中国,投稿量和录取率再创新高。来自 32 个国家的 1221 名作者为录用论文做出了贡献。
1. 最佳论文奖

论文:Controlling Fairness and Bias in Dynamic Learning-to-Rank
论文地址:https://sigir-schedule.baai.ac.cn/poster/fp0069
本文作者:Marco Morik, Ashudeep Singh, Jessica Hong, Thorsten Joachims。其中Thorsten Joachims教授是康奈尔大学计算机系的教授,ACM Fellow,多年致力于无偏排序(unbiased ranking)的研究,在数据挖掘相关的顶级会议如KDD、SIGIR、WWW、WSDM、CIKM发表多篇相关著作,其中很多工作都颇具影响力,比如发表在SIGIR 2005上的Accurately interpreting clickthrough data as implicit feedback可以称得上是无偏排序的开山之作之一。
论文介绍:
排序算法在很多在线平台将用户和项目(比如新闻产品音乐等)进行匹配,在用户和项目双边考虑中,用户不仅评估排序算法的效益,而且排序算法本身也影响了项目提供端(比如出版商)的效益(比如曝光度)。目前的排序算法中并没有考虑到在项目提供端的效益。基于这些考虑,本文提出了显性的基于组(比如相同出版商出版的文章)的公平排序算法。在保证公平的同时,本文的算法可以有效的优化排序算法的效果。
具体来说,本文主要研究了动态学习排序算法,在算法设计中,有两个点需要重点考虑:一是排序系统本身会造成偏差(bias),这是由于排序高的项目可以获得更多的反馈,这样会造成这次排序高的项目在下次排序中排序也会高(richer-get-richer)。
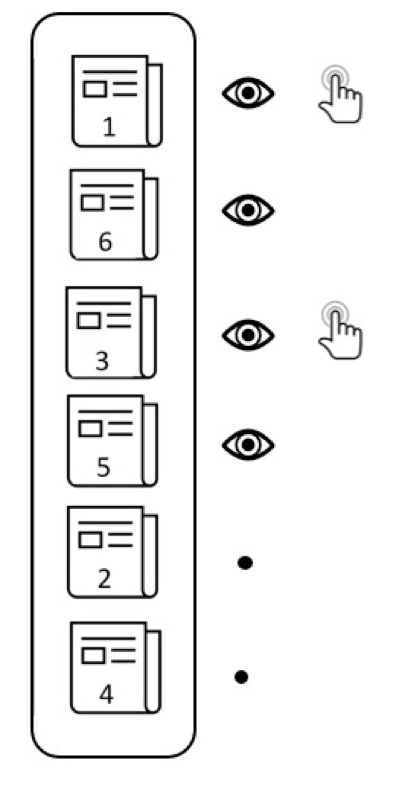
偏差示意图(排序越高反馈越多)
二是排序系统本身是曝光度裁决者的身份,会直接影响曝光度和项目提供端相关收入,所以在排序过程中,需要考虑项目的公平性(fairness),比如项目曝光度(exposure)需要相关度(relevance)正比。
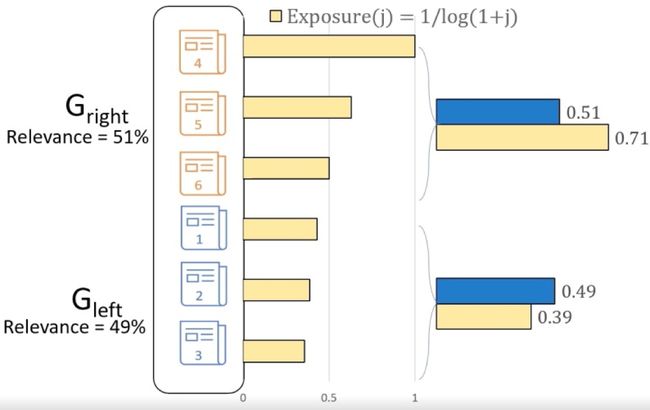 公平性示意图(图中左右排序项目的曝光度与相关度并不是正比的,所以是不公平的)
公平性示意图(图中左右排序项目的曝光度与相关度并不是正比的,所以是不公平的)
出于这种考虑,为了解决偏差问题,本文建立一个基于IPS(Inverse propensity weighting)的非偏估计机制(unbiased estimator)来估计文档的条件相关度,这种非偏估计机制可以根据有偏的点击,估计无偏的条件相关度。为了解决动态排序中的公平问题,本文采用了P-controller(proportional controller)的形式,动态地调整排序策略,使得之前曝光程度不够的文档能够得到更有效的曝光。该方法被证明可以在平均相关度估计收敛的情况下,使得不同组间曝光度-相关度比例的差距以一定的比例收敛到零。为了验证提出算法的鲁棒性和效果,作者分别在半生成的新闻数据集和真实的电影数据集上进行了实验验证。该算法不仅可以取得良好的排序效果和公平性,并且非常高效,容易实现。下图为本文提出算法和线性规划算法的比较。
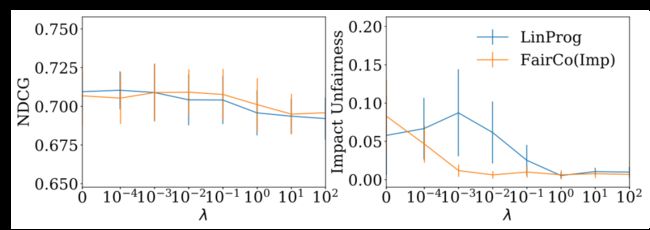 实验结果图(左图排序算法表现,右图公平表现)
实验结果图(左图排序算法表现,右图公平表现)
整理:上海交通大学 张伟楠副教授
博士生晋嘉睿、戴心仪
2. 最佳论文荣誉提名奖

