使用Kubeadm(v.1.17)部署k8s 环境
kubernetes 核心概念:
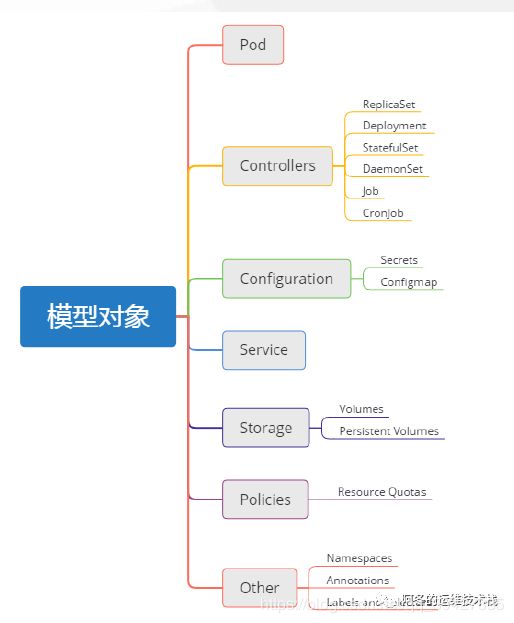
- Pod
- 最小部署单元
- 一组容器的集合
- 一个Pod中的容器共享网络命名空间
- Pod是短暂的
- Controllers
- ReplicaSet :确保预期的Pod副本数量
- Deployment :无状态应用部署
- StatefulSet :有状态应用部署
- DaemonSet :确保所有Node运行同一个Pod
- Job :一次性任务
- Cronjob :定时任务
更高级层次对象,部署和管理Pod
- Service
- 防止Pod失联
- 定义一组Pod的访问策略
- Label :标签,附加到某个资源上,用于关联对象、查询和筛选
- Namespaces:命名空间,将对象逻辑上隔离
- Annotations :注释
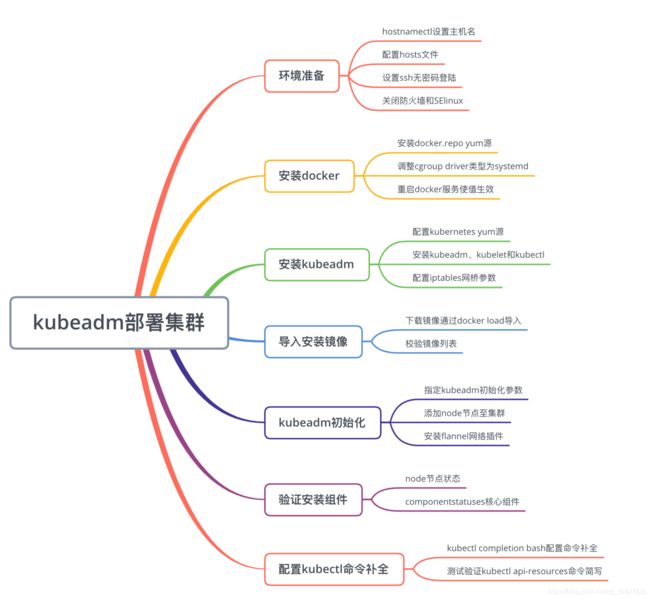
kubeadm 部署k8s 集群
1. 硬件配置
建议至少2 CPU 、2G,非硬性要求,1CPU、1G也可以搭建起集群,但是在部署时会有WARNING提示:
#1个CPU的初始化master的时候会报
[WARNING NumCPU]: the number of available CPUs 1 is less than the required 2
#部署插件或者pod时可能会报
warning:FailedScheduling:Insufficient cpu, Insufficient memory环境准备:
| IP |
角色 |
安装软件 |
|---|---|---|
| 192.168.73.132 |
k8s-Master |
kube-apiserver kube-schduler kube-controller-manager docker flannel kubelet |
| 192.168.73.133 |
k8s-node01 |
kubelet kube-proxy docker flannel |
| 192.168.73.134 |
k8s-node01 |
kubelet kube-proxy docker flannel |
修改主机名:hostnamectl set-hostname 主机名 (永久生效)
其中步骤2--8,10 为三台几点都执行的。kubeadm 初始化只在主节点执行。
备注:刚开始使用Ceneos 7.3 版本,安装docker18 版本,docker 启动没有问题,但是kubelet 在启动的时候总是无法启动,也没有看到什么报错,后面升级操作系统到7.6版本,重启操作系统之后,kubelet 直接启动成功。
2、修改内核参数
cat < /etc/sysctl.d/k8s.conf
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.ip_forward = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.netfilter.nf_conntrack_max = 2310720
fs.inotify.max_user_watches=89100
fs.may_detach_mounts = 1
fs.file-max = 52706963
fs.nr_open = 52706963
net.bridge.bridge-nf-call-arptables = 1
vm.swappiness = 0 #最大限度使用物理内存,然后才是 swap空间
vm.overcommit_memory=1
vm.panic_on_oom=0
EOF
sysctl --system 3、关闭swap
k8s1.8版本以后,要求关闭swap,否则默认配置下kubelet将无法启动。
#临时关闭
swapoff -a
#永久关闭
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab或者修改:/etc/sysctl.conf
vm.swappiness = 0
升级内核:(可选)
升级系统内核为4.44版本
#CentOS7.x系统自带的3.10.x内核存在一些Bug,导致运行的Docker、Kubernetes不稳定
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 安装完成后检查/boot/grub2/grub.cfg 中对应内核menuentry中是否包含initrd16配置,如果没有,再安装一次
yum --enablerepo=elrepo-kernel install -y kernel-lt
# 设置开机从新内核启动
grub2-set-default "CentOS Linux (4.4.182-1.el7.elrepo.x86\_64) 7 (Core)"4、开启ipvs
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
#查看是否加载
lsmod | grep ip_vs
#配置开机自加载
cat <> /etc/rc.local
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod +x /etc/rc.d/rc.local
或者设置在chmod +x /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules 目录下面 5、禁用selinux
