利用爬虫将PDF的参考文献放在word中
py3.5+webdriver+beautifulsoup+正则表达式
最近实验室老是让我翻译论文,翻译的时候总觉得参考文献太麻烦:
1.PDF是分栏的,不想去做段落重排
2.格式啥的太烦
今天忽然就想用百度学术里面的“引用”来将PDF上面的参考文献写成标准的形式,然后直接copy去word里面
思路如下:
1.先把pdf参考文献直接copy到txt里,整个过程不需要花费超过五秒吧
2.从txt里用正则表达式匹配到论文名字,然后在百度学术里面搜索
3.点击引用(注意实际过程中可能会出现两个不一样的页面)
4.把引用内容爬下来放在另一个txt里
这个网络密集型可以用多线程实现,但是懒得搞了,后面再改吧,很简单
注意,使用webdriver必须要先搭配环境装一个exe 很简单 大家可以搜一下
最后效果如下:
pdf里面的:
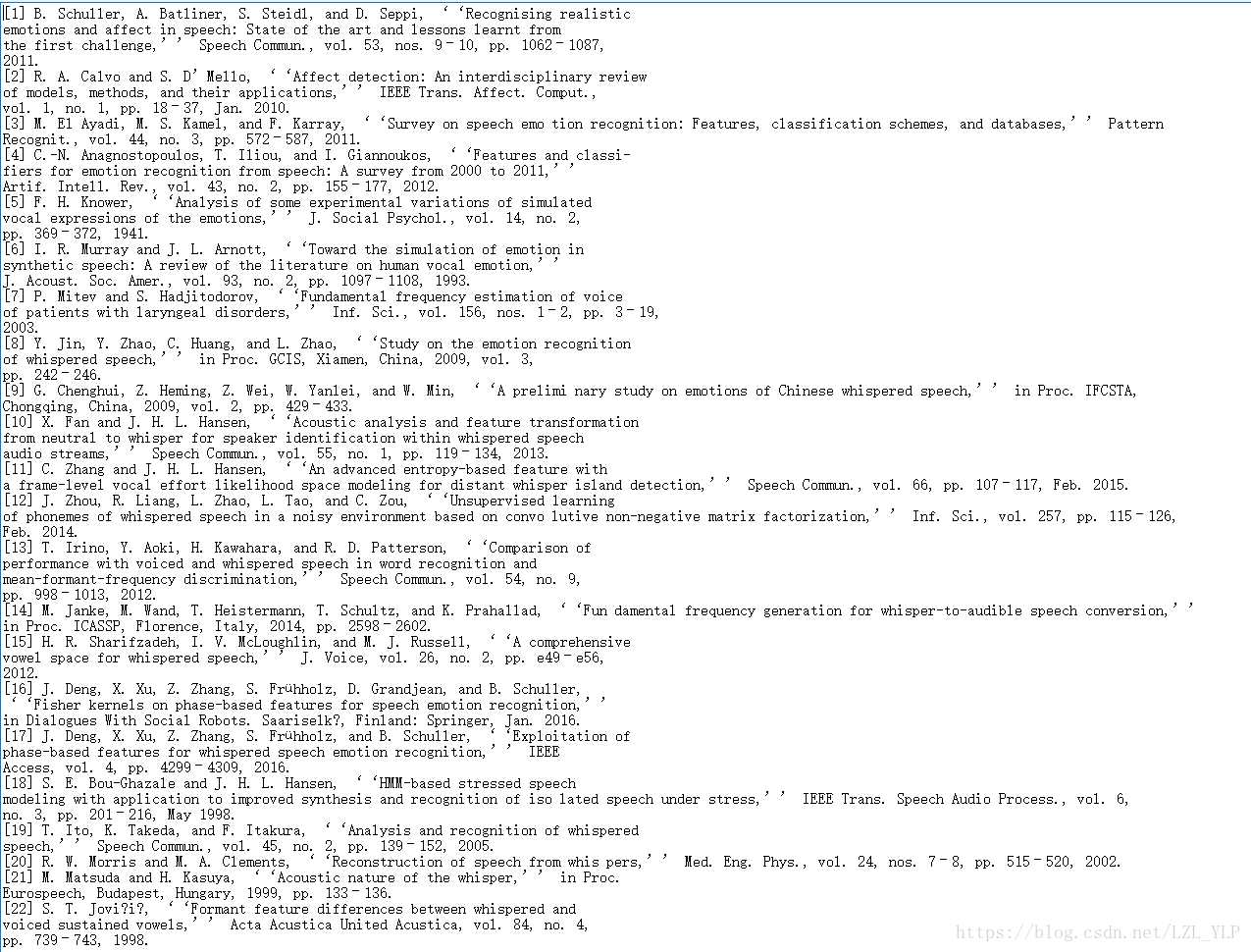
爬虫写下来的:

代码贴下:
import selenium.common.exceptions as sele_error
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import selenium
from selenium import webdriver
import urllib
import random
import time
import re
file= "./未找到的参考文献.txt" #记录没有爬取到的参考文献名字
file1= "./bbb.txt" #pdf里面的参考文献
file_to_w= "./real.txt" #写入的txt
url= "http://xueshu.baidu.com/"
'''
[32] A. Gretton, A. Smola, J. Huang, M. Schmittfull, K. Borgwardt, and
B. Schölkopf, ‘‘Covariate shift by kernel mean matching,’’ Dataset shift
Mach. Learn., vol. 3, no. 4, pp. 131–160, 2009.
'''
'''
'''
def get_name(string):
names= re.findall(",.*?‘‘(.*?)’’",string,re.S)
if len(names)== 0:
return ""
return names[-1].strip(",")
# a= get_name('''
# [32] A. Gretton, A. Smola, J. Huang, M. Schmittfull, K. Borgwardt, and
# B. Schölkopf, ‘‘Covariate shift by kernel mean matching,’’ Dataset shift
# Mach. Learn., vol. 3, no. 4, pp. 131–160, 2009.
# ''')
# print(a)
def get_real_name(driver,name_to_search):
# driver= webdriver.Firefox()
# driver.set_page_load_timeout(20)
try:
try:
input= driver.find_element_by_id("kw")
except sele_error.NoSuchElementException:
try:
driver.switch_to.default_content()
try:
input= driver.find_element_by_id("kw")
except sele_error.NoSuchElementException:
driver.back()
locator = [By.ID, "kw"]
WebDriverWait(driver, 60, 1).until(EC.presence_of_element_located(locator))
input= driver.find_element_by_id("kw")
except Exception as e:
with open(file,'a+') as f:
f.write("%s\n"%name_to_search)
input.click()
input.send_keys(name_to_search)
key= driver.find_element_by_id("su")
key.click()
time.sleep(random.randint(0,3))
'''
引用
'''
try:
locator= [By.CSS_SELECTOR,"a[class=\"sc_q c-icon-shape-hover\"]"]
WebDriverWait(driver,10,1).until(EC.presence_of_element_located(locator))
except:
locator = [By.CSS_SELECTOR, "a[class=\"sc_q\"]"]
WebDriverWait(driver, 10, 1).until(EC.presence_of_element_located(locator))
get_way = driver.find_elements_by_css_selector("a[class=\"sc_q\"]")[0]
get_way.click()
time.sleep(random.randint(0, 3))
locator = [By.CSS_SELECTOR, "div[class=\"sc_quote_list_item_r\"]"]
WebDriverWait(driver, 30, 1).until(EC.presence_of_element_located(locator))
soup = BeautifulSoup(driver.page_source)
driver.back()
div_ = str(soup.find_all(name="div", attrs={"class": "sc_quote_list_item_r"})[0])
return re.findall(">(.*?)
Quiñonero-Candela J, Sugiyama M, Schwaighofer A, et al. Covariate Shift by Kernel Mean Matching[C]// MIT Press, 2009:131-160.
'''
locator= [By.CSS_SELECTOR, "div[class=\"sc_quote_list_item_r\"]"]
WebDriverWait(driver, 30, 1).until(EC.presence_of_element_located(locator))
soup= BeautifulSoup(driver.page_source)
driver.back()
div_= str(soup.find_all(name="div",attrs={"class":"sc_quote_list_item_r"})[0])
return re.findall(">(.*?)