Android 内存优化实操,定位内存问题
文章目录
- 一、内存泄漏定位
- 1、观察法:
- 2、使用内存分析工具
- 2-1、收集内存快照
- 2-2、hprof文件转换
- 2-3、Mat分析内存
- 二、内存抖动
- 三、优化内存空间
- 1、减少不必要的内存开销
- 2、 使用最优的数据类型
- 3、使用 IntDef和StringDef 替代枚举类型
- 4、图片内存优化
- 5、图片放置优化
- 6、在App可用内存过低时主动释放内存
- 7、item被回收不可见时释放掉对图片的引用
- 四、总结
- 1、内存泄漏
- 2、内存抖动
- 3、使用轻量级的数据结构
一、内存泄漏定位
我们都知道,内存泄漏的根本原因就是:堆内存中的长生命周期的对象持有短生命周期对象的引用,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收。
内存泄漏会导致可用内存慢慢变少,让程序慢慢变卡。最终还会导致臭名昭著的oom 内存溢出。既然内存泄漏导致的问题如此严重,在开发中应该怎么排查内存泄漏问题呢?
-
观察法:
在Android中我们执行一段代码,比如进入了一个新的页面(Activity),这时候我们的内存使用肯定比在前一个页面大,而在界面finish返回后,如果内存没有回落,那么很有可能就是出现了内存泄漏。
从内存监控工具中观察内存曲线,是否存在不断上升的趋势且不会在程序返回时明显回落。这种方式可以发现最基本,也是最明显的内存泄露问题,对用户价值最大,操作难度小,性价比极高。
-
内存分析工具:MAT
1、观察法:
当运行App之后,在AS的底部工具栏中有:Profiler,打开,选择需要观察的App进程,即可看到App的内存,CPU,网络等使用情况,这里我们选择:Memory,即内存。就可以观察到App内存的具体使用情况。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eEVVr9Wk-1596540108425)(https://raw.githubusercontent.com/meiSThub/BlogImage/master/image-20200728173858994.png)]
2、使用内存分析工具
2-1、收集内存快照
Android Studio为我们提供了内存分析工具:Profile,点开之后,如下图所示:

双击上图的MEMORY区域,就可以进入内存分析模块,进去之后,操作App,进入推出页面,触发GC,等待一会Dump一份内存快照,Android Studio就会列出内存中对象的详细情况,如下图:
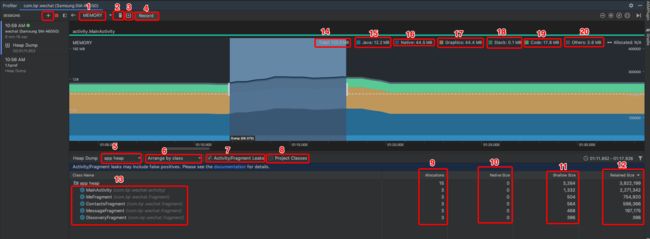
上图有很多的功能模块,下面详细介绍具体功能:
- memory:功能模块,这里选择查看内存:memory
- Force garbage collection:手动触发GC,回收内存
- Dump Java heap:保存一份内存快照
- Record:记录一段时间内存,内存中对象的分配情况
- App heap:选择堆内存空间,这里选择App的堆内存,还有:image heap,zygote heap等。
- Arrange by class:排序类型。对dump后的内存中的类,进行排序,可选有:Arrange by class(安装类排序),Arrange by package(包名排序)和Arrange by callstack(调用栈排序)
- Activity/Fragment Leaks:过滤可能泄漏的Activity和Fragment,对Dump下来的内存,初步分析可能泄漏的Activity或者Fragment