#临时关闭
setenforce 0
#永久关闭
sed -ir 's/(SELINUX=)[a-z]*/\1diabled/' /etc/selinux/config6、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld7、安装docker
#获取docker-ce的yum源
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
或者(测试环境用过):
curl -o docker-ce.repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#获取epel源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
或者(测试环境用过): curl -o CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
#yum -y install epel-release
查看docker 有哪些可用版本
yum list docker-ce --showduplicates
安装指定版本
yum -y install docker-ce-
指定版本:yum install docker-ce-18.06.3.ce-3.el7
#安装docker
yum -y install docker-ce
#启动docker
docker version
systemctl start docker
systemctl enable docker 包依赖:
Installing:
docker-ce x86_64 18.06.3.ce-3.el7
container-selinux noarch 2:2.107-3.el7
8、安装kubeadm
(1)设置kubeadm 的安装源
kubelet 运行在 Cluster 所有节点上,负责启动 Pod 和容器。
kubeadm 用于初始化 Cluster。
kubectl 是 Kubernetes 命令行工具。通过 kubectl 可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
所有节点都安装 kubeadm、kubelet、kubectl,注意:node节点的kubectl不是必须的。
# 添加阿里云yum源
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF (2) 安装kubeadm
yum install kubeadm-1.17.0 kubelet-1.17.0 kubectl-1.17.0
Dependencies Resolved
===========================================================================================================================================
Package Arch Version Repository Size
===========================================================================================================================================
Installing:
kubeadm x86_64 1.17.0-0 kubernetes 8.7 M
kubectl x86_64 1.17.0-0 kubernetes 9.4 M
kubelet x86_64 1.17.0-0 kubernetes 20 M
Installing for dependencies:
conntrack-tools x86_64 1.4.4-5.el7_7.2 updates 187 k
cri-tools x86_64 1.13.0-0 kubernetes 5.1 M
kubernetes-cni x86_64 0.7.5-0 kubernetes 10 M
libnetfilter_cthelper x86_64 1.0.0-10.el7_7.1 updates 18 k
libnetfilter_cttimeout x86_64 1.0.0-6.el7_7.1 updates 18 k
libnetfilter_queue x86_64 1.0.2-2.el7_2 base 23 k
socat x86_64 1.7.3.2-2.el7 base 290 k
Updating for dependencies:
libnetfilter_conntrack x86_64 1.0.6-1.el7_3 base 55 k
Transaction Summary
===========================================================================================================================================
Install 3 Packages (+7 Dependent packages)
Upgrade ( 1 Dependent package)
Downloading packages:
Delta RPMs disabled because /usr/bin/applydeltarpm not installed.