论文:Models Versus Satisfaction: Towards a Better Understanding of Evaluation Metrics
论文地址:https://sigir-schedule.baai.ac.cn/poster/fp0128
这篇文章作者来自清华大学计算机系,作者包括张帆,毛佳昕,刘奕群,谢晓晖,马为之,张敏,马少平等人。
论文介绍:
搜索评价一直都是信息检索领域的一个核心问题,为了使评价的结果更符合用户的真实体验,现有的搜索离线评价指标在设计时都会基于一定的用户模型。因此,评价指标的有效性同时包括两个方面:
评价指标背后的用户模型能否准确地拟合用户行为;
评价指标的评价分数能否有效地衡量用户满意度。
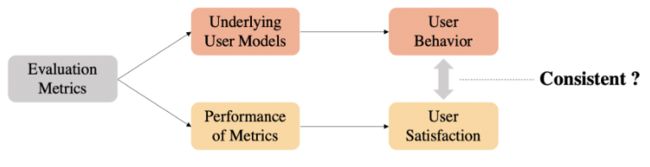
基于用户模型的评价指标的两个方面 [Wicaksono and Moffat, 2020][1]
然而,现有工作很少去探究评价指标在这两方面表现的一致性。为了对基于用户模型的评价指标有更深入的理解,我们在本文中对评价指标进行了更细致的探究。
通过在一个公开数据集[2]和我们收集的数据集[3]上的实验,我们验证了基于用户模型的评价指标在拟合用户行为和衡量用户满意度两方面的一致性,基于用户点击行为校准的评价指标与基于用户满意度校准的评价指标的表现是非常接近的。此外,我们也验证了评价指标参数的可靠性,相比用户满意度,利用用户行为拟合评价指标得到的参数更加稳定,受训练数据采样的影响较小。最后,我们对训练数据规模进行了探究,利用小规模的用户行为数据对评价指标进行校准,已经能够使评价指标在衡量用户满意度上取得较好的效果。
我们的实验结果为现有的“基于用户行为日志拟合评价指标参数”这一方法论提供了经验依据。用户满意度反馈在实际搜索中难以收集,而我们通过用户行为日志对评价指标的参数进行拟合,得到的评价指标能够很好地对用户使用搜索系统的满意度进行衡量。
整理:清华大学 张帆
3. 最佳短论文奖 I

论文:Bundle Recommendation with Graph Convolutional Networks
论文地址:https://sigir-schedule.baai.ac.cn/poster/sp0017
本文来自于清华大学电子系金德鹏教授与李勇副教授的研究团队,第一作者和第二作者分别为团队中的硕士生常健新与博士生高宸。中国科学技术大学何向南教授参与了该论文的合作和指导。
论文介绍:
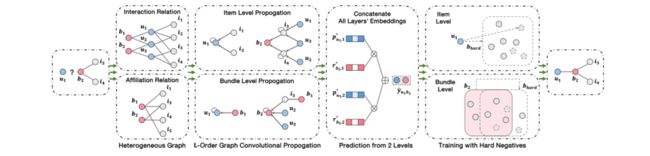
物品组合是在功能或属性上相似或互补的多个物品,用于同时满足用户在某个场景下的复杂需求。目前,物品组合在电子商务和各类内容平台上日益流行,使得物品组合推荐变成一项重要个性化推荐任务。
该论文提出了一个基于图卷积神经网络的物品组合推荐方法,解决了物品组合推荐面临的挑战以及现有工作的诸多局限性。具体而言,该方法将用户、物品、物品组合三者统一为异构图,以此显式地建模用户与物品组合/单一物品的交互关系、以及物品组合与单一商品的从属关系。在此异构图上,提出单物品级别与物品组合级别的图卷积网络层,分别捕获单一物品交互数据和物品组合交互数据中的协同过滤信号,同时也刻画了物品组合蕴含的替代性、互补性等语义信息以及物品组合之间的相似性。
进一步地,考虑到用户在选择物品组合时与选择单一物品时的不同动机,该方法提出了一种基于难负样本的采样学习方法,通过在训练过程中构建难负样本,以学习用户、单个物品、物品组合的细粒度特征。
总而言之,该方法利用图神经网络从复杂的图结构中学习了用户、物品、物品组合的高阶连通性,解决了已有方法仅能提取简单协同过滤信号的关键缺陷。该论文在多个真实数据集进行了广泛的实验,提出的方法在多项推荐精准度指标上达到了state-of-the-art,同时该方法在应对数据稀疏性等问题上亦取得优异表现。
整理:清华大学 常健新
4. 最佳短论文奖 II

