系列文章列表:
scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy01.html
scrapy爬虫学习系列二:scrapy简单爬虫样例学习: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy02.html
scrapy爬虫学习系列三:scrapy部署到scrapyhub上: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_004_scrapyhub.html
scrapy爬虫学习系列四:portia的学习入门: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_010_scrapy04.html
scrapy爬虫学习系列五:图片的抓取和下载: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_011_scrapy05.html
scrapy爬虫学习系列六:官方文档的学习: https://github.com/zhaojiedi1992/My_Study_Scrapy
注意: 我自己新建的一个QQ群(新建的),欢迎大家加入一起学习一起进步 ,群号646187336
官方的一个说明步骤:https://helpdesk.scrapinghub.com/support/solutions/articles/22000201935-deploying-a-project-from-a-github-repository
这里有个scrapyhub的帮助论坛吧:https://helpdesk.scrapinghub.com/support/solutions
1 scrapyhub简介
scrapyhub就是提供一个云平台,让你的爬虫程序可以开发和运行在云平台上。
我这里提供一个样例的使用过程。
2 github相关方面的准备工作
2.1注册一个github账号
注册页面:https://github.com/join?source=header-home
注册过程主要有3步骤,我这里提供3个截图。
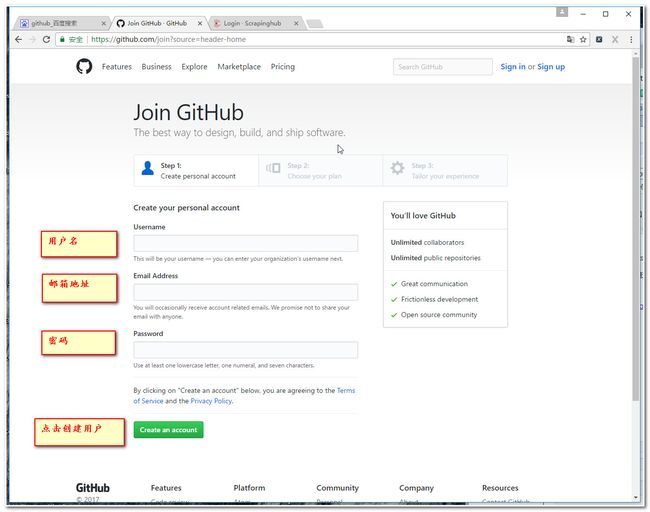
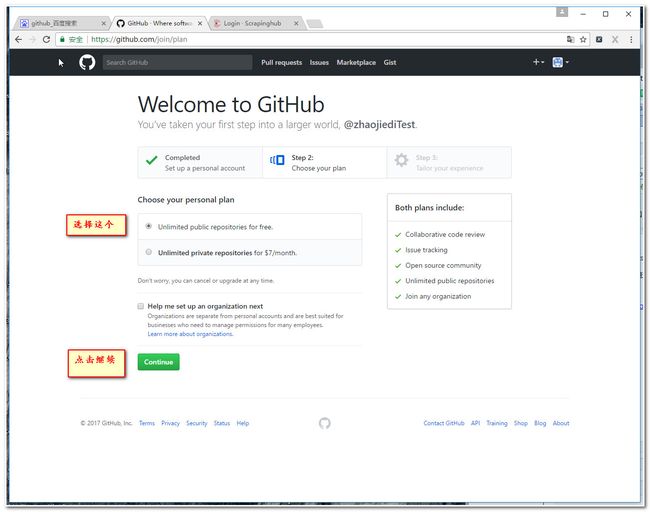
