打破砂锅系列之二,深入分析JMeter的Aggregate Report
一、概览
JMeter的Aggregate Report(聚合报告)是进行并发压力测试时常用的Listener(监听器),下图是一个Demo运行的Aggregate Report示例(并发用户10个,持续60秒):

简单解释一下(为查看方便表格转置了一下):
标题 |
Label |
登录系统 |
修改文章 |
同步修改已经发布的链接 |
TOTAL |
请求 |
# Samples |
1378 |
274 |
274 |
1926 |
平均RT |
Average |
297 |
219 |
350 |
293 |
中值RT |
Median |
292 |
218 |
348 |
292 |
90%RT |
90% Line |
332 |
229 |
381 |
349 |
95%RT |
95% Line |
347 |
233 |
390 |
363 |
99%RT |
99% Line |
411 |
250 |
419 |
415 |
最小RT |
Min |
248 |
205 |
281 |
205 |
最大RT |
Max |
551 |
285 |
526 |
551 |
出错率 |
Error % |
0.00% |
0.00% |
0.00% |
0.00% |
吞吐量 |
Throughput |
22.93647 |
4.62627 |
4.61894 |
31.93024 |
接收速率 |
Received KB/sec |
9.43 |
1.76 |
1.85 |
12.94 |
发送速率 |
Sent KB/sec |
16.58 |
3.43 |
5.17 |
24.97 |
字面意思很好理解,问几个问题:
1)每个操作的Samples是怎么得来的?为什么不是并发10个用户10个Samples?
2)90%Line是表示的全部Samples里面的90%事务响应时间,这90%是怎么取的?随机吗?同样Median、95%和99%也有同样的问题。
3)Throughput怎么算得的?真的准确吗?
对于这三个有疑问的性能指标,分别进行分析。
二、Samples
Samples指同一个label的请求个数,所以请求不能重名,否则会将不同的请求统计在一起。
当使用默认的Thread Group循环执行指定次数时,Samples是好计算的。比如上述的例子:并发用户5个,循环两次,可以很容易得到请求“登录系统”Samples为10,请求“修改文章”和“同步修改已经发布的链接”Samples与登录有5:1的关系,分别为2次,总计Samples为14。验证结果如下:

但是如果使用扩展线程组Stepping Thread Group或者使用默认Thread Group持续执行时,Samples怎么计算呢?
这里需要了解一个JMeter压力的机制:在指定的持续压力时间内,任意线程(模拟用户)完成执行全部请求后,会重新开始执行,直至指定的时间截止。这是很容易理解的,极端情况,只测试登录一种请求,持续30分钟,而一次登录在几毫秒内已经返回了,那么对于该线程是不会退出的,它会不眠不休、继续完成它压力的使命。每一个线程都是如此,这样才体现了压力。
有了这样的分析,通过实践验证猜想,首先是一个简单的情况,上述例子:使用Stepping Thread Group并发用户5个,持续60秒。结果如下。

以请求“登录系统”为例在60秒内共完成了738次请求。使用RT估计一下,最大RT为605,最小RT为238,并发5个线程,并发就认为是5个均分的并发。所以Samples的书应该在60*1000*5/605和60*1000*5/238之间,即495.87到1260.5之间。其他请求以及总计的估算方法类似。
如果是更为复杂的情况,如下图的负载场景,共并发20用户,首先并发5个,之后每隔10秒增加5个,到达峰值后持续10分钟,之后每隔10秒停止5个。总计耗时11分钟:
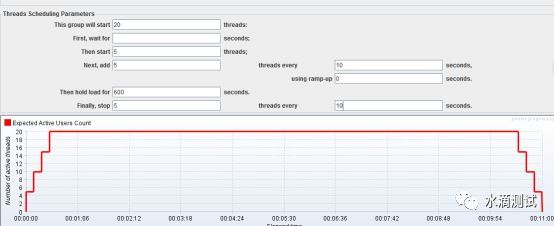
运行结果如下:

估算一下请求“登录系统”的Samples,计算如下:
持续时间(毫秒) |
并发用户 |
Min RT |
Max RT |
Min Samples |
Max Samples |
660000 |
5 |
239 |
845 |
3905.325444 |
13807.53138 |
650000 |
5 |
239 |
845 |
3846.153846 |
13598.32636 |
640000 |
5 |
239 |
845 |
3786.982249 |
13389.12134 |
630000 |
5 |
239 |
845 |
3727.810651 |
13179.91632 |
总计 |
15266.27219 |
53974.8954 |
三、RT
Aggregate Report给出的RT(事务响应时间)共有7个,分别是Average(平均),Median(中值),90%Line(90%RT),95%Line(95%RT),99%Line(99%RT),Min(最小),Max(最大),单位都是毫秒。
其中Average、Min和Max很好理解。Median,90%Line,95%Line,99%Line需要重点说明。
首先说一下后三者是可以配置的,通过jmeter.properties的相关关键字可以进行配置。
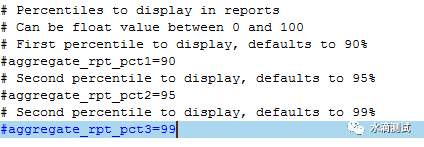
以Median为例,并不是字面意义上的中间值,而是统计学意义上的中值,即JMeter官网中反复提到的“Percentile”。统计学中有一堆复杂的公式说明如何计算中值或者90%百分位数,这里不展开讨论。
简单的说Median是在一组数值中居于中间的数值,如果参数集合中包含偶数个数字,Median为位于中间的两个数的平均值。这个数表示的意思就是即一半数的值比Median大,另一半数的值比Median小。
所以Aggregate Report中的Median,90%Line,95%Line,99%Line不是随机取的,而是排序后计算得到的。
使用统计数据进行性能评价是科学的,以99%Line为例,说明本次测试中99%的请求都不会比该RT大,换句话说比99%Line大的请求只有1%。所以,在测试中会发现,Max的值往往原大于99%Line。在有些系统中,只要求90%Line达标或者95%Line。
四、Throughput
Throughput单位是请求/秒/分钟/小时。不完全等同于TPS,相应的差别单独讨论。今天看一下计算公式:
Throughput = Samples数量/全部时间。
还是刚才的例子,并发用户10个,持续60秒的Aggregate Report示例:

每个请求的Throughput是单独计算的,公式都是一致的,界面显示内容是小数点一位四舍五入的结果。以请求“登录系统”为例,当前Throughput为23.51204,但是如果用1417/60计算的结果为:23.66667偏差约为:0.1,约为0.4%。为什么呢?
因为全部时间的计算是从第一个Sample开始时间到最后一个Sample结束的时间。包括所有Sample之间的间隔,因为这都是对服务器的压力体现。如何获取Sample呢?可以通过配置将结果输出到文件:
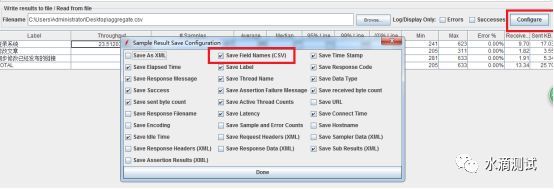
输出的CSV文件部分内容如下。只过滤请求“登录系统”,一共1417个请求。

查看timeStamp(时间戳),该列表示该请求发起的时间,所以可以知道请求“登录系统”第一个请求和最后一个请求的时间为(毫秒计算):1524552831828和1524552891774,算下来为59946毫秒,这样计算Throughput为1417/59.946,结结果为23.63794。偏差还是很大,为什么呢?再次理解“全部时间的计算是从第一个Sample开始时间到最后一个Sample结束的时间”,现在的59946少了一个最后一个Sample的运行时间,通过JMeter官网的说法:
![]()
Elapsed time是JMeter用来衡量请求开始发送到该请求的最后一个返回接收到的时间。这个时间不包括渲染响应所需的时间,JMeter也不处理任何客户端代码,例如JavaScript。
所以全部时间的计算需要在59946的基础上加上300毫秒,即60246毫秒,计算得到的Throughput为1417/60.246,结果是23.52023。对比界面的23.51204,偏差为0.00819,约为0.03%,已经非常接近了。每一个请求以及总计的请求计算方式都是类似的。
从这个数据的追踪看,界面的计算值通过简单的持续压力时间得到的偏差也不是很大。同时通过导出CSV的数据比较,可以证明Aggregate Report的计算也是很靠谱的。
看完本文有收获?请分享给更多人
关注水滴测试,不知不觉变大牛