(1/11): conntrack-tools-1.4.4-5.el7_7.2.x86_64.rpm | 187 kB 00:00:00
warning: /var/cache/yum/x86_64/7/kubernetes/packages/14bfe6e75a9efc8eca3f638eb22c7e2ce759c67f95b43b16fae4ebabde1549f3-cri-tools-1.13.0-0.x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID 3e1ba8d5: NOKEY
Public key for 14bfe6e75a9efc8eca3f638eb22c7e2ce759c67f95b43b16fae4ebabde1549f3-cri-tools-1.13.0-0.x86_64.rpm is not installed
(2/11): 14bfe6e75a9efc8eca3f638eb22c7e2ce759c67f95b43b16fae4ebabde1549f3-cri-tools-1.13.0-0.x86_64.rpm | 5.1 MB 00:00:08
(3/11): 2c6d2fa074d044b3c58ce931349e74c25427f173242c6a5624f0f789e329bc75-kubeadm-1.17.0-0.x86_64.rpm | 8.7 MB 00:00:16
(4/11): bf67b612b185159556555b03e1e3a1ac5b10096afe48e4a7b7f5f9c4542238eb-kubectl-1.17.0-0.x86_64.rpm | 9.4 MB 00:00:16
(5/11): libnetfilter_cthelper-1.0.0-10.el7_7.1.x86_64.rpm | 18 kB 00:00:00
(6/11): libnetfilter_cttimeout-1.0.0-6.el7_7.1.x86_64.rpm | 18 kB 00:00:00
(7/11): libnetfilter_conntrack-1.0.6-1.el7_3.x86_64.rpm | 55 kB 00:00:00
(8/11): libnetfilter_queue-1.0.2-2.el7_2.x86_64.rpm | 23 kB 00:00:00
(9/11): socat-1.7.3.2-2.el7.x86_64.rpm | 290 kB 00:00:01
(10/11): 548a0dcd865c16a50980420ddfa5fbccb8b59621179798e6dc905c9bf8af3b34-kubernetes-cni-0.7.5-0.x86_64.rpm | 10 MB 00:00:18
(11/11): 7d9e0a47eb6eaf5322bd45f05a2360a033c29845543a4e76821ba06becdca6fd-kubelet-1.17.0-0.x86_64.rpm | 20 MB 00:00:31
-------------------------------------------------------------------------------------------------------------------------------------------
Total 1.1 MB/s | 54 MB 00:00:48 systemctl enable kubelet && systemctl start kubelet
将kubelet加入开机启动,这里刚安装完成不能直接启动。(因为目前还没有集群还没有建立)
配置阿里云镜像加速器:
#docker配置修改和镜像加速
[ ! -d /etc/docker ] && mkdir /etc/docker
cat > /etc/docker/daemon.json <systemctl daemon-reload
systemctl restart docker
如果不能,需要使用本文提供的私有镜像源,则还需要为docker做如下配置,将K8s官方镜像库的几个域名设置为insecure-registry,然后设置hosts使它们指向私有源。
# 所有主机:http私有源配置
# 为Docker配置一下私有源
mkdir -p /etc/docker
echo -e '{\n"insecure-registries":["k8s.gcr.io", "gcr.io", "quay.io"]\n}' > /etc/docker/daemon.json
systemctl restart docker可能的错误:
(1)kubelet启动失败
设置开机启动kubelet
systemctl enable kubelet
注意,这里不需要启动kubelet,初始化的过程中会自动启动的,如果此时启动了会出现如下报错,忽略即可。日志在tail -f /var/log/messages 或者用:journalctl -xe
failed to load Kubelet config file /var/lib/kubelet/config.yaml, error failed to read kubelet config file “/var/lib/kubelet/config.yaml”, error: open /var/lib/kubelet/config.yaml: no such file or directory
正常情况下,在初始化完成后会自动启动kubelet 。
(2) 镜像下载(可选):
因为在国内访问不了google的docker仓库,但是我们可以在阿里云上找到需要的镜像,下载下来,然后重新打上标签即可,可以使用下面的脚本下载所需镜像
镜像下载地址 https://cr.console.aliyun.com/images/cn-hangzhou/google_containers/kube-apiserver-amd64/detail
下面是镜像下载脚本:
#!/bin/bash
image_aliyun=(kube-apiserver-amd64:v1.17.1 kube-controller-manager-amd64:v1.17.1 kube-scheduler-amd64:v1.17.1 kube-proxy-amd64:v1.17.1 pause-amd64:3.1 etcd-amd64:3.4.3-0 coredns:1.6.5)
for image in ${image_aliyun[@]}
do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$image
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$image k8s.gcr.io/${image/-amd64/}
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$image
done9、部署kubernetes master
只需要在Master 节点执行,这里的apiserve需要修改成自己的master地址
使用kubeadm config print init-defaults可以打印集群初始化默认的使用的配置
这里采用命令行方式初始化,注意默认镜像仓库由于在国外,由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定为阿里云镜像仓库
需要注意这里使用的网络方案是flannel,注意CIDR。
# kubernetes-version版本和前面安装的kubelet和kubectl
注意这里执行初始化用到了- -image-repository选项,指定初始化需要的镜像源从阿里云镜像仓库拉取。
[root@Test01 ~]# kubeadm init \
--apiserver-advertise-address=192.168.44.132 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.17.0 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16初始化命令说明:
--apiserver-advertise-address
指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。
--pod-network-cidr
指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 --pod-network-cidr 有自己的要求,这里设置为 10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
--image-repository
Kubenetes默认Registries地址是 k8s.gcr.io,在国内并不能访问 gcr.io,在1.13版本中我们可以增加–image-repository参数,默认值是 k8s.gcr.io,将其指定为阿里云镜像地址:registry.aliyuncs.com/google_containers。
--kubernetes-version=v1.17.0
关闭版本探测,因为它的默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.17.0)来跳过网络请求。
(1) swap错误提示:
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
[ERROR Swap]: running with swap on is not supported. Please disable swap
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`关闭系统的Swap方法如下:
关闭系统的Swap方法如下:
swapoff -a
修改 vi /etc/fstab 文件,注释掉 SWAP 的自动挂载,使用free -m确认swap已经关闭。 swappiness参数调整,修改vi /etc/sysctl.d/k8s.conf添加下面一行:
vm.swappiness=0
执行sysctl -p /etc/sysctl.d/k8s.conf使修改生效。
(2)、kubect 提示8080 无法连接
kubectl get pods
The connection to the server localhost:8080 was refused - did you specify the right host or port?