- Project Classes:工程的类泄漏过滤
- Al locations:对象个数
- Native Size:native对象占用内存大小
- Shallow Size:对象占用的内存大小
- Retained Size:对象本身和对象引用的所有对象一共占用的内存大小
- 类对象
从上图可以看出,当我们勾选:Activity/Fragment Leaks或者Project Classes的时候,Android Studio就会为我们分析出可能泄漏的类,如果Allocations中对象的个数超过1个,就有可能发生内存泄漏,这就为我们缩小了内存泄漏的范围。
点击可能泄漏的类,Android Studio就会列出类的对象和对象的引用关系,如下图:

- 点击MainActivity ,右边2处就会列出MainActivity的所有对象
- 此时内存中存在的MainActivity对象,这里可以看出,一共有5个对象
- 具体某一个对象的引用关系,把this$0一步一步的展开,如果是简单的内存泄漏,这里就可以直接看出MainActivity被谁引用着。
本例子中,类都是被混淆了的,看不出是具体是被哪个类引用着,此时我们就可以借助MAT工具,来分析更加详细的内存信息和引用链关系。
在使用Mat工具之前,我们需要把内存快照信息保存到文件当中,如下图:

- 内存快照图标,当我们Dump一份内存快照时,在这里就会生成一个Heap Dump的条目,这里代表的就是我们保存的那一份内存快照。
- 当鼠标移动到Heap Dump时,就会出现“2”这个图标,在这里就可以把这份内存快照信息导出并保存
- 除了点击“2”处的图标导出内存快照信息外,还可以右键点击“3”处的区域,对应的菜单有:Export选项,点击就可以保存。
通过Android Studio,获取一份内存快照信息,步骤如下:
-
进入Android Studio 的Profile 内存模块
-
操作App ,进入退出要分析的页面,反复几次。
-
点击GC图标,释放内存,这一步主要是把可以回收的内存回收到,避免为内存分析带来误导。内存泄漏的对象是不会被回收的。

-
点击Dump Java heap按钮,Dump一份内存快照信息。

-
选中Activity/Fragment Leaks或者Project Classes,分析可能泄漏的类

-
点击导出内存快照按钮,保存内存快照信息
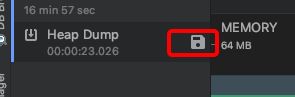
保存内存快照信息到指定的目录:
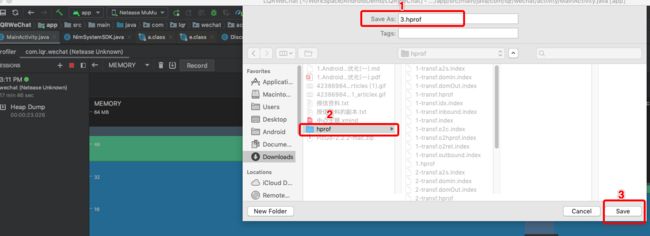
- 文件名
- 文件保存的路径
- 保存
2-2、hprof文件转换
MAT 全称是:Memory Analyzer ,下载地址为:https://www.eclipse.org/mat/downloads.php。下载解压就可以用,绿色软件。
在2-1中,通过Android Studio已经获取了一份内存快照信息文件:3.hprof,但是这个文件的格式,与Mat要求的格式不太一样,所以这里需要先把3.hprof文件转换成Mat可以识别的格式。
2-2-1、配置hprof-conv环境变量
在Android SDK中的platform-tools中,有一个hprof-conv命令,就可以把Android Studio生成的hprof文件,转换成Mat可以识别的hprof文件。
要想使用hprof-conv命令,需要先配置环境变量,把该命令加入到系统命令库中去。mac配置如下:
在命令行终端中,输入:
vim ~/.bash_profile
编辑该文件,加入如下代码,后面的路径就是你本地的Android SDK 的platform-tools文件夹路径