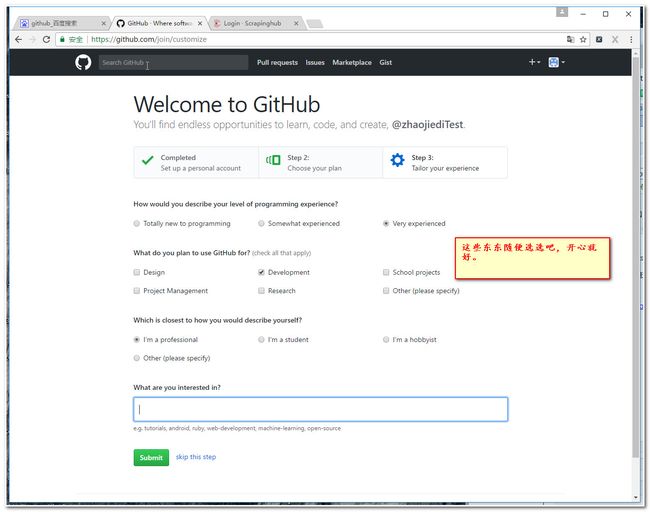
2.2 创建一个github项目
2.2.1 我们从github找到scrapy官方的demo程序,地址https://github.com/scrapy/quotesbot,我们打开这个地址,点击页面上面的右上角的fork按钮,创建一个复制。
2.2.2 如果提示需要邮件确认的话,请登录你的邮箱点击链接即可。
2.2.3 重复2.2.1步骤,就可以fork一个官方的scrapy deom了。(具体详细的代码,可以自己去瞧瞧)
3 使用github账号登录scrapyhub网址
3.1 登录scrapyhub网址
打开scrapyhub的官方网址 https://scrapinghub.com/scrapy-cloud/, 点击右上角的login按钮,选择github登录方式,接下来就是下一步下一步啦。最后就是如下图的界面了。
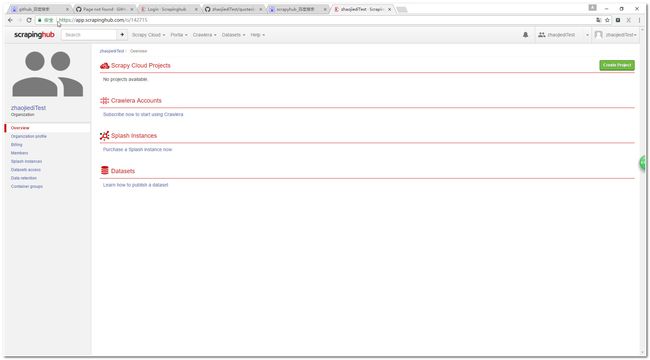
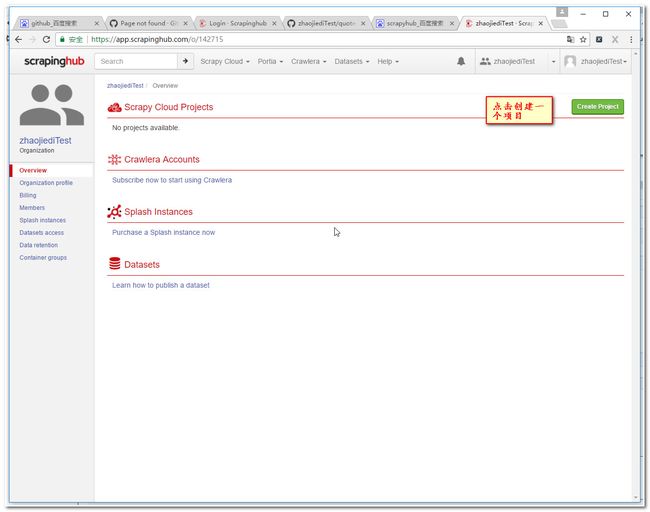
3.2 创建项目
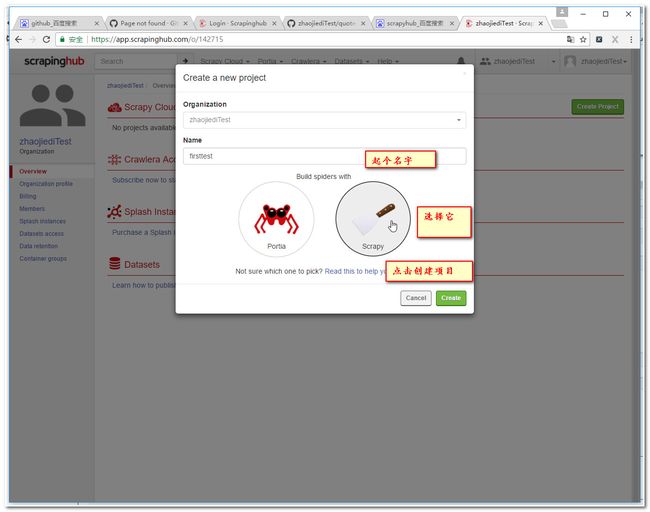
