点击页面上的按钮后更新TextView的内容,谈谈你的理解?(阿里面试题 参照Alvin笔记 Handler源码解析)
阿里面试题:
点击页面上的按钮后更新TextView的内容,谈谈你的理解?
首先,这个一个线程间通信的问题,可以从Handler的角度进行解释,可以从五个角度分析这个问题:
1、需要在主线程更新UI,不能在子线程更新UI(Only the original thread that created a view hiearchy can touch its views);
2、需要在子线程创建Handler,并且需要为这个Handler准备Looper,否则会报错(Can't create handler inside thread
that has not called Looper.prepare() );
3、Handler使用不当可能引起的内存泄漏(OOM,在所有的OOM问题,因为handler使用不当而导致OOM是最多的);
4、Message的优化(最好使用Handler.obtainMessage() ,直接new Message会带来内存的消耗 );
5、在Handler把消息处理完了以后,但是页面销毁了,这个时候可能Handler会更新UI,但是比如
textview、imageview之类的资源引用不见了,就会抛出NullPointer Exception异常;
Handler整体框架,看源码最忌讳看细节,容易迷失,应该先了解框架,再看类的基本关系,然后再
深入源码分析。
一、Handler能做什么?
1、处理延时任务:设定将来某个时间处理某个事情;
2、线程间通信:主线程和子线程间的通信;
以下为相关图解:
图一:Handler、Message、MessageQueue、Looper、Thread
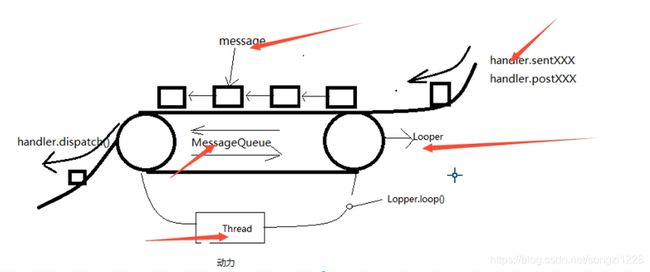
从上图中可以看出,要想理解上图,先要理解五个类:
Message、Handler、Looper、MessageQueue、Thread。前四个大家都知道,但是Thread大家可能就不太关注了,因为Thread一直在背后默默为这个通信在做一些事情。
看源码要先从我们经常使用的地方看起,例如:这就是我们经常使用Handler和Message的场景:
Message message = handler.obtainMessage();
handler.sendMessage(message);
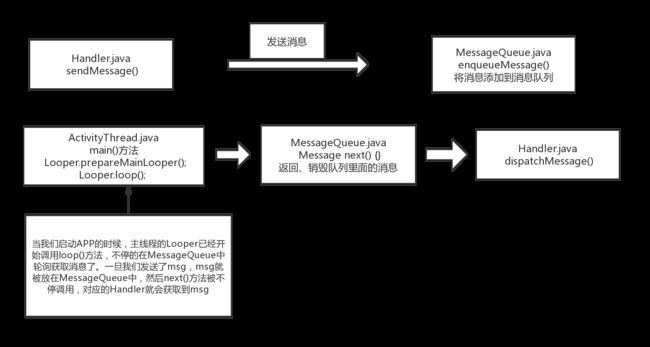
参照使用流程进行解读:
handler.sendMessage() ----> 发送消息 ----> MessageQueue.enqueueMessage(),
ActivityThread----> Looper.loop() ----> MessageQueue.next() 返回、销毁队列里面的消息
--> msg.target.dispatchMessage(msg);
msg.target.dispatchMessage(msg);
Looper.java
