hadoop:IDEA本地编写mapreducer的wordcount并测试,并上传到hadoop的linux服务器进行测试
1.首先确认linux服务器安装好了hadoop
安装教程:http://blog.csdn.net/sunweijm/article/details/78399726
2.使用IDEA编写mapreducer的demo.
2.1 IDEA创建一个maven项目,项目名称为WordCount
2.2 配置Project Settings的Modules
在IDEA的Project Structure中:选择左侧的Modules:见下图的0处,然后点击最右侧的+,见1处,然后再点击JARs or directories, 见2处,然后添加:见3处。
common
hdfs
mapreduce
yarn
comom/lib来源于hadoop的本地windows的工程。
ps:关于windows本地的部署:http://blog.csdn.net/sunweijm/article/details/78427815

2.3 配置Project Settings的Artifacts
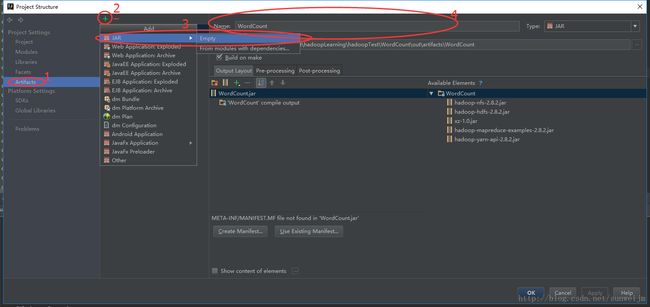
首先点击Artifacts,见1处
然后 点击+ 》JAR 》Empty,在Name上,填写:WordCount. 见4处。
然后添加Module Output,点击中间的+号,见下图的5、6处,在弹出的选框中选择WordCount。这样输出的mapreducer的jar包将会在Output directory中配置的地址中,见7处。

2.4 编写mapreducer的代码
源码如下:参考http://blog.csdn.net/zxk1992jx/article/details/73927434中的代码:
mapper:
package com.hadoop.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Created by Sunwei on 2017/11/6.
*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// IntWritable one=new IntWritable(1);
//得到输入的每一行数据
String line=value.toString();
StringTokenizer st=new StringTokenizer(line);
//StringTokenizer "kongge"
while (st.hasMoreTokens()){
String word= st.nextToken();
context.write(new Text(word),new IntWritable(1)); //output
}
}
}reducer:
package com.hadoop.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by Sunwei on 2017/11/6.
*/
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable iterable, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable i:iterable){
sum=sum+i.get();
}
context.write(key,new IntWritable(sum));
}
}
main:
package com.hadoop.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Created by Sunwei on 2017/11/6.
*/
public class WordCount {
public static void main(String[] args){
//创建配置对象
Configuration conf=new Configuration();
try{
//创建job对象
Job job = Job.getInstance(conf, "word count");
//Configuration conf, String jobName
//设置运行job的类
job.setJarByClass(WordCount.class);
//设置mapper 类
job.setMapperClass(WordCountMapper.class);
//设置reduce 类
job.setReducerClass(WordCountReducer.class);
//设置map输出的key value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce 输出的 key value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交job
boolean b = job.waitForCompletion(true);
if(!b){
System.out.println("wordcount task fail!");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
编写完之后可以在本地进行测试:
配置Run/Debug Configurations:,配置的重点我已经圈出来了,见下图:
主要有Name、Main class、 Program arguments