论文:Few-Shot Generative Conversational Query Rewriting
论文地址:https://sigir-schedule.baai.ac.cn/poster/sp0142
本文由来自清华大学师生与Microsoft Research AI学者合作完成。第一作者是清华大学计算机系大三本科生于是同学。本文由清华大学刘知远和Microsoft Research AI高级研究员熊辰炎共同指导。
论文介绍:
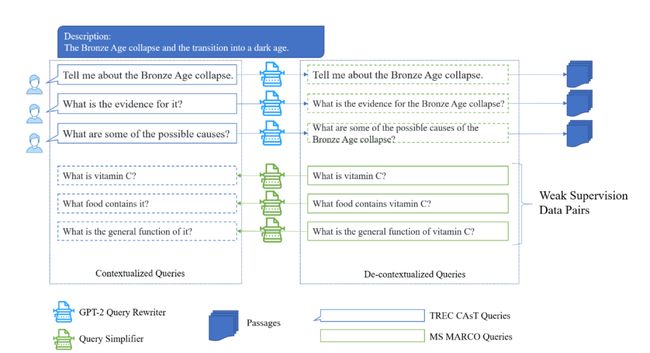
现代信息检索需要精准理解用户查询意图,提升用户查询体验。近年来,对话式检索由于能够更好地捕捉用户意图,得到研究者越来越多的关注。在对话场景中,用户提出的查询问题是人机交互的重要方式,然而由于用户在对话中做出的原始查询缺少上下文语境,现有的信息检索系统无法直接进行有效搜索。
解决该问题的思路是,构建自动的查询改写系统,根据人机对话历史信息,将用户查询改写成信息检索系统能够有效处理的标准化查询。基于这种思路,本论文提出了一种小样本学习方法,能够有效提升对话式检索中的查询重写效果。具体地,分别采取基于规则和自我监督学习的方式生成弱监督数据,用于微调预训练模型GPT-2增强对于用户问题的理解和改写能力。
该模型在对话式检索任务TREC Conversational Assistance Track 2019中,与当前最好的问题改写模型相比准确率提高了12%。在无标注语料训练场景中,该模型准确率仍与TREC CAsT 2019最好的模型效果相当。这些实验表明,所提出的方法能够有效捕捉对话上下文信息,从而帮助提升对话式检索的效果。
整理:清华大学 于是
5. Test of Time Award

论文:Learning to Recommend with Social Trust Ensemble
论文地址:https://dl.acm.org/doi/10.1145/1571941.1571978
本文作者:Hao Ma,Irwin King,Michael R. Lyu,来自香港中文大学。
论文介绍:
推荐系统作为信息过滤领域不可缺少的技术,近年来在学术界和工业界得到了广泛的研究和发展。然而,目前大多数的推荐系统都存在如下问题:(1)用户项矩阵数据量大且稀疏,严重影响了推荐质量。因此,大多数推荐系统都无法有效处理使用频次较少的用户。(2) 传统的推荐系统假设所有的用户都是独立、分布一致的,而忽略了用户之间的联系,这与现实世界中的推荐是不一致的。
为了更准确、真实地对推荐系统进行建模,作者提出了一种新的概率因子分析框架,将用户的喜好和他们所信任朋友的偏好自然地融合在一起。在这个框架中,创造了社会信任集合(Social Trust Ensemble)这一术语,来表达社会信任对推荐系统的限制。
复杂度分析表明,作者的方法可以适用于非常大的数据集,因为它与观测值的数量成线性关系,而实验结果表明改方法比现有其他方法有更好的性能。
整理:智源社区 常政
6. Test of Time Award Honorable Mention I