public static void loop() {
for (;;) {
Message msg = queue.next(); // might block
try {
msg.target.dispatchMessage(msg);
end = (slowDispatchThresholdMs == 0) ? 0 : SystemClock.uptimeMillis();
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
}
}
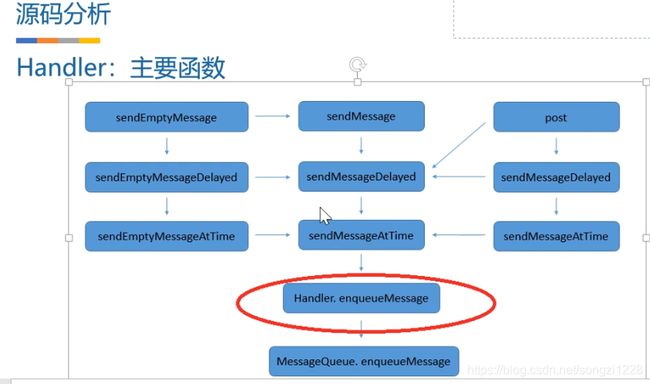
图二:Handler主要函数即流程
图三:MessageQueue流程
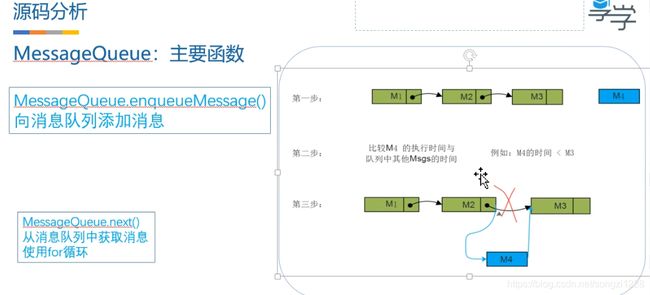
M1、M2和M3是现有的消息队列,当M4加入队列时,会比较M4和队列中其他消息(即M1、M2和M3)的执行那个时间,然后把M4放在合适的位置(在上图中M4的时间小于M3的时间,即M4需要先被执行,所以M4插入到M3之前),然后,按照时间的先后顺序挨个取出消息。
源码体现:MessageQueue.enqueueMessage(Message msg, long when)
boolean enqueueMessage(Message msg, long when) {
Message p = mMessages;
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
//当前消息的执行时间小于队列中某个消息的时间,就break跳出for循环
break;
}
}
//跳出循环后,插入该消息
msg.next = p;
prev.next = msg;
}MessageQueue中有一个 Message next() 方法:
Message next() {
for (;;) {
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
}
}
}该方法对消息队列的Messages进行轮询,当该消息的执行时间到了,就return msg,即跳出循环,发送消息。然后,就跳转到下一个消息继续执行此逻辑。(这就是next的含义,这个消息处理了,就处理下一个消息)。
那么,这个next()方法是由谁调用的呢?
Looper.loop()
public static void loop() {
for (;;) {
Message msg = queue.next(); // might block
try {
//分发消息 消息处理完毕
msg.target.dispatchMessage(msg);
end = (slowDispatchThresholdMs == 0) ? 0 : SystemClock.uptimeMillis();
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
}
}
图四:MessageQueue消息入队、出队