export PATH="$PATH:/Users/mei/Library/Android/sdk/platform-tools"
最后执行source命令,使配置生效:
source ~/.bash_profile
2-2-2、hprof文件转换:
配置好环境变量之后,就可以直接在命令行中使用:hprof-conv命令了。
下面就通过命令,把Android Studio生成的hprof文件,转换成Mat可以识别的hprof文件,命令如下:
hprof-conv -z 3.hprof 3-transf.hprof
参数说明:
- -z 表示排除非App的堆内存信息,如Zygote内存信息
- 3.hprof :通过Android Studio生成的hprof文件,如果命令行没有切换到该文件目录下,则需要使用绝对路径。
- 3-transf.hprof:转换后的文件,默认保存到命令行当前落在地目录下,可以通过绝对路径指定保存位置。
通过这条命令,就把Android Studio 生成的hprof转换成了mat可以识别的hprof文件。
2-3、Mat分析内存
打开Mat工具,在菜单栏中,选择file->Open File ,选择要刚才转换生成的3-transf.hprof文件。
在MAT窗口上,OverView是一个总体概览,显示总体的内存消耗情况和疑似问题。MAT提供了多种分析维度,其中Histogram、Dominator Tree、Top Consumers和Leak Suspects的分析维度是不同的。下面分别介绍下它们,如下所示:

功能介绍:
- Overivew: 总体概览
- Histogram:列出内存中的所有实例类型对象和其个数以及大小,并在顶部的regex区域支持正则表达式查找。更加适合较为复杂的内存泄漏分析。
- Dominator Tree:列出最大的对象及其依赖存活的Object。相比Histogram,能更方便地看出引用关系。
- Top Consumers:通过图像列出最大的Object。
- Leak Suspects:通过MAT自动分析内存泄漏的原因和泄漏的一份总体报告。
- Top Componects:
分析内存最常用的是Histogram和Dominator Tree这两个视图,点击Histogram进入直方图视图,一共有四列:
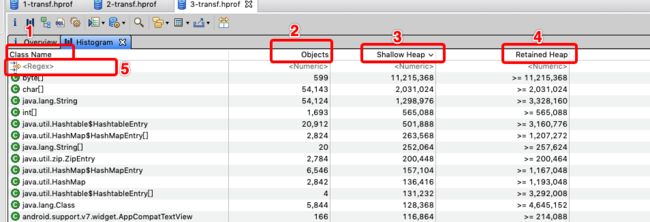
- ClassName:类名
- Objects:对象实例个数
- Shallow Heap:对象自身占用的内存大小,不包括它引用的对象。非数组的常规对象的Shallow Heap Size由其成员变量的数量和类型决定,数组的Shallow Heap Size由数组元素的类型(对象类型、基本类型)和数组长度决定。真正的内存都在堆上,看起来是一堆原生的byte[]、char[]、int[],对象本身的内存都很小。因此Shallow Heap对分析内存泄漏意义不是很大。
- Retained Heap:是当前对象大小与当前对象可直接或间接引用到的对象的大小总和,包括被递归释放的。即:Retained Size就是当前对象被GC后,从Heap上总共能释放掉的内存大小。
- Regex:按照给定的名称过滤类
这里的类信息有很多,不好查找,这时候就可以结合Android Studio给我们提示的泄漏对象,来过滤,缩小查找的范围。如:MainActivity。
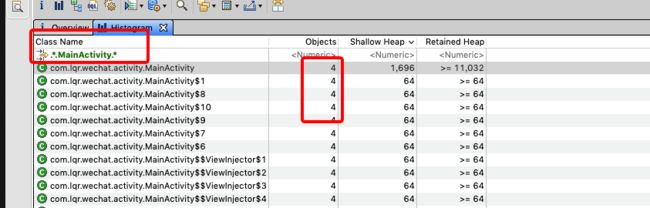
根据MainActivity过滤之后,可以看到,在触发GC之后的内存中,MainActivity的对象还有4个,这肯定就是发生了内存的泄漏。那如何查找MainActivity是如何泄漏的呢?
