python爬虫scrapy框架
Scrapy 框架
关注公众号“轻松学编程”了解更多。
一、简介
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted(其主要对手是Tornado)多线程异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
二、Scrapy架构图(绿线是数据流向)

- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
三、Scrapy的运作流程
代码写好,程序开始运行…
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
四、安装
方式1:到https://www.lfd.uci.edu/~gohlke/pythonlibs/搜索相关的库下载,然后pip安装
方式2:在命令终端直接pip安装
1、安装wheel
pip install wheel
2、安装lxml
pip install lxml
3、安装pyopenssl
pip install pyopenssl
4、安装Twisted
pip install Twisted
5、安装pywin32
pip install pywin32
6、安装scrapy
pip install scrapy
1、Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
2、Windows 安装方式
-
Python 2 / 3
-
升级pip版本:
pip install --upgrade pip -
通过pip 安装 Scrapy 框架
pip install Scrapy
3、Ubuntu 需要9.10或以上版本安装方式
-
Python 2 / 3
-
安装非Python的依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev -
通过pip 安装 Scrapy 框架
sudo pip install scrapy
安装后,只要在命令终端输入 scrapy,提示类似以下结果,代表已经安装成功
具体Scrapy安装流程参考:http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes里面有各个平台的安装方法
五、制作 Scrapy 爬虫
一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
六、入门案例
1. 目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
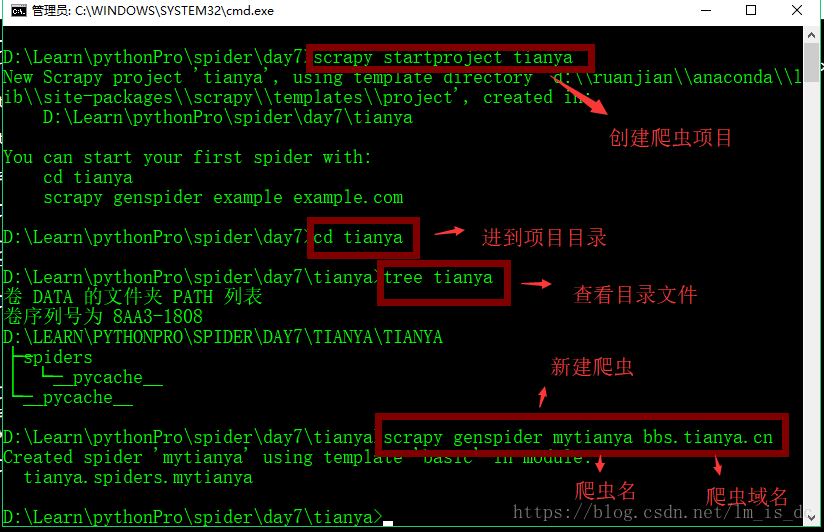
2. 新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
- 其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:

下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
3. 明确目标(mySpider/items.py)
我们打算抓取:http://bbs.tianya.cn/post-140-393968-1.shtml 网站里的邮箱。
- 打开mySpider目录下的items.py
- Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
- 可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。
- 接下来,创建一个TianyaItem类,和构建item模型(model)。
import scrapy
class TianyaItem(scrapy.Item):
email = scrapy.Field()
4. 制作爬虫 (spiders/mytianya.py)
爬虫功能要分两步:
4.1 爬数据(如上图)
- 在当前目录下输入命令
scrapy genspider mytianya "bbs.tianya.cn"
- 打开 mySpider/spider目录里的 mytianya .py,默认增加了下列代码:
import scrapy
import re
from tianya import items
class MytianyaSpider(scrapy.Spider):
name = 'mytianya'
allowed_domains = ['bbs.tianya.cn']
start_urls = ['http://bbs.tianya.cn/post-140-393977-1.shtml']
def parse(self, response):
pass
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
- 将start_urls的值修改为需要爬取的第一个url
4.2 修改parse()方法
def parse(self, response):
content = response.body.decode('utf-8')
# print(content)
# [email protected]
# 邮箱正则
emailre = "[a-z0-9_]+@[a-z0-9]+\.[a-z]{2,4}"
#忽略大小写
emailList = re.findall(emailre,content,re.I)
print('*************',emailList)
# 读取数据方式1
# myemail = []
# for email in emailList:
# # 实例一个存储对象
# item = TianyaItem()
# item['email'] = email
# myemail.append(item)
#
# return myemail
# 读取数据方式2,推荐使用,使用生成器内存消耗低
item = TianyaItem()
for email in emailList:
item['email'] = email
# 生成器 range(1,231)
yield item
然后运行一下看看,在mySpider目录下执行:
scrapy crawl mytianya
5. 取数据
- 通过管道pipelines.py来取数据。我们暂时先不处理管道,后面会详细介绍。
6.保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
#保存为json格式
scrapy crawl mytianya -o mytianya.json
#保存为csv格式
scrapy crawl mytianya -o mytianya.csv
#保存为xml格式
scrapy crawl mytianya -o mytianya.xml
七、Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython)
1、启动Scrapy Shell
进入项目的根目录,执行下列命令来启动shell:
scrapy shell "https://hr.tencent.com/position.php?&start=0#a"
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及Selector 对象 (对HTML及XML内容)。
- 当shell载入后,将得到一个包含response数据的本地 response 变量,输入
response.body将输出response的包体,输出response.headers可以看到response的包头。 - 输入