出现这个问题的原因是kubectl命令需要使用kubernetes-admin来运行,解决方法如下,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下,然后配置环境变量:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
立即生效
source ~/.bash_profile
(3)、 提示,非错误(在初始化打印出来的信息)
[root@Test01 ~]# kubeadm init --apiserver-advertise-address=192.168.44.132 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.17.0 --service-cidr=10.1.0.0/16 --pod-network-cidr=10.244.0.0/16
W0410 17:14:35.328949 10553 validation.go:28] Cannot validate kube-proxy config - no validator is available
W0410 17:14:35.329036 10553 validation.go:28] Cannot validate kubelet config - no validator is available
[init] Using Kubernetes version: v1.17.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull如果出错,执行:
[root@Test01 yum.repos.d]# kubeadm reset
(4) 提示端口重复
执行:kubeadm reset 即可
W0413 16:05:35.711977 2222 validation.go:28] Cannot validate kube-proxy config - no validator is available
W0413 16:05:35.712032 2222 validation.go:28] Cannot validate kubelet config - no validator is available
[init] Using Kubernetes version: v1.17.0
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
(5)安装成功的提示:
W0413 16:18:32.060201 1691 validation.go:28] Cannot validate kube-proxy config - no validator is available
W0413 16:18:32.060251 1691 validation.go:28] Cannot validate kubelet config - no validator is available
[init] Using Kubernetes version: v1.17.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [test01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.1.0.1 192.168.44.132]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [test01 localhost] and IPs [192.168.44.132 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [test01 localhost] and IPs [192.168.44.132 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0413 16:18:37.394986 1691 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0413 16:18:37.396604 1691 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 26.005220 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.17" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node test01 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node test01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 8n0wrs.jiw7vhmgiewf2s6f
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.44.132:6443 --token 8n0wrs.jiw7vhmgiewf2s6f \
--discovery-token-ca-cert-hash sha256:516742cb33949c1f5274e5ae2fc0ab69edce231b83281e619b9e268118b88816初始化过程说明:
1、[preflight] kubeadm 执行初始化前的检查。
2、[kubelet-start] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
3、[certificates] 生成相关的各种token和证书
4、[kubeconfig] 生成 KubeConfig 文件,kubelet 需要这个文件与 Master 通信
5、[control-plane] 安装 Master 组件,会从指定的 Registry 下载组件的 Docker 镜像。
6、[bootstraptoken] 生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
7、[addons] 安装附加组件 kube-proxy 和 kube-dns。
8、Kubernetes Master 初始化成功,提示如何配置常规用户使用kubectl访问集群。
9、 提示如何安装 Pod 网络。
10、提示如何注册其他节点到 Cluster
根据提示执行如下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
10、配置kubectl命令
无论在master节点或node节点,要能够执行kubectl命令必须进行以下配置
root用户配置
cat << EOF >> ~/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source ~/.bashrc将master节点的/etc/kubernetes/admin.conf复制到node节点的相同位置下,并在node节点执行:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile等集群配置完成后,可以在master节点和node节点进行以上配置,以支持kubectl命令。针对node节点复制master节点/etc/kubernetes/admin.conf到本地。
kubectl 是管理 Kubernetes Cluster 的命令行工具,前面我们已经在所有的节点安装了 kubectl。Master 初始化完成后需要做一些配置工作,然后 kubectl 就能使用了。
依照 kubeadm init 输出的最后提示,推荐用 Linux 普通用户执行 kubectl。
- 创建普通用户centos
#创建普通用户并设置密码123456
useradd centos && echo "centos:123456" | chpasswd centos
#追加sudo权限,并配置sudo免密
sed -i '/^root/a\centos ALL=(ALL) NOPASSWD:ALL' /etc/sudoers
#保存集群安全配置文件到当前用户.kube目录
su - centos
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#启用 kubectl 命令自动补全功能(注销重新登录生效)
echo "source <(kubectl completion bash)" >> ~/.bashrc
需要这些配置命令的原因是:Kubernetes 集群默认需要加密方式访问。所以,这几条命令,就是将刚刚部署生成的 Kubernetes 集群的安全配置文件,保存到当前用户的.kube 目录下,kubectl 默认会使用这个目录下的授权信息访问 Kubernetes 集群。