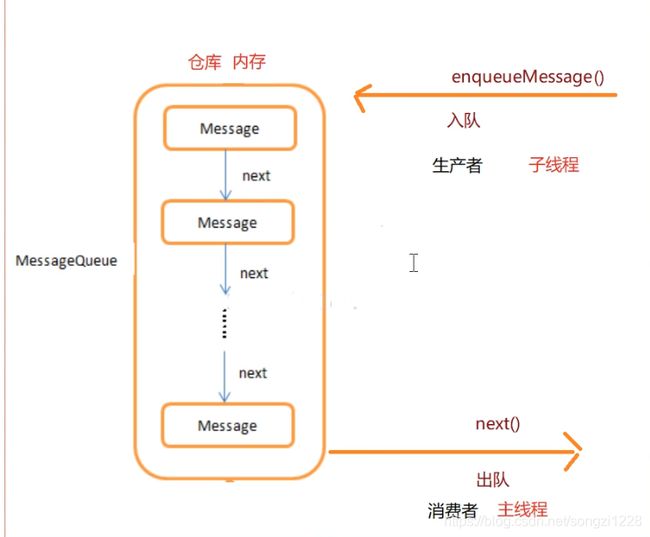
上图完美解释了Handler是怎么完成线程间通信这个问题的,通过MessageQueue的这种生产者消费者模式实现了线程间消息的传递。主线程和子线程都是从内存中存取消息,这样就巧妙的实现了跨线程,因为内存是共有的,无论什么线程都是可以使用内存的。

那么,源码中是怎么实现阻塞呢?让我们来看一看
首先是入队阻塞:
MessageQueue.java
// 有native标识,说明这是内核Linux方法,这是内核需要执行的操作
private native void nativePollOnce(long ptr, int timeoutMillis);
Message next() {
//如果nextPollTimeoutMillis大于0,就会调用该方法,让线程阻塞,这里调用的Linux内核的方法让MessageQueue阻塞
nativePollOnce(ptr, nextPollTimeoutMillis);
for (;;) {
final long now = SystemClock.uptimeMillis();
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
// 若干msg的时间大于当前,即msg需要在未来某个时间来执行
// nextPollTimeoutMillis就是这个时间差, 即需要多久来执行该msg
nextPollTimeoutMillis = (int) Math.min(msg.when - now,
Integer.MAX_VALUE);
}
}
}
}然后是出队阻塞:
MessageQueue.java
//通过Linux层唤醒队列
private native static void nativeWake(long ptr);
boolean enqueueMessage(Message msg, long when) {
boolean needWake;
if (needWake) {
nativeWake(mPtr);
}
}
ThreadLocal:
ThreadLocal 简单可以理解为一个HashMap
key值存储的是是ThreadID,即线程ID
value值存储的是对应的Looper,从这个层面理解一个Thread对应绑定一个Looper
使用这种数据结构,实现了线程隔离的目标
源码理解:Looper.java
static final ThreadLocal
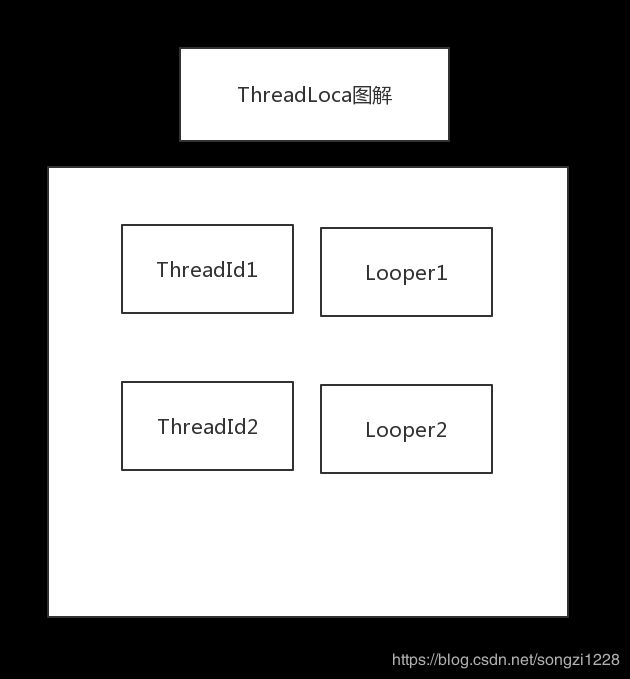
既然ThreadLocal跟HashMap很像,为什么不直接用HashMap?
一、HashMap太大了,太臃肿了,用不了那么多功能,ThreadLocal的key值只有一种,那就是线程,其他类型的
数据(string,int等)都用不到。ThreadLocal参照了HashMap的同时,加以简化,方便我们使用。
二、需要考虑线程隔离。每一个线程都是唯一的,使用ThreadLocal能够更好地管理Thread。