SeaWeedfs学习总结
SeaWeedfs学习总结
- 架构
- 基本原理
- 基本使用
- 上传文件(Write File)
- 修改文件(Write File)
- 删除文件(Write File)
- 查看文件(Read File)
- 文件ID含义解析:
SeaWeedfs最初是作为一个对象存储来有效地处理小文件的。central master不管理central master中的所有文件元数据,而只管理文件卷,它通过这些volume servers管理文件及其元数据。这减轻了来自central master的并发压力,并将文件元数据分散到卷服务器中,从而允许更快的文件访问(O(1),通常只有一个磁盘读取操作)。每个文件的元数据只有40字节的磁盘存储开销。
架构
官网描述:
Usually distributed file systems split each file into chunks, a central master keeps a mapping of filenames, chunk indices to chunk handles, and also which chunks each chunk server has.
The main drawback is that the central master can’t handle many small files efficiently, and since all read requests need to go through the chunk master, so it might not scale well for many concurrent users.
Instead of managing chunks, SeaweedFS manages data volumes in the master server. Each data volume is 32GB in size, and can hold a lot of files. And each storage node can have many data volumes. So the master node only needs to store the metadata about the volumes, which is a fairly small amount of data and is generally stable…
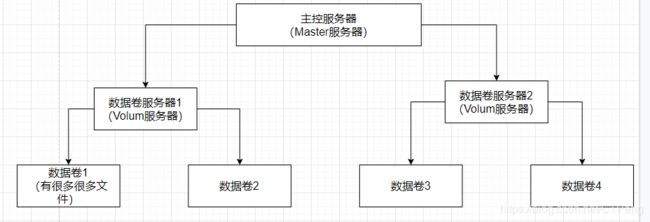
seaWeedFs的文件存储的基本结构如上,我们从下往上看
数据卷:也就是是类似我们windowspan的D,E盘等物理磁盘,文件保存的物理介质。默认32GB,通过修改代码可以修改为64GB或者128GB,每个文件的最大不超过单个卷的大小。
官网描述:In the current implementation, each volume can hold 32 gibibytes (32GiB or 8x2^32 bytes). This is because we align content to 8 bytes. We can easily increase this to 64GiB, or 128GiB, or more, by changing 2 lines of code, at the cost of some wasted padding space due to alignment.
There can be 4 gibibytes (4GiB or 2^32 bytes) of volumes. So the total system size is 8 x 4GiB x 4GiB which is 128 exbibytes (128EiB or 2^67 bytes).
Each individual file size is limited to the volume size.
数据卷服务器:为了更方便的管理数据卷,通过该服务来对多个数据卷进行管理。其中,数据卷服务器保存了文件元数据,通过访问文件元数据就可以操作数据卷中的文件。从官网中我们了解到文件的元数据只有16字节大小。【文件句柄:表示文件对象的一个便于使用的引用】
官网描述:The actual data is stored in volumes on storage nodes. One volume server can have multiple volumes, and can both support read and write access with basic authentication. 一个卷服务对应多个卷
The actual file metadata is stored in each volume on volume servers. Since each volume server only manages metadata of files on its own disk, with only 16 bytes for each file, all file access can read file metadata just from memory and only needs one disk operation to actually read file data.每个文件的元数据16字节大小,Linux中中XFS结构中为536/8(67)字节。
For comparison, consider that an xfs inode structure in Linux is 536 bytes
主控服务器:为了便于对多个数据卷服务器进行统一的调度(增加,删除,查找,定位等等操作),逻辑上抽象出一个主控服务器对整个DFS(分布式文件系统)进行统一管理。其中,主控服务器自然就管理着数据卷服务器的元数据信息(数据卷的元数据),相当于间接管理了文件信息。
官网描述:All volumes are managed by a master server. The master server contains the volume id to volume server mapping. This is fairly static information, and can be easily cached.