如果不这么做的话,我们每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置。
配置完成后centos用户就可以使用 kubectl 命令管理集群了。
查看集群状态:
kubectl get cs #查看集群状态
kubectl get nodes #确认节点状态
可以看到,当前只存在1个master节点,并且这个节点的状态是 NotReady。
使用 kubectl describe node k8s-master命令来查看这个节点(Node)对象的详细信息、状态和事件(Event)。
通过 kubectl describe 指令的输出,我们可以看到 NodeNotReady 的原因在于,我们尚未部署任何网络插件,kube-proxy等组件还处于starting状态。
另外,我们还可以通过 kubectl 检查这个节点上各个系统 Pod 的状态,其中,kube-system 是 Kubernetes 项目预留的系统 Pod 的工作空间(Namepsace,注意它并不是 Linux Namespace,它只是 Kubernetes 划分不同工作空间的单位)。
可以看到,CoreDNS依赖于网络的 Pod 都处于 Pending 状态,即调度失败。这当然是符合预期的:因为这个 Master 节点的网络尚未就绪。
集群初始化如果遇到问题,可以使用kubeadm reset命令进行清理然后重新执行初始化。
11、主节点配置fannel网络
master节点部署网络插件fannel
要让 Kubernetes Cluster 能够工作,必须安装 Pod 网络,否则 Pod 之间无法通信
基于kubeadm部署时,flannel同样运行为Kubernetes集群的附件,以Pod的形式部署运行于每个集群节点上以接受Kubernetes集群管理。
事实上,也可以直接将flannel程序包安装并以守护进程的方式运行于集群节点上,即以非托管的方式运行。部署方式既可以是获取其资源配置清单于本地而后部署于集群中,也可以直接在线进行应用部署。
部署命令是“kubectlapply”或“kubectlcreate”,例如,下面的命令将直接使用在线的配置清单进行flannel部署:
原本是https 连接,但是测试了几次都是无法成功下载文件,后面该改成http 就可以了。
方法一:
wget http://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlkubectl apply -f kube-flannel.yml
这里要注意,默认的flannel配置文件拉取镜像在国外,国内拉取失败,很多网上文章没注意这一步,导致flannel部署失败
方法二:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
sed -i 's#quay.io#quay-mirror.qiniu.com#g' kube-flannel.yml #替换仓库地址
kubectl apply -f kube-flannel.yml#绑定网卡
flannel 默认会使用主机的第一张网卡,如果你有多张网卡,需要指定时,可以修改 kube-flannel.yml 中的以下部分
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.12.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=ens192 #添加该行
稍等一会,应该可以看到node状态变成ready:
如果你的环境迟迟都是NotReady状态,可以kubectl get pod -n kube-system看一下pod状态,一般可以发现问题,比如flannel的镜像下载失败之类的
此状态应该是节点还在启动,还在准备中。
[root@Test01 k8s]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
test01 NotReady master 18h v1.17.0
test02 NotReady 14m v1.17.0
[root@Test01 k8s]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-9d85f5447-d29sc 0/1 Pending 0 18h
coredns-9d85f5447-glk7t 0/1 Pending 0 18h
etcd-test01 1/1 Running 3 18h
kube-apiserver-test01 1/1 Running 3 18h
kube-controller-manager-test01 1/1 Running 7 18h
kube-flannel-ds-amd64-96kzq 0/1 Init:0/1 0 47s
kube-flannel-ds-amd64-gbwcs 0/1 Init:0/1 0 47s
kube-proxy-9pqmd 1/1 Running 0 14m
kube-proxy-pn59g 1/1 Running 2 18h
kube-scheduler-test01 1/1 Running 7 18h 正常的状态:
查看集群的node状态,安装完网络工具之后,只有显示如下状态,所有节点全部都Ready好了之后才能继续后面的操作
[root@Test01 k8s]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-9d85f5447-d29sc 1/1 Running 0 19h
coredns-9d85f5447-glk7t 1/1 Running 0 19h
etcd-test01 1/1 Running 3 19h
kube-apiserver-test01 1/1 Running 3 19h
kube-controller-manager-test01 1/1 Running 7 19h
kube-flannel-ds-amd64-96kzq 1/1 Running 0 36m
kube-flannel-ds-amd64-gbwcs 1/1 Running 0 36m
kube-proxy-9pqmd 1/1 Running 0 51m
kube-proxy-pn59g 1/1 Running 2 19h
kube-scheduler-test01 1/1 Running 7 19h
[root@Test01 k8s]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
test01 Ready master 19h v1.17.0
test02 Ready 51m v1.17.0
查看所有namespace 的pod 信息,执行如下命令:
kubectl get pods --all-namespaces -o wide
可以看到,所有的系统 Pod 都成功启动了,而刚刚部署的flannel网络插件则在 kube-system 下面新建了一个名叫kube-flannel-ds-amd64-lkf2f的 Pod,一般来说,这些 Pod 就是容器网络插件在每个节点上的控制组件。
Kubernetes 支持容器网络插件,使用的是一个名叫 CNI 的通用接口,它也是当前容器网络的事实标准,市面上的所有容器网络开源项目都可以通过 CNI 接入 Kubernetes,比如 Flannel、Calico、Canal、Romana 等等,它们的部署方式也都是类似的“一键部署”。
只有全部都为1/1则可以成功执行后续步骤,如果flannel需检查网络情况,重新进行如下操作
kubectl delete -f kube-flannel.yml
然后重新wget,然后修改镜像地址,然后
kubectl apply -f kube-flannel.yml
所有的节点都已经 Ready,Kubernetes Cluster 创建成功,一切准备就绪。
如果pod状态为Pending、ContainerCreating、ImagePullBackOff 都表明 Pod 没有就绪,Running 才是就绪状态。
如果有pod提示Init:ImagePullBackOff,说明这个pod的镜像在对应节点上拉取失败,我们可以通过 kubectl describe pod 查看 Pod 具体情况,以确认拉取失败的镜像。
如果删除的pod 一直处于Terminating状态,那么执行下面的命令
在dashboard界面删除容器,发现无法删除。使用命令查看发现该pod一直处于terminating的状态
Kubernetes强制删除一直处于Terminating状态的pod。
1、使用命令获取pod的名字
kubectl get po -n NAMESPACE |grep Terminating
2、使用kubectl中的强制删除命令