这里右键点击MainActivity,选择菜单:Merge Shortest Paths to GC Roots->exclude all phantom/weak/soft etc. references。如下图:

- 右键点击MainActivity
- Merge Shortest Paths to GC Roots:生成该对象到GC Roots最短路径
- exclude all phantom/weak/soft etc. references:排除虚引用、弱引用和软引用,即只看强引用。
这里排出软弱虚等引用,避免对内存泄漏的分析带来影响。确定之后,Mat就会为我们生成GC Root的引用链关系图,通过这个就可以分析出是哪个对象引用着MainActivity,造成MainActivity无法释放,导致的内存泄漏。
生成的GC Root 引用链关系图如下:
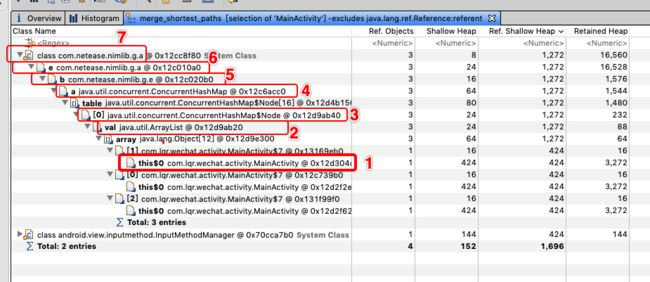
把生成的引用链一步一步展开,如上图所示。现在就来分析一下引用链关系图:
- this$0 : MainActivity的对象
- ArrayList:MainActivity的对象被ArrayList内的array数组引用着。
- ConcurrentHashMap$Node:从这里可以看出,ArrayList的对象又被ConcurrentHashMap的Node节点引用着。
- ConcurrentHashMap:HashMap中有一个table数组,引用着Node节点。
- com.netease.nimlib.g.e:从第五点可以看出,ConcurrentHashMap的对象a被 类:com.netease.nimlib.g.e的对象引用着
- com.netease.nimlib.g.a:com.netease.nimlib.g.e类的对象b被类:com.netease.nimlib.g.a的对象e引用着
- com.netease.nimlib.g.a:类中有一个成员变量:e,引用着com.netease.nimlib.g.e的对象b。
通过上面的分析,最终定位到类com.netease.nimlib.g.a中的成员变量e,打开源码看可以发现,e是一个静态变量,保存了所有的观察者对象,观察者又持有MainActivity的引用,所以导致了MainActivity的泄漏。变量 e中保存了所有注册过的观察者,开发者在注册观察者的时候,没有在onDestory方法中解注册,所以导致了MainActivity的内存泄漏。知道原因后,把所有的观察者在onDestory()方法中解注册之后,发现MainActivity就没有泄漏了。
通过Mat查找内存泄漏步骤:
- 打开符合Mat格式的hprof文件
- 在概览页面,打开直方图:Histogram
- 根据Android Studio提示的泄漏信息,过滤对象信息
- 右键选中可能泄漏的类,选择Merge Shortest Paths to GC Roots,生成对象到GC Root的最短路径,即GC Root引用链
- 展开引用链,分析对象被谁引用着,导致无法释放,并解决内存泄漏。
通过上面的方法,一步步分析,就可以找到内存泄漏的原因,至此,内存泄漏的定位和解决方法就讲完了。
二、内存抖动
内存抖动就是在短时间内,创建了大量的对象,导致频繁的分配内存和触发GC操作,从而使App卡顿。
打开Android Studio的Profile,选择内存,操作App卡顿的页面,点击Record记录一段时间内的内存分配情况,这时Record按钮就会变成Stop按钮,当时间够了的时候,就可以点击Stop按钮,暂停录制。就如生成如下图所示的内存快照图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TyuwzIh4-1596540108444)(https://raw.githubusercontent.com/meiSThub/BlogImage/master/image-20200804105514086.png)]
模块详解:
-
Record:开始记录内存快照信息,开始后Record按钮就会变成Stop按钮,可暂停。
-
内存中对象类型,即类名。
-
Allocations:对象个数
-
Deallocations:
-
Total Count:
-
Shallow Size:对象占用的内存大小。
-
点击2处暂用内存最大的对象,就会出现7处的对象列表
-
点击7处的对象列表中的某一个对象,就会出现8处的详细信息,在这里可以看出java/lang/String是在MainActivity的内部类Adapter中的onBindViewHolder方法中分配的,找到此处代码,发现在绑定数据的时候,频繁的创建String对象。优化之后,就没有卡顿了。
这里的操作跟定位内存泄漏 不太一样,不需要先GC,在录制,而是直接录制就可以了,这样就可以看出内存在这一段时间内的分配情况。
我们都知道,内存抖动是由于在短时间内创建了大量的对象,导致频繁的分配内存和回收内存,所以在日常编码中,我们应该从如下方法去避免内存抖动的发生:
- 尽量避免在循环体内创建对象,应该把对象创建移到循环体外。
- 注意自定义View的onDraw()方法会被频繁调用,所以在这里面不应该频繁的创建对象。
- 当需要大量使用Bitmap的时候,试着把它们缓存在数组中实现复用。
- 对于能够复用的对象,同理可以使用对象池将它们缓存起来。
- 大量的字符串拼接,使用StringBuilder或者StringBuffer。
三、优化内存空间
1、减少不必要的内存开销
-
AutoBoxing
自动装箱的核心就是把基础数据类型转换成对应的复杂类型。在自动装箱转化时,都会产生一个新的对象,这样就会产生更多的内存和性能开销。如int只占4字节,而Integer对象有16字节,特别是HashMap这类容器,进行增、删、改、查操作时,都会产生大量的自动装箱操作。
检测方式
使用TraceView查看耗时,如果发现调用了大量的integer.value,就说明发生了AutoBoxing。
-
内存复用
对于内存复用,有如下四种可行的方式:
- 资源复用:通用的字符串、颜色定义、简单页面布局的复用。
- 视图复用:可以使用ViewHolder实现ConvertView复用。
