小目标检测:Improving Small Object Detection
版权声明:转载必须经过本人同意,获得留言同意即可。
原文:https://pan.baidu.com/s/1WRI7KTNftyY9K1KHQtE_QA
Improving Small Object Detection (ACPR2017)
Harish Krishna, C.V. Jawahar
CVIT, KCIS
International Institute of Information Technology
Hyderabad, India
1 Motivation
小目标的分辨率低,形状简单(轮廓粗糙)。一般的目标检测网络在大,中尺寸的目标上能取得较好的效果,但是在小目标的检测上性能不好。
2 Contributions
- 通过数学推导,确定了anchors的合适尺寸,并进行了详细的试验以证明其选择的有效性。
- 在网络中加入超分辨率技术,提高了网络的性能。
3 Framework
本文是在Faster R-CNN的算法框架上针对小目标检测的的一些改进。核心思想有两点:
- RPN中anchor size的设置一定要合适,这样可以提高proposal的准确率。
- 对于分辨率低的小目标,我们可以对其所在的proposal进行超分辨率,提升小目标的特征质量,这样更有利于小目标的检测。
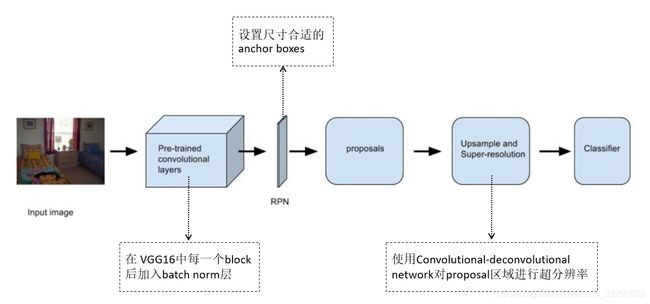 图1 网络框架
图1 网络框架
该算法框架和Faster R-CNN基本一致,改动出现在图中标注的3个虚线框处。
3.1 在 VGG16中每一个block后加入batch norm层
这里简单介绍下batch Normalization,网上资料很多,读者可自行查找。batch Normalization作为最近年来DL的重要成果,已经广泛被证明其有效性和重要性。它有以下几点好处:
- 极大提升了训练速度和收敛过程。
- 提供了一种类似Dropout的防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;
- 简化调参过程,对于初始化要求没那么高,可以使用大的学习率。
其算法流程如图2:
 图2 batch Normalization
图2 batch Normalization
3.2 设置尺寸合适的anchor boxes
 图3 anchor size的选择
图3 anchor size的选择
如图3所示,我们假设anchor和ground truth的框是正方形。那么图中Sgt表示ground truth的边长,SA表示anchor的边长,d表示两框在非重合区域中边界的距离。我们知道anchor和ground truth的IoU表示为:
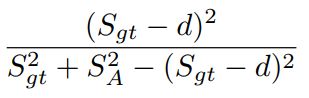
我们设置一个IOU的阈值为t,由min IoU ≥ t可得:
![]()
接着,作者引用了论文(Improving small object proposals for company logo detection , ICMR 2017)中的结论:
![]()
最后,d最大值等于anchor的步进,而anchor的步进可由主干网下采样的次数算出。我们可以得出:
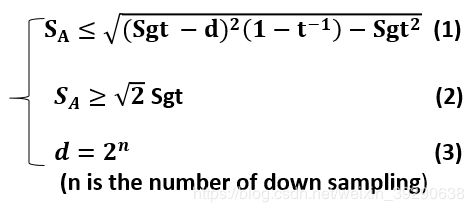