架构的好处:
*The actual data is stored in volumes on storage nodes. One volume server can have multiple volumes, and can both support read and write access with basic authentication.*实际数据保存在存储节点(数据卷)中,一个卷服务管理多个卷,同时支持带有基本认证功能的读写操作。提高读写访问的并发功能。
基本原理
具体的核心原理可参考facebook的一片文章《Finding a needle in Haystack: Facebook’s photo storage》
存储在磁盘中的文件,得以快速读写基础是,得益于Append-Only的数据存储方式,文件的上传操作只是在特定磁盘位置追加文件数据,类似与kafka的消息存储结构和Redis的AOF数据恢复方式使用的数据接口。
基本使用
基本环境搭建
master服务
./weed master
卷服务
> weed volume -dir="/tmp/data1" -max=5 -mserver="localhost:9333" -port=8080 &
> weed volume -dir="/tmp/data2" -max=10 -mserver="localhost:9333" -port=8081 &
By default, the master node runs on port 9333, and the volume nodes run on port 8080. Let’s start one master node, and two volume nodes on port 8080 and 8081. Ideally, they should be started from different machines. We’ll use localhost as an example.
SeaweedFS uses HTTP REST operations to read, write, and delete. The responses are in JSON or JSONP format.
SeaWeedFS提供了一个HTTTREST形式的接口,我们通过HTTP客户端就可以完成对文件的读写操作。
上传文件(Write File)
从master服务中获取文件将要存放的卷服务,以及文件的唯一标示信息,至于文件最后被保存在磁盘的哪里,由卷服务自行决定。
To upload a file: first, send a HTTP POST, PUT, or GET request to /dir/assign to get an fid and a volume server url:
> curl http://localhost:9333/dir/assign
{"count":1,"fid":"3,01637037d6","url":"127.0.0.1:8080","publicUrl":"localhost:8080"}
Second, to store the file content, send a HTTP multi-part POST request to url + ‘/’ + fid from the response:
> curl -F file=@/home/chris/myphoto.jpg http://127.0.0.1:8080/3,01637037d6
{"name":"myphoto.jpg","size":43234,"eTag":"1cc0118e"}
修改文件(Write File)
To update, send another POST request with updated file content.
修改文件和上传文件类似,同一个URL不同的是文件不同罢了!
删除文件(Write File)
For deletion, send an HTTP DELETE request to the same url + ‘/’ + fid URL:
删除文件和上传文件类似,访问对应的URL,采用DELETE Method即可
> curl -X DELETE http://127.0.0.1:8080/3,01637037d6
查看文件(Read File)
首先,找到对应的卷服务访问地址
First look up the volume server’s URLs by the file’s volumeId:
> curl http://localhost:9333/dir/lookup?volumeId=3
{"volumeId":"3","locations":[{"publicUrl":"localhost:8080","url":"localhost:8080"}]}
因为(通常)卷服务器不会太多,而且卷也不经常移动,所以在大多数时间缓存结果。根据复制类型,一个卷可以有多个副本位置。随便挑一个地方读。
第二步:现在可以获取公共url、呈现url或通过url直接从卷服务器读取:
Now you can take the public url, render the url or directly read from the volume server via url:
http://localhost:8080/3,01637037d6.jpg
Notice we add a file extension “.jpg” here. It’s optional and just one way for the client to specify the file content type.
写不写扩展名取决于自身的需求,可以参考官网
的描述信息。
文件ID含义解析:
"fid":"3,01637037d6"
开头的数字3表示卷id,卷id是一个无符号的32bit整数
逗号之后是一个文件密钥01,文件密钥是一个无符号的64bit整数;
随后是一个文件cookie 637037d6,是一个无符号的32bit整数,用于防止URL猜测。文件密钥和文件cookie都是十六进制编码的。
通过访问master服务获得了fid,根据需要可以将fid 301637037d6保存到不同的存储服务中(REDIS,MYSQL,TEXT等等)。可以按照自己的格式存储
如果作为字符串存储,理论上,您需要8+1+16+8=33个字节。一个char(33)就足够了,如果不够的话,因为大多数使用不需要2^32个卷。
如果真的需要空间,可以用自己的格式存储文件id。卷id需要一个4字节整数,文件密钥需要8字节长的数字,文件cookie需要一个4字节整数。所以16个字节就足够了。