kubectl delete pod podName -n NAMESPACE --force --grace-period=0
12、部署worker 节点
Kubernetes 的 Worker 节点跟 Master 节点几乎是相同的,它们运行着的都是一个 kubelet 组件。唯一的区别在于,在 kubeadm init 的过程中,kubelet 启动后,Master 节点上还会自动运行 kube-apiserver、kube-scheduler、kube-controller-manger 这三个系统 Pod。
kubeadm join 192.168.44.132:6443 --token 8n0wrs.jiw7vhmgiewf2s6f --discovery-token-ca-cert-hash sha256:516742cb33949c1f5274e5ae2fc0ab69edce231b83281e619b9e268118b88816
13、部署dashboard(在master上操作)
目前下面这个链接国内打不开。
kubectl create -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta1/aio/deploy/recommended.yaml
kubectl get pods --namespace=kubernetes-dashboard #查看创建的namespace
kubectl get service --namespace=kubernetes-dashboard #查看端口映射关系
可以从https://github.com/kubernetes/dashboard/release ,里面下载源码安装包,然后kubectl create -f aio/deploy/recommended.yaml
(1)修改service配置,将type: ClusterIP改成NodePort
kubectl edit service kubernetes-dashboard --namespace=kubernetes-dashboard
如下:
spec:
clusterIP: 192.168.44.132
externalTrafficPolicy: Cluster
ports:
- nodePort: 30800 #新加配置(端口低于30000 会有报错提示)
port: 443
protocol: TCP
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
sessionAffinity: None
type: NodePort #注意这行。(2) 创建dashboard admin-token(仅master上执行)
cat >/root/admin-token.yaml<
Annotations: kubernetes.io/service-account.name: admin
kubernetes.io/service-account.uid: edd03a18-38dc-4077-9eb5-41985cfa4115
Type: kubernetes.io/service-account-token
Data
====
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjJic3VKRlh5WUlBSkhzcmNVSUdXSmpqNzU0dXVGaFc0bXdSd1RyZ3hWTmcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1oOWNmciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImVkZDAzYTE4LTM4ZGMtNDA3Ny05ZWI1LTQxOTg1Y2ZhNDExNSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTphZG1pbiJ9.bx28HZI3UzpDEYmG9i3Km_RHAYIi3PLat6IEfGl79O2PGkk3o6mwPq2n_O9CRzLiu9Pcr0i8AeZkO3u1OIONmfCpyKUxBb0T8kdylRIZMowJKxQs_vICb9lnor7-rHN16JxgBANlgxC9uDvdjnAXiw1DmNtdzpOXmScBYnQbcnjUxCMp14rypljUusYWHt6wuH_gP1WK5t_CwhDI3jqMFC0WrRUwybgXtFtDZKXDx5mW-OH7Omc1Xrdbm3vz-USo2hzrcx6De6h55ACXUJkWTk2Lw3FnJ98ZFhxJ0KrbCm-if9a63tNDEl4IfYKY1OveysJgbTyPQW-0Gd-zeh8MmA
ca.crt: 1025 bytes
namespace: 11 bytes
(3) 登录dashboardhttps://192.168.44.132:30800/,选择token登录。
(4)对于不能连接外网的环境,需要导出images
docker images 获取dashboard 的镜像信息,然后导出
docker save -o ./dashboard-v2.0.0-rc7.tar kubernetesui/dashboard
docker save -o ./metrics-scraper-v1.0.4.tar kubernetesui/metrics-scraper
我们可以从https://github.com/kubernetes/dashboard/releases上边找到和自己安装的k8s相对于的dashboard的版本
修改配置文件:修改imagePullPolicy为IfNotPresent
imagePullPolicy: IfNotPresent
14、删除节点
移除节点和集群
kubernetes集群移除节点
以移除k8s-node2节点为例,在Master节点上运行:
kubectl drain k8s-node2 --delete-local-data --force --ignore-daemonsets
kubectl delete node k8s-node2
上面两条命令执行完成后,在k8s-node2节点执行清理命令,重置kubeadm的安装状态:
kubeadm reset
在master上删除node并不会清理k8s-node2运行的容器,需要在删除节点上面手动运行清理命令。
如果你想重新配置集群,使用新的参数重新运行kubeadm init或者kubeadm join即可。
15、安装helm(暂时跳过,未经过验证)
由于helm3 和helm 2 的差异比较大,此步骤还需要验证。
(1)客户端安装
cd /path/to/helm-v2.11.0-linux-amd64.tar/
tar -xzvf helm-v2.11.0-linux-amd64.tar
cd linux-amd64
cp helm /usr/local/bin
#helm init --service-account=kubernetes-dashboard-admin --skip-refresh --upgrade
helm version
卸载helm:
如果你需要在 Kubernetes 中卸载已部署的 Tiller,可使用以下命令完成卸载。
$ helm reset 或
$helm reset --force
(2)Helm服务端安装Tiller
注意:先在 K8S 集群上每个节点安装 socat 软件(yum install -y socat ),不然会报错。
Tiller 是以 Deployment 方式部署在 Kubernetes 集群中的,只需使用以下指令便可简单的完成安装。
helm init --history-max 200
--history-max建议将helm init 设置为configmaps,如果未按最大限制清除,则helm历史记录中的其他对象的数量会增大。如果没有设置最大历史记录,则无限期地保留历史记录,留下大量的记录以供维护和分舵。
由于 Helm 默认会去 storage.googleapis.com 拉取镜像,如果你当前执行的机器不能访问该域名的话可以使用以下命令来安装:
tiller和helm版本要一致,否则会出错
helm init --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v3.1.0 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts在 Kubernetes 中安装 Tiller 服务,因为官方的镜像因为某些原因无法拉取,使用-i指定自己的镜像,可选镜像:registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.9.1(阿里云),该镜像的版本与helm客户端的版本相同,使用helm version可查看helm客户端版本。