3.3设置下工程参数
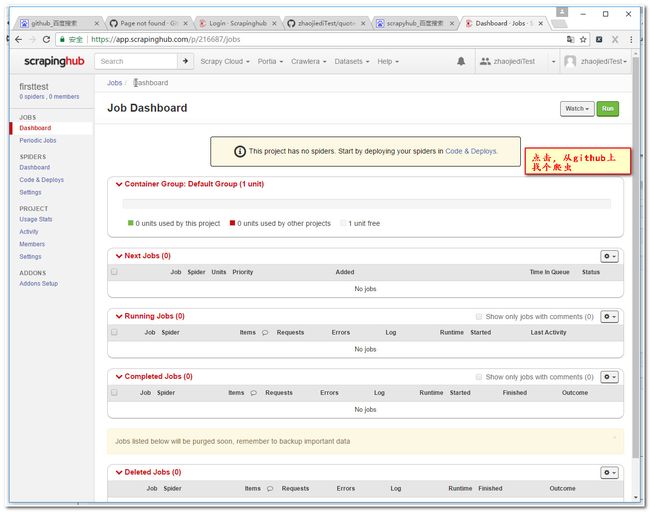
3.4设置工程参数
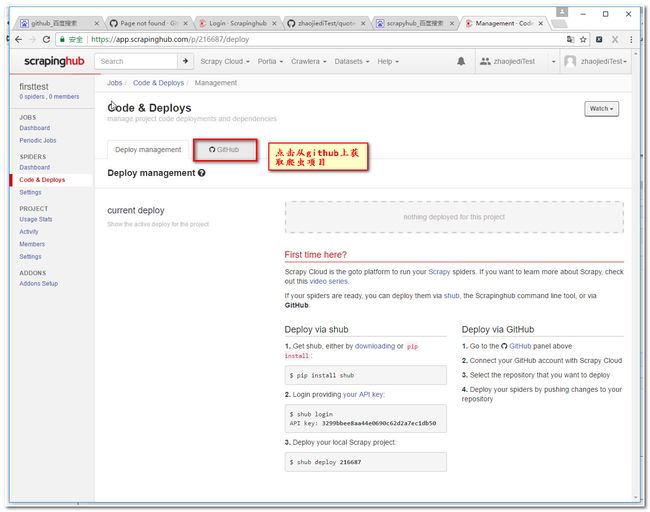
3.5设置工程参数
3.6 设置工程参数
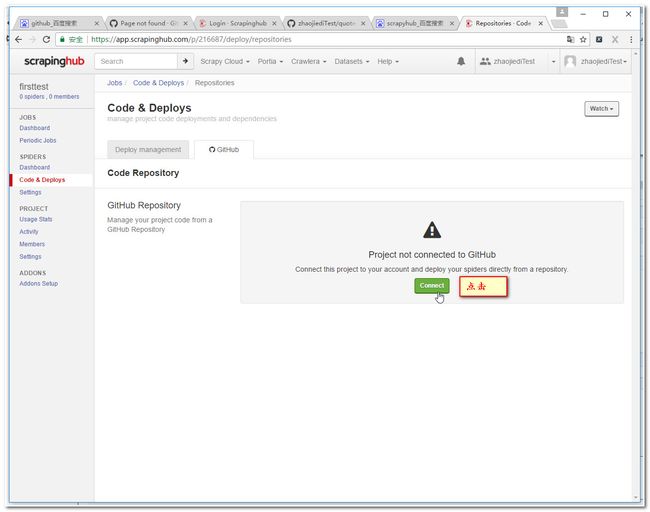
3.7 设置工程参数
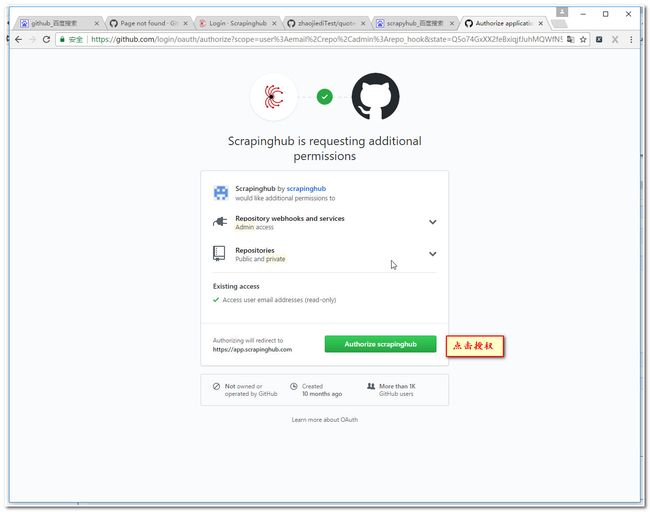
3.8设置工程参数
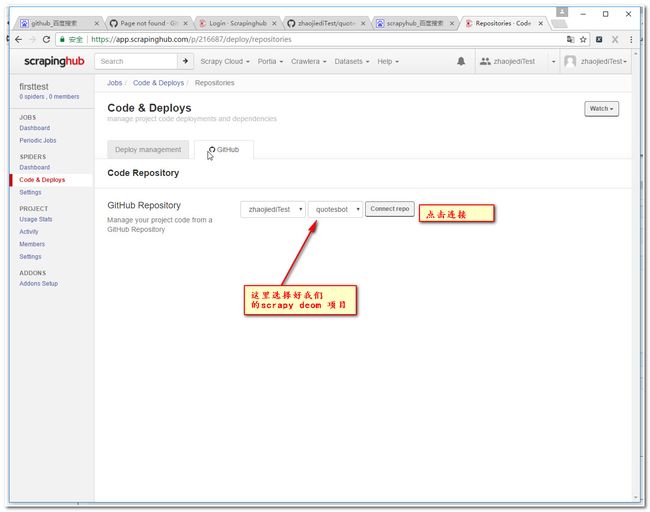
3.9 设置工程参数
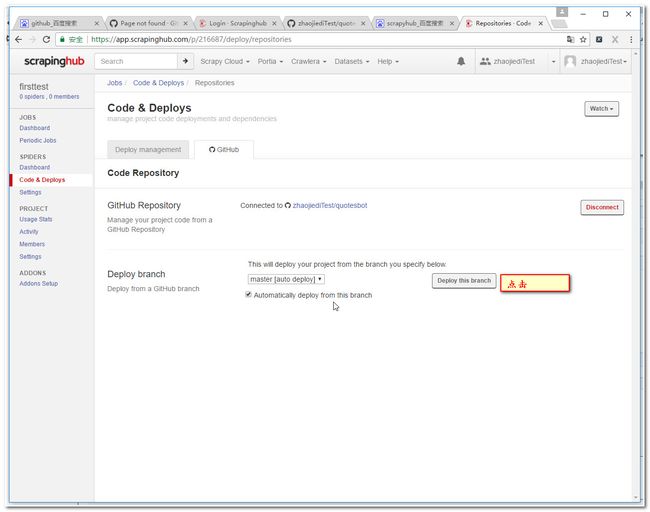
3.10 设置工程参数
3.11添加调度计划
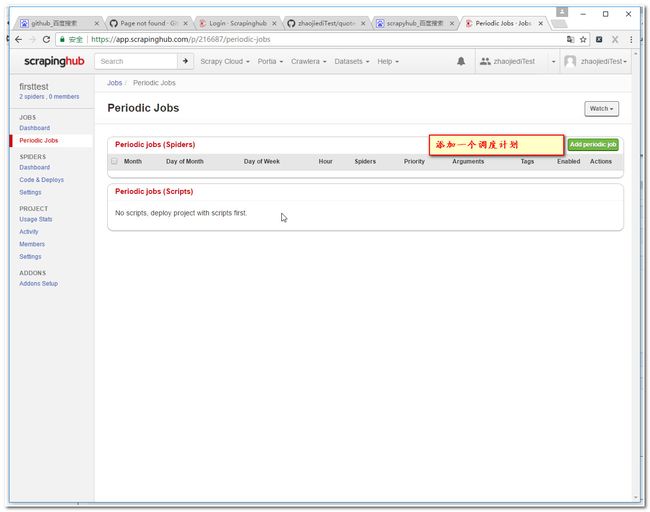
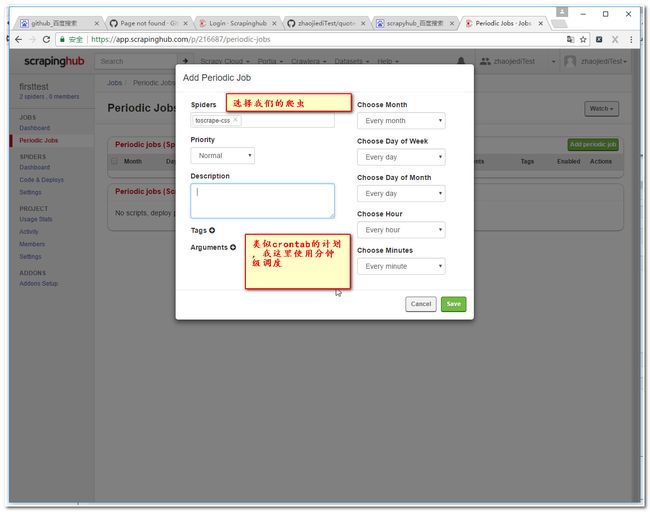
3.12 设置调度计划
3.13 查看job执行情况
注意: 我们使用的分钟级任务,大概需要等1分钟才有结果。当然你点击右上角的run去手工运行下。