- 对象池:显示创建对象池,实现复用逻辑,对相同的类型数据使用同一块内存空间。
- Bitmap对象的复用:使用inBitmap属性可以告知Bitmap解码器尝试使用已经存在的内存区域,新解码的bitmap会尝试使用之前那张bitmap在heap中占据的pixel data内存区域。
2、 使用最优的数据类型
2-1、HashMap源码分析
在Android开发时,我们使用的大部分都是Java的api。其中我们经常会用到java中的集合,比如HashMap。使用HashMap非常舒服,但是对于Android这种内存敏感的移动平台,很多时候使用这些java的api并不能达到更好的性能,相反反而更消耗内存,所以针对Android,google也推出了更符合自己的api,比如SparseArray、ArrayMap用来代替HashMap在有些情况下能带来更好的性能提升。
我们可以先来看看HashMap的实现:
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
平时我们使用HashMap一般会new一个对象,使用无参的构造方法,我们看到注释中的说明,默认容量为16,加载因子是0.75。 但是我们现在new出hashmap不会初始化这个16个容量大小的容器。直到我们通过put方法保存数据的时候,才会去初始化:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 1. 把数据存入数组中
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 第一次put,tab是没有初始化的,所以会进入这个分支,即会调用resize()方法去初始化数组,和默认的容量大小
if ((tab = table) == null || (n = tab.length) == 0) // 1
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 2. 根据存储数据数量与设定的阈值相比,如果超过阈值,则进行扩容
if (++size > threshold) // 如果容量超过了阈值,则进行扩容
resize();
afterNodeInsertion(evict);
return null;
}
从上面代码可以看出,put方法主要做了两件事:
- 把数据存入数组中
- 扩容:根据存储数据数量与设定的阈值相比,如果超过阈值,则进行扩容
而在第一次put保存数据的时候,table数组是没有被初始化的,所以会进入到第一个if语句中,调用resize()方法:
final Node<K,V>[] resize() {
// 1. 计算数组容量和扩容阈值
Node<K,V>[] oldTab = table;// 第一次,table是为空的
int oldCap = (oldTab == null) ? 0 : oldTab.length;// 第一次,oldCap==0
int oldThr = threshold;// 第一次,threshold默认是0
int newCap, newThr = 0;
if (oldCap > 0) {// 扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}// 容量增加一倍,左移1位,即oldCap*2
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 阈值也增加一倍 左移1位,即oldThr*2
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;// 第一次,初始化存储容量,默认值是:16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);// 第一次,阈值是:16*0.75
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;// 保存阈值,第一次阈值为:16*0.75=12
// 2. 根据数组容量,创建数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];// 根据容量,创建对应大小的数组
table = newTab;// 把新创建的数组,赋值给全局变量:table,数组初始化完成。
// 3. 判断是否需要拷贝数据,需要则把老数组中的数据,都迁移到新数组中
if (oldTab != null) {// 第一次不会走这个,这个是Map存储容量到达阈值的时候的扩容操作
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {// 根据角标,取出老数组中存储的对象
oldTab[j] = null;
if (e.next == null)
// 如果该节点没有下一个节点,则根据hash值,计算对象在新数组中的的位置,并保存对象
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) // 如果对象是树形节点
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap的resize()方法主要完成了三件事:
- 计算数组的容量和扩容阈值,第一次容量为默认值16
- 根据数组容量,创建数组
- HashMap扩容后,数据从老数组迁移到新数组
这里我们看到,如果我们没有显示的指定HashMap的容量的话,一旦我们使用了这个HashMap,我们就需要创建一个大小为16的数组,哪怕我们只存储1-2个数据。
而我们put数据(put函数)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e1ZR1Jp4-1596540108444)(https://raw.githubusercontent.com/meiSThub/BlogImage/master/image-20200804143315195.png)]
如果我们的容量一旦大于threshold,就需要扩容:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
................