response.selector时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用response.selector.xpath()或response.selector.css()来对 response 进行查询。 - Scrapy也提供了一些快捷方式, 例如
response.xpath()或response.css()同样可以生效(如之前的案例)。
八、Selectors选择器
Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
- extract(): 序列化该节点为Unicode字符串并返回list
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
- re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
response.xpath('//title')
九、Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃还是存储。以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
1、编写item pipeline
编写item pipeline很简单,item pipiline组件是一个独立的Python类,其中process_item()方法必须实现:
import something
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
2、完善之前的案例:
2.1 item写入txt文件
以下pipeline将所有(从所有’spider’中)爬取到的item,存储到一个独立地txt文件
class TianyaPipeline(object):
# 打开爬虫时调用,只调用一次
def open_spider(self,spider):
# 把email写进txt文件
self.f = open('tianyaEmail.txt','a+',encoding='utf-8')
def process_item(self, item, spider):
#存储到txt
self.f.write(str(item['email'])+'\n')
self.f.flush()
return item
# 关闭爬虫时,只调用一次
def close_spider(self,spider):
self.f.close()
3、启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置,就像下面这个例子:
ITEM_PIPELINES = {
'tianya.pipelines.TianyaPipeline': 300,
}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
4、重新启动爬虫:
scrapy crawl mytianya
也可以在项目目录下创建一个start.py来启动爬虫:
import scrapy.cmdline
def main():
scrapy.cmdline.execute(['scrapy','crawl','mytianya'])
if __name__ == '__main__':
main()
十、Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
__init__(): 初始化爬虫名字和start_urls列表
start_requests() 调用make_requests_from url():生成Requests对象交给Scrapy下载并返回response
parse(): 解析response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
1、源码参考
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
2、主要属性和方法
-
name
定义spider名字的字符串。
例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
-
allowed_domains
包含了spider允许爬取的域名(domain)的列表,可选。
-
start_urls
初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
-
start_requests(self)
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。
当spider启动爬取并且未指定start_urls时,该方法被调用。
-
parse(self, response)
当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。
-
log(self, message[, level, component])
使用 scrapy.log.msg() 方法记录(log)message。 更多数据请参见logging
十一、案例:腾讯招聘网自动翻页采集
- 创建一个新的项目:
scrapy startproject tencent
cd tencent
- 创建一个新的爬虫:
scrapy genspider mytencent hr.tencent.com
- 编写items.py
获取职位名称、详细信息、
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称 职位类别 人数 地点 发布时间
jobName = scrapy.Field()
jobType = scrapy.Field()
peopleNum = scrapy.Field()
address = scrapy.Field()
jobTime = scrapy.Field()
- 编写mytencent.py(爬取多页)
#爬取多页
import scrapy
from scrapy.spiders import CrawlSpider,Rule # 提取超链接的规则
from scrapy.linkextractor import LinkExtractor # 提取超链接
# 使用翻页,要继承CrawlSpider
from tencent.tencent.items import TencentItem
class MytencentSpider(CrawlSpider):
name = 'mytencent' #爬虫名称
allowed_domains = ['hr.tencent.com'] #爬取域名限制
start_urls = ['https://hr.tencent.com/position.php?keywords=&tid=0&start=10#a']
'''
Rule()
link_extractor, 链接
callback=None, 回调,符合LinkExtractor,就调用callback方法
follow=None, 跟踪,如果为True,就跟踪爬取,如果False就只调用一次
'''
'''
LinkExtractor() 提取链接的
allow=(正则), 允许,符合正则则提取
deny=(正则), 符合正则不提取
'''
# 爬取所有页
# allow=("start=(\d+)#a"))
# 这是一个正则表达式,必须要匹配这个正则表达式(或正则表达式列表)
# 的URL才会被提取,如果没有给出(或为空), 它会匹配所有的链接。
rules = [Rule(LinkExtractor(allow=("start=(\d+)#a")),callback='get_parse',follow=True)]