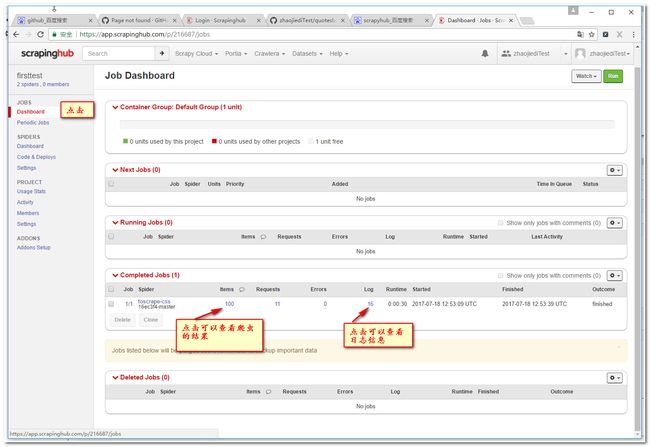
3.14 数据查看和导出

4. 数据导出的api接口
官方的api地址: https://doc.scrapinghub.com/scrapy-cloud.html#scrapycloud
我们这里导出一个job的某次执行结果吧。
导出的url格式items/:project_id[/:spider_id][/:job_id][/:item_no][/:field_name]
如果我们想导出3.14图(页面的url是https://app.scrapinghub.com/p/216687/1/1/items)中的结果,以json格式的形成导出:
可以看出spider_id 就是216687,job_id 就是1 ,item_no 就是1 ,key 我们可以从这个网址查看https://app.scrapinghub.com/account/apikey
所有我们可以访问https://storage.scrapinghub.com/items/216687/1/1?apikey=3299bbee8aa44e0690c62d2a7ec1db50&format=json