论文:A User Browsing Model to Predict Search Engine Click Data from Past Observations
论文地址:https://dl.acm.org/doi/10.1145/1390334.1390392
本文作者:Georges Dupret,Benjamin Piwowarski。两位作者都来自雅虎研究院。
论文介绍:
搜索引擎点击日志提供了宝贵的相关信息来源,但这些信息是有偏差的,因为忽略了用户点击前后在结果列表中实际看到的文档;否则完全可以通过简单的计数来估计文档的相关性。
本文提出了一组关于用户浏览行为的假设,这些假设使得能够估计文档被看到的概率,从而提供文档相关性的无偏估计。为了训练、测试和比较模型与文献中描述的其他最佳替代方案,作者收集了大量真实数据,并进行了广泛的交叉验证实验。结果显示,其解决方案性能远远优于以前的模型。
伴随而来的其他好处是,可以深入了解用户的浏览行为,并将其与Joachims等人[4]的眼动实验的结论进行比较。特别是,作者的发现证实了用户几乎总是在点击文档后立即浏览该文档,而且还解释了为什么位于非常相关的文档之后的内容会被更频繁地点击。
整理:智源社区 贾伟
7. Test of Time Award Honorable Mention II

论文:Selecting Good Expansion Terms for Pseudo-Relevance Feedback
论文地址:https://dl.acm.org/doi/10.1145/1390334.1390377
本文作者:Guihong Cao,Jian-Yun Nie,Jianfeng Gao(高剑峰),Stephen Robertson。作者分别来自加拿大蒙特利尔大学、美国雷德蒙德微软研究院和英国剑桥微软研究院。
论文介绍:
伪相关性反馈(Pseudo-relevance feedback)假设,在伪反馈文档(pseudo-feedback documents)中最频繁的术语对检索是有用的。
在这项研究中,作者重新检验了这一假设,结果证明这个假设并不成立,传统方法中确定的许多扩展术语事实上与查询是无关的,且对检索有害。
研究还表明,仅根据反馈文档和整个集合中的分布,不能将良好的和不良的扩展术语区分开来。作者建议整合一个术语分类过程(term classification process),从而来预测扩展术语的有用性,可以在这个过程中集成多个其他功能。
作者对三个TREC集合的实验表明,使用术语分类可以大大提高检索效率。此外还表明,好的术语,应当能够根据它们可能会对检索效率产生的影响直接识别出来,换句话说,使用监督学习而不是无监督学习。
整理:智源社区 贾伟
参考文献:
[1] Wicaksono A F, Moffat A. Metrics, User Models, and Satisfaction[C]//Proceedings of the 13th International Conference on Web Search and Data Mining. 2020: 654-662.
[2] Chen Y, Zhou K, Liu Y, et al. Meta-evaluation of online and offline web search evaluation metrics[C]// Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval. 2017: 15-24.
[3] http://www.thuir.cn/tiangong-ss-fsd/
[4] T. Joachims, L. Granka, B. Pan, H. Hembrooke, F. Radlinski, and G. Gay. Evaluating the accuracy of implicit feedback from clicks and query reformulations in web search. ACM Transactions on Information Systems (TOIS), 25(2), 2007.
附:SIGIR近5年最佳论文
2019 | Variance Reduction in Gradient Exploration for Online Learning to Rank
作者:Huazheng Wang,Sonwoo Kim,Eric McCord-Snook,Qingyun Wu,Hongning Wang
链接:https://dl.acm.org/citation.cfm?id=3331264
2018 | Should I Follow the Crowd? A Probabilistic Analysis of the Effectiveness of Popularity in Recommender Systems
作者:Rocío Cañamares,Pablo Castells
链接:https://dl.acm.org/citation.cfm?id=3210014
2017 | BitFunnel: Revisiting Signatures for Search
作者:Bob Goodwin,Michael Hopcroft,Dan Luu,Alex Clemmer,Mihaela Curmei,Sameh Elnikety,Yuxiong He
链接:https://dl.acm.org/citation.cfm?doid=3077136.3080789
2016 | Understanding Information Need: an fMRI Study
作者:Yashar Moshfeghi,Peter Triantafillou,Frank E. Pollick
链接:http://dx.doi.org/10.1145/2911451.2911534
2015 | QuickScorer: A Fast Algorithm to Rank Documents with Additive Ensembles of Regression Trees
作者:Claudio Lucchese,Franco Maria Nardini,Salvatore Orlando,Raffaele Perego,Nicola Tonellotto,Rossano Venturini
链接:http://dx.doi.org/10.1145/2766462.2767733
编辑:智源社区 王炜强

SIGIR 2020线上会议平台由智源社区提供。
关于我们
北京智源人工智能研究院(Beijing Academy of Artificial Intelligence,简称BAAI)成立于2018年11月,是在科技部和北京市委市政府的指导和支持下,由北京市科委和海淀区政府推动成立的新型研发机构。
//智源研究院简介
///
学术思想 | 基础理论 | 顶尖人才 | 企业创新 | 发展政策