}
扩容的时候是在原来容量的基础上,扩大两倍:newCap = oldCap << 1,阈值也是变成原来的两倍:newThr = oldThr << 1。
所以我们16的容量会存储12个数据,而存储第13个数据,就需要24大小的数组。 这样带来的问题就是,容量是16的时候,只能存储12个数据,有4个不能用。32的容量,我们只能存储24个数据,32-24=8,有8哥位置不能用。
那么如果我们需要存储更多的数据,那么被浪费掉的容量也会越来越大,即浪费掉的内存越大。
HashMap存储数据通过他的内部类Node来存放的:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
.............
}
Node中有4个成员,分别存储key的hash值、key、value与下一个节点Node。
我们知道Java有自动装箱。如果我们的key确定了是int,那么我们使用HashMap的时候一般会写成HashMap
这也是HashMap带来的第二个浪费内存的问题。
综上所诉,HashMap带来的问题有:
- HashMap有阈值,当存储容量大于阈值时,就会进行扩容,导致HashMap存不满,HashMap越大,浪费的空间越多。
- 扩容时需要把老数组中的数据全部迁移到新数组中,频繁的扩容,会导致性能消耗。
- 对基本数据类型的自动装箱,导致暂用的内存增多。
- 如果Key值的Hash算法不合理,导致计算的数组角标总是重复,就会使同一位置存储的数据链比较长,导致性能降低。
2-2、SparseArray
通过2-1的分析,我们知道HashMap会有一些性能问题,哪有什么其它的代替方案呢?在Android中,某些情况我们可以使用SparseArray来替代HashMap。
下面就分析一下SparseArray的源码:
public class SparseArray<E> implements Cloneable {
private static final Object DELETED = new Object();
private boolean mGarbage = false;
@UnsupportedAppUsage(maxTargetSdk = 28) // Use keyAt(int)
private int[] mKeys; // 存放key值
@UnsupportedAppUsage(maxTargetSdk = 28) // Use valueAt(int), setValueAt(int, E)
private Object[] mValues;// 存放value
@UnsupportedAppUsage(maxTargetSdk = 28) // Use size()
private int mSize;// 存放的数据数量
/**
* Creates a new SparseArray containing no mappings.
*/
public SparseArray() {
this(10);// 默认构造函数,创建容量为10的数组
}
/**
* Creates a new SparseArray containing no mappings that will not
* require any additional memory allocation to store the specified
* number of mappings. If you supply an initial capacity of 0, the
* sparse array will be initialized with a light-weight representation
* not requiring any additional array allocations.
*/
public SparseArray(int initialCapacity) {
if (initialCapacity == 0) {
mKeys = EmptyArray.INT;
mValues = EmptyArray.OBJECT;
} else {
mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);
mKeys = new int[mValues.length];
}
mSize = 0;
}
SparseArray与HashMap不同,SparseArray在构造函数中就根据指定的容量初始化了存储key和value的数组,如果没有指定,则默认为容量为:10。SparseArray使用两个数组分别保存key与value,并且key必须是int。
接下来,看看SparseArray使如何插入数据的,SparseArray的put方法源码如下:
/**
* Adds a mapping from the specified key to the specified value,
* replacing the previous mapping from the specified key if there
* was one.