#使用Rule()后,就不能用parse()
# def parse(self, response):
# pass
def get_parse(self, response):
jobList = response.xpath('//tr[@class="even"] | //tr[@class="odd"]')
# 存储对象
item = TencentItem()
for job in jobList:
# extract()提取文本,返回一个列表
jobName = job.xpath('./td[1]/a/text()').extract()[0]
jobType = job.xpath('./td[2]/text()').extract()[0]
peopleNum = job.xpath('./td[3]/text()').extract()[0]
address = job.xpath('./td[4]/text()').extract()[0]
jobTime = job.xpath('./td[5]/text()').extract()[0]
print(jobName, jobTime, peopleNum, address, jobType)
item['jobName'] = jobName
item['jobType'] = jobType
item['peopleNum'] = peopleNum
item['address'] = address
item['jobTime'] = jobTime
yield item
- 编写pipeline.py文件(保存进MySQL数据库)
#保存进MySQL数据库
import pymysql
class TencentPipeline(object):
def __init__(self):
#连接数据库
self.conn = None
#游标
self.cur = None
# 打开爬虫时调用,只调用一次
def open_spider(self,spider):
self.conn = pymysql.connect(host='127.0.0.1',
user='root',
password="123456",
database='tjob',
port=3306,
charset='utf8')
self.cur = self.conn.cursor()
def process_item(self, item, spider):
clos,value = zip(*item.items())
sql = "INSERT INTO `%s`(%s) VALUES (%s)" % ('tencentjob',
','.join(clos),
','.join(['%s'] * len(value)))
self.cur.execute(sql, value)
self.conn.commit()
return item
def close_spider(self, spider):
self.cur.close()
self.conn.close()
- 在 setting.py 里设置ITEM_PIPELINES
ITEM_PIPELINES = {
"mySpider.pipelines.TencentJsonPipeline":300
}
-
执行爬虫:
scrapy crawl mytencent
十二、自动翻页爬取原理解析
1、 parse()方法的工作机制:
1. 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。
2. scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
3. 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回
错误信息。
4. scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放
到队列里,然后接着从生成器里获取;
5. 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
6. parse()方法作为回调函数(callback)赋值给了Request,
指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse)
7. Request对象经过调度,执行生成 scrapy.http.response()的响应对象,
并送回给parse()方法,直到调度器中没有Request(递归的思路)
8. 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
9. 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items。
10. 这一切的一切,Scrapy引擎和调度器将负责到底。
2、CrawlSpiders
通过下面的命令可以快速创建 CrawlSpider模板 的代码:
scrapy genspider -t crawl mytencentCrawl hr.tencent.com
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
2.1 源码参考
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
#首先调用parse()来处理start_urls中返回的response对象
#parse()则将这些response对象传递给了_parse_response()函数处理,并设置回调函数为parse_start_url()
#设置了跟进标志位True
#parse将返回item和跟进了的Request对象
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
#处理start_url中返回的response,需要重写
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
#从response中抽取符合任一用户定义'规则'的链接,并构造成Resquest对象返回
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
#抽取之内的所有链接,只要通过任意一个'规则',即表示合法
for n, rule in enumerate(self._rules):
links = [l for l in rule.link_extractor.extract_links(response) if l not in seen]
#使用用户指定的process_links处理每个连接
if links and rule.process_links:
links = rule.process_links(links)
#将链接加入seen集合,为每个链接生成Request对象,并设置回调函数为_repsonse_downloaded()
for link in links:
seen.add(link)
#构造Request对象,并将Rule规则中定义的回调函数作为这个Request对象的回调函数
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=n, link_text=link.text)
#对每个Request调用process_request()函数。该函数默认为indentify,即不做任何处理,直接返回该Request.