3.3 使用convolutional-deconvolutional network对proposal区域进行超分辨率
作者引用了论文(Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections, NIPS2016)中的Convolutional-deconvolutional network对proposals进行超分辨率。
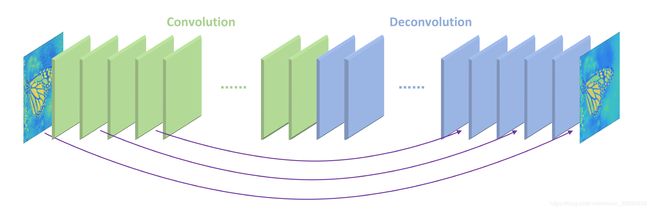 图4 Convolutional-deconvolutional network
图4 Convolutional-deconvolutional network
该网络的结构是对称的,每个卷积层都有对应的反卷积层。卷积层用来获取图像的抽象内容,反卷积层用来放大特征尺寸并且恢复图像细节。卷积层将输入图像尺寸减小后,再通过反卷积层上采样变大,使得输入输出的尺寸一样。每一组镜像对应的卷积层和反卷积层有着shortcut连接结构,将卷积层的特征和对应的反卷积层输出的特征做相加操作后再输入到下一个反卷积层。这样的结构类似ResNet的残差结构,卷积层和反卷积层学习的特征是目标图像和低质图像之间的残差,损失函数用的均方误差。该网络在ImageNet进行预训练。
超分辨后的proposal送入后续的Classifier进行分类(这里笔者认为还应该有对proposal里的小目标进行再一次regression的操作,但原作者并没有提到)。
4 EXPERIMENTS AND DISCUSSION
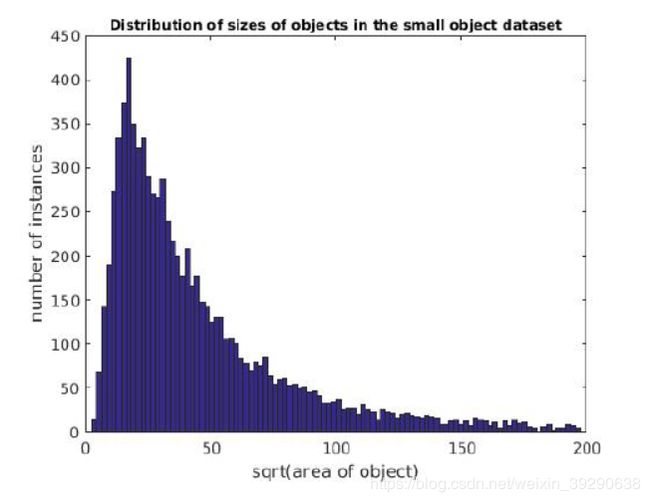 图5 Small Object Dataset目标size分布
图5 Small Object Dataset目标size分布
本文使用了取自于Microsoft COCO and the SUN dataset 的Small Object Dataset ,其目标的size分布如图5所示。
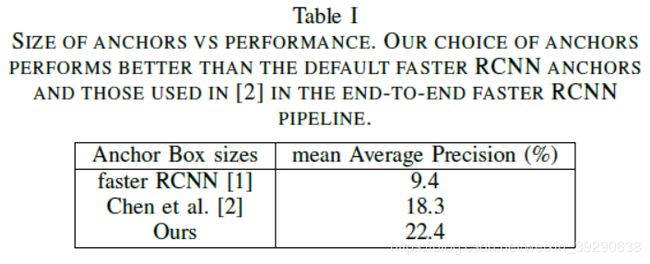
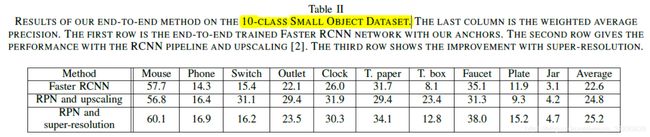
作者分析数据集中对象的大小,将anchor的大小定为{16;25;32;45;64;90},并和标准的Faster R-CNN做proposal的mAP的比较(同时也和“R-cnn for small object detection”一文做了比较)。作者计算mAP时,在每张测试图片中取confidence排名前1000的非背景类的proposal。从Table 1可以看出,设置合适的anchor size对small object的proposal提取影响很大。最后作者放出了标准faster R-CNN和加入超分辨率后的方法的实验结构对比。作者改进后的方法在小物体检测的性能上有一定的提升。
5 总结
本文基于Faster R-CNN提出了一种改进小目标检测的方法。这种方法是从网络proposal部分入手,将模糊的小目标通过超分辨率清晰化后再进行分类和回归,提高了小目标检测的性能。
笔者在ECCV 2018中也见到类似的方法,如SOD-MTGAN,后续会和大家分享。笔者认为这种方法增加了不少时间复杂度,不适合实时性要求较高的系统。