*/
public void put(int key, E value) {
// 1. 二分查找,确定角标
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
// 2. 如果角标大于0,即该key值已经存在,则直接修改该key对应的value就可以了
if (i >= 0) {
mValues[i] = value;
} else {
// 3. 如果角标小于0,则取反,即该key值之前没有存过,新值都会走这个分支
i = ~i;
if (i < mSize && mValues[i] == DELETED) { // 下标小于数量,则直接赋值
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
// 新值真正插入的地方
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
put()方法主要实现了如下功能:
- 通过对Key值的二分查找,确定角标i。
- 判断角标i是否大于0,大于0则表示key值已经存在,则直接替换原有value值
- 角标i小于0,则表示插入的值不在数组中,则需要把key和value都插入到角标i的位置
下面就来看看对key值进行二分查找,确定角标是如何实现的。ContainerHelpers的binarySearch方法代码如下:
/**
*
* @param array key值数组
* @param size 数量
* @param value key值
* @return
*/
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final int midVal = array[mid];
if (midVal < value) {
lo = mid + 1; // 当存入的key值,大于中间处的key,则改变lo的值
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid; // 有相同的key,则直接返回角标
}
}
// 从上面代码可以看出,lo只可能是大于等于0的,lo永远不会大于size
return ~lo; // 而在返回的时候,对lo进行了取反操作,则lo在这里返回的就一定是小于0的值
}
确定了角标之后,返回put()方法后,就会走到注释3处的else分支,进行保存key和value的操作。key和value的插入操作,是通过类GrowingArrayUtils的insert方法完成的,源码如下:
/**
* Inserts an element into the array at the specified index, growing the array if there is no
* more room.
*
* @param array The array to which to append the element. Must NOT be null.
* @param currentSize The number of elements in the array. Must be less than or equal to
* array.length.
* @param element The element to insert.
* @return the array to which the element was appended. This may be different than the given
* array.
*/
public static <T> T[] insert(T[] array, int currentSize, int index, T element) {
assert currentSize <= array.length;// 数组容量
// 1. 如果数组没有满,则直接存
if (currentSize + 1 <= array.length) {
System.arraycopy(array, index, array, index + 1, currentSize - index);
array[index] = element;
return array;
}
// 2. 数组已满,则扩容,growSize获取扩容之后的数组容量,创建新的数组
@SuppressWarnings("unchecked")
T[] newArray = ArrayUtils.newUnpaddedArray((Class<T>)array.getClass().getComponentType(),
growSize(currentSize));
// 3. 把老数组的数据都拷贝到新数组中
System.arraycopy(array, 0, newArray, 0, index);
// 4. 插入新值
newArray[index] = element;// 保存新插入的数据
System.arraycopy(array, index, newArray, index + 1, array.length - index);
return newArray;
}
/**
* Given the current size of an array, returns an ideal size to which the array should grow.
* This is typically double the given size, but should not be relied upon to do so in the
* future.
*/
public static int growSize(int currentSize) {
return currentSize <= 4 ? 8 : currentSize * 2;// 扩容,跟HashMap一样,按照当前容量的2倍扩容
}
根据GrowingArrayUtils的insert方法源码,做了如下操作:
- 判断数组是否已满,没满,则直接存
- 扩容:数组已满,则按照当前容量的2倍进行扩容,并创建新的数组。不同于HashMap的是,没有扩容因子。
- 数据迁移:把老数组的数据迁移到新数组中
- 保存新值到新数组中
分析了SparseArray的put方法,接下来看看SparseArray的数据获取方法get():
