python 决策回归树
本文代码以及相应的数据集
决策回归树主要用CART算法来实现。
CART算法:CART算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,不纯度越低,特征越好。比较基尼系数和熵模型的表达式,二次运算比对数简单很多。尤其是二分类问题,更加简单。CART分类树算法对连续值的处理,是使用划分点将连续的特征离散化,在选择划分点时,分类模型是基于基尼系数,回归模型是基于和方法度量。本实验采用的是最小二乘回归树生成算法,算法如下图所示。

结果:
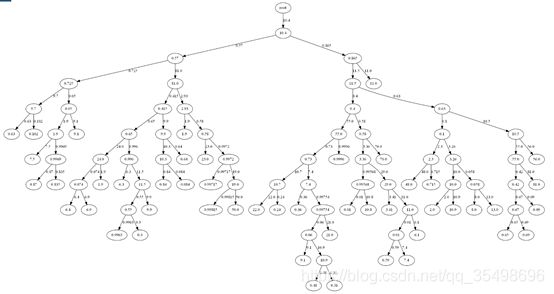
代码实现:
"""
CART+最小二乘法构建CART回归树
"""
import numpy as np
import matplotlib.pyplot as plt
from graphviz import Digraph
class node:
def __init__(self, fea=-1, val=None, res=None, right=None, left=None):
self.fea = fea
self.val = val
self.res = res
self.right = right
self.left = left
class CART_REG:
def __init__(self, epsilon=0.1, min_sample=10):
self.epsilon = epsilon
self.min_sample = min_sample
self.tree = None
def err(self, y_data):
# 子数据集的输出变量y与均值的差的平方和
return y_data.var() * y_data.shape[0]
def leaf(self, y_data):
# 叶节点取值,为子数据集输出y的均值
return y_data.mean()
def split(self, fea, val, X_data):
# 根据某个特征,以及特征下的某个取值,将数据集进行切分
set1_inds = np.where(X_data[:, fea] <= val)[0]
set2_inds = list(set(range(X_data.shape[0]))-set(set1_inds))
return set1_inds, set2_inds
def getBestSplit(self, X_data, y_data):
# 求最优切分点
best_err = self.err(y_data)
best_split = None
subsets_inds = None
for fea in range(X_data.shape[1]):
for val in X_data[:, fea]:
set1_inds, set2_inds = self.split(fea, val, X_data)
if len(set1_inds) < 2 or len(set2_inds) < 2: # 若切分后某个子集大小不足2,则不切分
continue
now_err = self.err(y_data[set1_inds]) + self.err(y_data[set2_inds])
if now_err < best_err:
best_err = now_err
best_split = (fea, val)
subsets_inds = (set1_inds, set2_inds)
return best_err, best_split, subsets_inds
def buildTree(self, X_data, y_data):
# 递归构建二叉树
if y_data.shape[0] < self.min_sample:
return node(res=self.leaf(y_data))
best_err, best_split, subsets_inds = self.getBestSplit(X_data, y_data)
if subsets_inds is None:
return node(res=self.leaf(y_data))
if best_err < self.epsilon:
return node(res=self.leaf(y_data))
else:
left = self.buildTree(X_data[subsets_inds[0]], y_data[subsets_inds[0]])
right = self.buildTree(X_data[subsets_inds[1]], y_data[subsets_inds[1]])
return node(fea=best_split[0], val=best_split[1], right=right, left=left)
def fit(self, X_data, y_data):
self.tree = self.buildTree(X_data, y_data)
return
def predict(self, x):
# 对输入变量进行预测
def helper(x, tree):
if tree.res is not None:
return tree.res
else:
if x[tree.fea] <= tree.val:
branch = tree.left
else:
branch = tree.right
return helper(x, branch)
return helper(x, self.tree)
def showTree(self):
root=self.tree
tree={}
tree[root.val]=self.preTraverse(root)
return tree
def preTraverse(self,root):
tree={}
if root.left.val==None:
return root.val
if root.right.val==None:
return root.val
tree[root.left.val]=self.preTraverse(root.left)
tree[root.right.val]=self.preTraverse(root.right)
return(tree)
''' 画决策树'''
def plot_model(tree, name):
g = Digraph("G", filename=name, format='png', strict=False)
first_label = 'root'
g.node("0", str(first_label))
#tree={first_label:tree}
#print(tree)
_sub_plot(g, tree, "0")
g.view()
root = "0"
def _sub_plot(g, tree, inc):
global root
#first_label = list(tree.keys())[0]
#ts = tree[first_label]
if(isinstance(tree, dict)):
tslist=list(tree.keys())
else:
tslist=[tree]
print("tsList:",tslist)
for i in tslist:
'''
if(isinstance(tree[first_label], dict)):
treeDict=tree[first_label]
else:
treeDict={i:first_label}
print('treeDict:',treeDict)
'''
if isinstance(tree[i], dict):
root = str(int(root) + 1)
g.node(root, str(i))
g.edge(inc, root, str(i))
_sub_plot(g, tree[i], root)
else:
root = str(int(root) + 1)
g.node(root, str(tree[i]))
g.edge(inc, root, str(i))
def loadSplitDataSet(txtname,rate):
file = open(txtname)
lines1 = file.readlines()
file.close
#print(lines1)
lines2=[]
lines1.pop(0)
for line in lines1:
lineTemp=line.replace('\n','').split(';')
lines2.append(lineTemp)
step=int(1/(1-rate))
testSet=lines2[::step]
del lines2[::step]
trainSet=lines2
trainData=[]
testData=[]
trainLabel=[]
testLabel=[]
for x in trainSet:
trainDataTemp=[]
trainLabel.append(int(x[-1]))
for y in x[0:-1]:
trainDataTemp.append(float(y))
trainData.append(trainDataTemp)
for x in testSet:
testDataTemp=[]
testLabel.append(int(x[-1]))
for y in x[0:-1]:
testDataTemp.append(float(y))
testData.append(testDataTemp)
#print(len(trainData))
#print(len(testData))
#print(len(trainLabel))
#print(len(testLabel))
trainData=np.array(trainData)
testData=np.array(testData)
trainLabel=np.array(trainLabel)
testLabel=np.array(testLabel)
return trainData,testData,trainLabel,testLabel
def classify(self, data):
def f(tree, data,count=0):
if type(tree) != dict:
#print(count)
return tree
else:
count+=1
#print(tree[data[tree['feature']]])
return f(tree[data[tree['feature']]], data,count)
return f(self.tree, data,count)
if __name__ == '__main__':
trainData,testData,trainLabel,testLabel = loadSplitDataSet(r'C:\Users\huawei\Desktop\统计学习理论\实验三\regress\winequality-red.csv',0.8)
clf = CART_REG(epsilon=1e-4, min_sample=1)
clf.fit(trainData, trainLabel)
count=0
tree=clf.showTree()
plot_model(tree,"hello.gv")
for i in range(testData.shape[0]):
if(int(round(clf.predict(trainData[i]),0))==testLabel[i]):
count+=1
print('The accuracy is %.2f'%(count/ len(testLabel)))