yield rule.process_request(r)
#处理通过rule提取出的连接,并返回item以及request
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
#解析response对象,会用callback解析处理他,并返回request或Item对象
def _parse_response(self, response, callback, cb_kwargs, follow=True):
#首先判断是否设置了回调函数。(该回调函数可能是rule中的解析函数,也可能是 parse_start_url函数)
#如果设置了回调函数(parse_start_url()),那么首先用parse_start_url()处理response对象,
#然后再交给process_results处理。返回cb_res的一个列表
if callback:
#如果是parse调用的,则会解析成Request对象
#如果是rule callback,则会解析成Item
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
#如果需要跟进,那么使用定义的Rule规则提取并返回这些Request对象
if follow and self._follow_links:
#返回每个Request对象
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, basestring):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
CrawlSpider继承于Spider类,除了继承过来的属性外(name、allow_domains),还提供了新的属性和方法:
2.2 LinkExtractors
class scrapy.linkextractors.LinkExtractor
Link Extractors 的目的很简单: 提取链接。
每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象。
Link Extractors要实例化一次,并且 extract_links 方法会根据不同的 response 调用多次提取链接。
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
主要参数:
allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。deny:与这个正则表达式(或正则表达式列表)匹配的URL一定不提取。allow_domains:会被提取的链接的domains。deny_domains:一定不会被提取链接的domains。restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。
#####2.3 rules
在rules中包含一个或多个Rule对象,每个Rule对爬取网站的动作定义了特定操作。如果多个rule匹配了相同的链接,则根据规则在本集合中被定义的顺序,第一个会被使用。
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
-
link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。 -
callback: 从link_extractor中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。注意:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
-
follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False。 -
process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。 -
process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)
十三、settings.py配置
1、robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。robots.txt文件是一个文本文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
实例分析:淘宝网的 robots.txt文件
禁止robots协议将 ROBOTSTXT_OBEY = True改为False
2、Logging
Scrapy提供了log功能,可以通过 logging 模块使用。
可以修改配置文件settings.py,任意位置添加下面两行,效果会清爽很多。
LOG_ENABLED = True # 开启
LOG_FILE = "TencentSpider.log" #日志文件名
LOG_LEVEL = "INFO" #日志级别
2.1 Log levels
- Scrapy提供5层logging级别:
- CRITICAL - 严重错误(critical)
- ERROR - 一般错误(regular errors)
- WARNING - 警告信息(warning messages)
- INFO - 一般信息(informational messages)
- DEBUG - 调试信息(debugging messages)
#####2.2 logging设置
通过在setting.py中进行以下设置可以被用来配置logging:
-
LOG_ENABLED默认: True,启用logging
-
LOG_ENCODING默认: ‘utf-8’,logging使用的编码
-
LOG_FILE默认: None,在当前目录里创建logging输出文件的文件名
-
LOG_LEVEL默认: ‘DEBUG’,log的最低级别
-
LOG_STDOUT默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print “hello” ,其将会在Scrapy log中显示。
2.3 日志模块已经被scrapy弃用,改用python自带日志模块
#在mytencent.py下写
import logging
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s" # 设置输出格式
DATE_FORMAT = "%Y/%m/%d %H:%M:%S" # 设置时间格式
logging.basicConfig(filename='tencent.log', filemode='a+', format=LOG_FORMAT, datefmt=DATE_FORMAT)
class MytencentSpider(CrawlSpider):
name = 'mytencent' #爬虫名称
allowed_domains = ['hr.tencent.com'] #爬取域名限制
start_urls = ['https://hr.tencent.com/position.php?keywords=&tid=0&start=10#a']
logging.info('开始爬虫')
#logging.error('出错了a')
#logging.warning('错误')
...
3 setting.py 设置抓取间隔
DOWNLOAD_DELAY = 0.25 #设置下载间隔为250ms
后记
【后记】为了让大家能够轻松学编程,我创建了一个公众号【轻松学编程】,里面有让你快速学会编程的文章,当然也有一些干货提高你的编程水平,也有一些编程项目适合做一些课程设计等课题。
也可加我微信【1257309054】,拉你进群,大家一起交流学习。
如果文章对您有帮助,请我喝杯咖啡吧!
公众号


关注我,我们一起成长~~