Program arguments我配的是:
D:********\hadoopTest\WordCount\input
D:********\hadoopTest\WordCount\output
需要按照上述目录创建input目录,output目录不需要创建,否则运行该demo会报错。
然后在本机的input中放入文件:可以自己写几个文件,我放入的文件有:
test1.txt:
hello worldtest2.txt :
hello hadoopstest3.txt :
hello sunwei点击运行:
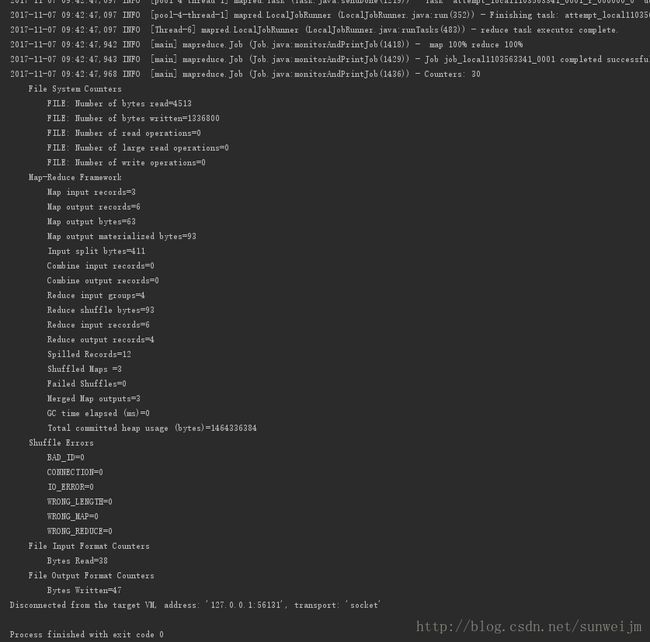
运行成功之后到D:********\hadoopTest\WordCount\output这个目录下查看part-r-00000文件:
hadoops 1
hello 3
sunwei 1
world 1如果运行报错,则需要配置好hadoop的本地环境,见:http://blog.csdn.net/sunweijm/article/details/78427815
2.5 用IDEA打包WordCount.jar包:
点击IDEA的Build》Build Artifacts》WordCount》Build,将会在2.3步中的Output directory的目录中出现WordCount.jar包。
3 上传jar包部署到hadoop服务器中
3.1 上传jar包
首先将WordCount.jar包上传到centos7中的任何一个文件夹。
我上传的目录:/usr/local/hadoop/hadoopMYJAR
3.2 在HDFS创建相应文件夹
3.2.1. 首先在HDFS中创建用户目录
[hadoop@vdevops ~]$ hdfs dfs -mkdir -p /user/hadoop3.2.2. 在HDFS中创建input目录
[hadoop@vdevops ~]$ hdfs dfs -mkdir input3.2.3. 删除input文件夹下的文件
[hadoop@vdevops ~]$ hdfs dfs -rm -r /user/hadoop/input/* 3.2.4. 将测试文件test1.txt、test2txt、test3.txt上传到hadoop服务器中,我放入的目录是/usr/local/hadoop/input/input1中:
进入input1,将这三个txt文件上传到HDFS中:
[hadoop@vdevops input1]$ hdfs dfs -put *.txt /user/hadoop/input #将input1文件夹下的文件上传到hdfs的/user/hadoop/input/下
##查看HDFS的/user/hadoop/目录中文件
[hadoop@vdevops ~]$ hdfs dfs -ls /user/hadoop/input #查看input目录下的文件
[hadoop@vdevops ~]$ hdfs dfs -ls input #我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input3.2.5.如果有,则删除HDFS中output目录(为了确保在运行wordcount前没有output目录):
[hadoop@vdevops hadoop]$ hadoop dfs -rmr /user/hadoop/output #删除output文件夹3.3. 运行WordCount.jar文件:
进入3.1步的hadoopMYJAR目录:
[hadoop@vdevops hadoopMYJAR]$ hadoop jar WordCount.jar WordCount /user/hadoop/input /user/hadoop/output
Exception in thread "main" java.lang.ClassNotFoundException: WordCount
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:227)
at org.apache.hadoop.util.RunJar.main(RunJar.java:148)报如上的错,需要指明具体的类名,修改成以下脚本就运行正确了:
[hadoop@vdevops hadoopMYJAR]$ hadoop jar WordCount.jar com.hadoop.wordcount.WordCount /user/hadoop/input /user/hadoop/output查看运行结果:
[hadoop@vdevops input1]$ hdfs dfs -cat /user/hadoop/output/part-r-00000
17/11/07 10:31:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hadoops 1
hello 3
sunwei 1
world 1