如果在用helm init安装tiller server时一直部署不成功,检查deployment,根据描述解决问题。
Tiller 安装:
Tiller 是以 Deployment 方式部署在 Kubernetes 集群中的,只需使用以下指令便可简单的完成安装。
# helm init
离线安装执行下面命令:
helm init --service-account=kubernetes-dashboard-admin --skip-refresh --upgrade
helm version
给Tiller 授权
给 Tiller 授权
因为 Helm 的服务端 Tiller 是一个部署在 Kubernetes 中 Kube-System Namespace 下 的 Deployment,它会去连接 Kube-Api 在 Kubernetes 里创建和删除应用。
而从 Kubernetes 1.6 版本开始,API Server 启用了 RBAC 授权。目前的 Tiller 部署时默认没有定义授权的 ServiceAccount,这会导致访问 API Server 时被拒绝。所以我们需要明确为 Tiller 部署添加授权。
创建 Kubernetes 的服务帐号和绑定角色
$ kubectl create serviceaccount --namespace kube-system tiller
$ kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
为 Tiller 设置帐号
# 使用 kubectl patch 更新 API 对象
$ kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
deployment.extensions "tiller-deploy" patched
查看是否授权成功
$ kubectl get deploy --namespace kube-system tiller-deploy --output yaml|grep serviceAccount
serviceAccount: tiller
serviceAccountName: tiller
————————————————
16、安装prometheus
[root@Test01 prome]# kubectl apply -f namespace.yaml
namespace/ns-monitor created
[root@Test01 prome]# kubectl apply -f node-exporter.yaml
service/node-exporter-service created
error: unable to recognize "node-exporter.yaml": no matches for kind "DaemonSet" in version "apps/v1beta2"
根据提示:把DaemonSet 的改为apps/v1 即可
[root@Test01 prome]# vim node-exporter.yaml
[root@Test01 prome]# kubectl apply -f node-exporter.yaml
daemonset.apps/node-exporter created
service/node-exporter-service created
[root@Test01 prome]# kubectl get pods -n ns-monitor -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-55vrj 1/1 Running 0 24s 192.168.44.133 test02
node-exporter-n5sdk 1/1 Running 0 24s 192.168.44.132 test01
安装prometheus
[root@Test01 prome]# kubectl apply -f prometheus.yaml
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prometheus-conf created
configmap/prometheus-rules created
persistentvolume/prometheus-data-pv created
persistentvolumeclaim/prometheus-data-pvc created
service/prometheus-service created
error: unable to recognize "prometheus.yaml": no matches for kind "Deployment" in version "apps/v1beta2"
(1)prometheus报错:
[root@Test01 prome]# kubectl logs -f prometheus-8589b69fc9-98lxv -n ns-monitor
level=info ts=2020-04-30T08:24:41.849Z caller=main.go:298 msg="no time or size retention was set so using the default time retention" duration=15d
level=info ts=2020-04-30T08:24:41.849Z caller=main.go:333 msg="Starting Prometheus" version="(version=2.17.0, branch=HEAD, revision=39e01b369dbd78278ca63e54f4976dff3b41df98)"
level=info ts=2020-04-30T08:24:41.849Z caller=main.go:334 build_context="(go=go1.13.9, user=root@604d4517e800, date=20200324-17:04:11)"
level=info ts=2020-04-30T08:24:41.849Z caller=main.go:335 host_details="(Linux 3.10.0-1062.18.1.el7.x86_64 #1 SMP Tue Mar 17 23:49:17 UTC 2020 x86_64 prometheus-8589b69fc9-98lxv (none))"
level=info ts=2020-04-30T08:24:41.849Z caller=main.go:336 fd_limits="(soft=52706963, hard=52706963)"
level=info ts=2020-04-30T08:24:41.849Z caller=main.go:337 vm_limits="(soft=unlimited, hard=unlimited)"
level=error ts=2020-04-30T08:24:41.853Z caller=query_logger.go:87 component=activeQueryTracker msg="Error opening query log file" file=/prometheus/queries.active err="open /prometheus/queries.active: permission denied"
panic: Unable to create mmap-ed active query log
创建nfs 的目的是为了避免数据丢失,这样做的原因是需要把prometheus 的数据路径映射出来,避免容器删除后历史监控数据丢失。
chown 65534:65534 data/
而更改文件所有者只是为了解决 open /prometheus/lock: permission denied 的报错。之后重新启动prometheus
(2)查看端口映射关系
[root@Test02 grafana]# kubectl get svc -n ns-monitor
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
node-exporter-service NodePort 10.1.16.46
prometheus-service NodePort 10.1.93.96
访问http://192.168.44.133:30891/graph
17、安装grafana
查看报错信息
kubectl logs -f grafana-7d64f448cc-c5tc5 -n ns-monitor
GF_PATHS_DATA='/var/lib/grafana' is not writable.