public E get(int key, E valueIfKeyNotFound) {
// 1. 二分查找,确定角标
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
// 2. 判断是否有值
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
// 3. 返回对应角标的value值
return (E) mValues[i];
}
}
get()方法比较简单,即确定角标,取值:
- 确定角标:跟保存方法一样,通过对Key值的二分查找,确定角标i。
- 判断是否有值或者该值是否被删除,如果是,则返回默认值:valueIfKeyNotFound,默认为null。
- 根据角标,返回对应的value值。
取值的过程,比HashMap的遍历数组来获得对应value要更快。
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显。
一般满足下面两个条件我们可以使用SparseArray代替HashMap:
- 数据量不大,最好在千级以内。
- key必须为int类型,这中情况下的HashMap可以用SparseArray代替。
2-3 、ArrayMap
ArrayMap是一个**
3、使用 IntDef和StringDef 替代枚举类型
使用枚举类型的dex的size是普通常量定义的dex的size的13倍以上,同时,运行时的内存分配,一个enum值的声明会消耗至少20bytes。
枚举最大的优点是类型安全,但在Android平台上,枚举的内存开销是直接定义常量的三倍以上。所以Android提供了注解的方式检查类型安全。目前提供了int型和String型两种注解方式:IntDef和StringDef,用来提供编译期的类型检查。
注意
使用IntDef和StringDef需要在Gradle配置中引入相应的依赖包:
compile ‘com.android.support:support-annotations:22.0.0’
4、图片内存优化
Bitmap这里不在详细介绍,后面会专门介绍。
5、图片放置优化
只需要UI提供一套高分辨率的图,图片建议放在drawable-xxhdpi文件夹下,这样在低分辨率设备中图片的大小只是压缩,不会存在内存增大的情况。如若遇到不需缩放的文件,放在drawable-nodpi文件夹下。
6、在App可用内存过低时主动释放内存
在App退到后台内存紧张即将被Kill掉时选择重写 onTrimMemory/onLowMemory 方法去释放掉图片缓存、静态缓存来自保。
7、item被回收不可见时释放掉对图片的引用
ListView:因此每次item被回收后再次利用都会重新绑定数据,只需在ImageView onDetachFromWindow的时候释放掉图片引用即可。
RecyclerView:因为被回收不可见时第一选择是放进mCacheView中,这里item被复用并不会只需bindViewHolder来重新绑定数据,只有被回收进mRecyclePool中后拿出来复用才会重新绑定数据,因此重写Recycler.Adapter中的onViewRecycled()方法来使item被回收进RecyclePool的时候去释放图片引用。
四、总结
通过上面对内存泄漏,内存抖动和优化内存等方面的介绍,我们可以通过如下方法优化内存:
1、内存泄漏
1-1、内存泄漏定位
- 按照包名类型分类进行实例筛选或直接使用顶部Regex选取特定实例。
- 右击选中被怀疑的实例对象,选择Merge Shortest Paths to GC Root->exclude all phantom/weak/soft etc references。(显示GC Roots最短路径的强引用)
- 分析引用链或通过代码逻辑找出原因。
1-2、避免内存泄漏:
-
资源性对象即时关闭,如:Cursor。
-
注册对象及时注销,如观察者对象等。
-
例如BraodcastReceiver、EventBus未注销造成的内存泄漏,我们应该在Activity销毁时及时注销。
-
类的静态变量持有大数据对象,尽量避免使用静态变量存储数据,特别是大数据对象,建议使用数据库存储。
-
单例造成的内存泄漏
-
非静态内部类的静态实例,该实例的生命周期和应用一样长,这就导致该静态实例一直持有该Activity的引用,Activity的内存资源不能正常回收。此时,我们可以将该内部类设为静态内部类或将该内部类抽取出来封装成一个单例,如果需要使用Context,尽量使用Application Context,如果需要使用Activity Context,就记得用完后置空让GC可以回收,否则还是会内存泄漏。
-
Handler临时性内存泄漏
-
容器中的对象没清理造成的内存泄漏,及时清理。如在退出程序之前,将集合里的东西clear,然后置为null,再退出程序
2、内存抖动
2-1、内存抖动的定位
- 操作抖动的页面,在Android Studio的Profile中,Record记录一段时间内存的内存快照
- 分析生成的内存快照图,定位暂用内存最大的对象
- 看对象的创建位置,分析代码,并解决内存抖动。
2-2、内存抖动的避免:
-
尽量避免在循环体内创建对象,应该把对象创建移到循环体外。
-
注意自定义View的onDraw()方法会被频繁调用,所以在这里面不应该频繁的创建对象。
-
当需要大量使用Bitmap的时候,试着把它们缓存在数组中实现复用。
-
对于能够复用的对象,同理可以使用对象池将它们缓存起来。
-
大量的字符串拼接,使用StringBuilder或者StringBuffer。
3、使用轻量级的数据结构
- 数据量小于1000的时候,如果key是int,使用SparseArray,如果不是,则使用ArrayMap。
- 如果要存储的数据量是确定的,可以在创建HashMap的时候,指定容量,避免反复扩容,带来的性能问题。
- 使用 IntDef和StringDef 替代枚举类型
- Bitmap内存优化
- 图片放置优化:图片建议放在drawable-xxhdpi文件夹下,这样在低分辨率设备中图片的大小只是压缩,不会存在内存增大的情况。如若遇到不需缩放的文件,放在drawable-nodpi文件夹下。
- 在App可用内存过低时主动释放内存
- item被回收不可见时释放掉对图片的引用