You may have issues with file permissions, more information here: http://docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later
mkdir: can't create directory '/var/lib/grafana/plugins': Permission denied原因:grafana_data目录权限不足。
解决办法:chown 472:472 data -R
(1)配置grafana:把prometheus配置成数据源
我们这个地方配置的数据源是 Prometheus,所以选择这个 Type 即可,给改数据源添加一个 name:prometheus,最主要的是下面HTTP区域是配置数据源的访问模式。
访问模式是用来控制如何处理对数据源的请求的:
- 服务器(Server)访问模式(默认):所有请求都将从浏览器发送到 Grafana 后端的服务器,后者又将请求转发到数据源,通过这种方式可以避免一些跨域问题,其实就是在 Grafana 后端做了一次转发,需要从Grafana 后端服务器访问该 URL。
- 浏览器(Browser)访问模式:所有请求都将从浏览器直接发送到数据源,但是有可能会有一些跨域的限制,使用此访问模式,需要从浏览器直接访问该 URL。
由于我们这个地方 Prometheus 通过 NodePort 的方式的对外暴露的服务,所以我们这个地方是不是可以使用浏览器访问模式直接访问 Prometheus 的外网地址,但是这种方式显然不是最好的,相当于走的是外网,而我们这里 Prometheus 和 Grafana 都处于 kube-ops 这同一个 namespace 下面,是不是在集群内部直接通过 DNS 的形式就可以访问了,而且还都是走的内网流量,所以我们这里用服务器访问模式显然更好,数据源地址:http://prometheus-service.ns-monitor:9090(或者prometheus:9090)(因为在同一个 namespace 下面所以直接用 Service 名也可以),然后其他的配置信息就根据实际情况了,比如 Auth 认证,我们这里没有,所以跳过即可,点击最下方的Save & Test提示成功证明我们的数据源配置正确:

(2)然后导入Dashboard
再把 kubernetes的Dashboard的模板导入进来显示:直接把JSON格式内容复制进来就行

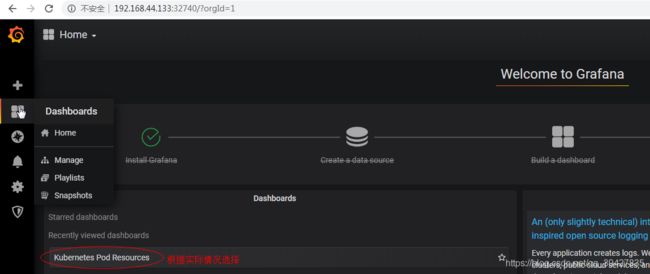
备注:
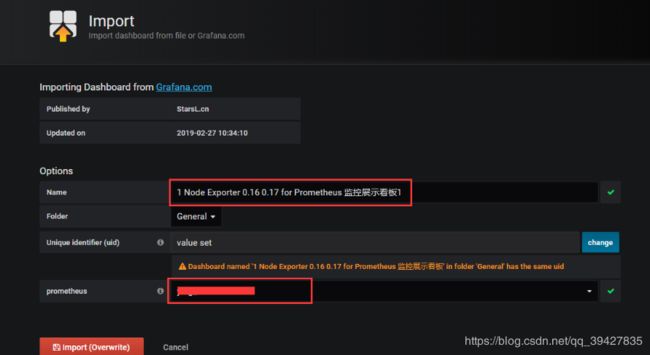
也可以在点击 import,在右侧输入dashboard id 8919,会出现如下界面,可以修改name,选择刚刚添加的datasource数据源,点击 importdashboard id 怎么获取,grafana官方有个中央仓库,和maven仓库一样,收集了网友制作好的dashboard,每个dashboard有个唯一 id,dashboard仓库地址:https://grafana.com/dashboards
监控图形展示如下:
