MySQL之表的内外连接、索引、事务、视图总结
表的内外连接
内连接
内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选。
eg:
select ename,dname
from emp,dept
where emp.deptno=dept.deptno
and ename=’smith’;

外连接
1. 左外连接:联合查询中,左侧的表完全显示
语法:select 字段
from 表名1 left join 表名2 on 连接条件
举例,建两个简单的表:
create table stu(
id int,
name varchar(20)
);
create table exam(
id int,
grade int
);
插入数据:
insert into stu values(1,’hello’),(2,’kitty’),(3,’test’),(4,’kate’);
insert into exam values(1,20),(2,60),(3,90),(10,100);
查询所有学生的成绩,如果这个学生没有成绩,也要讲学生的个人信息显示出来
select stu.id,name,grade
from stu left join exam
on stu.id = exam.id;

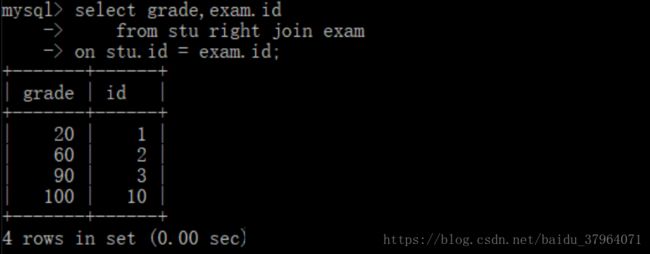
2. 右外连接:联合查询中,右侧的表完全显示
语法:
select 字段
from 表名1 right join 表名2 on 连接条件
举例:
select grade,exam.id
from stu right join exam
on stu.id=exam.id
索引
提高数据库的性能,查询速度的提高,是索引的一大优点。但是它是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以他它价值,在于提高一个海量数据的检索速度。
常见索引分为:主键索引(primary key),唯一索引(unique),普通索引(index),全文索引(fulltext)
索引的基本原理
那么,索引是通过什么机制使查询速度变得如此快呢?
其实加上索引时,会改变我们数据的结构,可能有人都猜出来是二叉树,举例如下图:
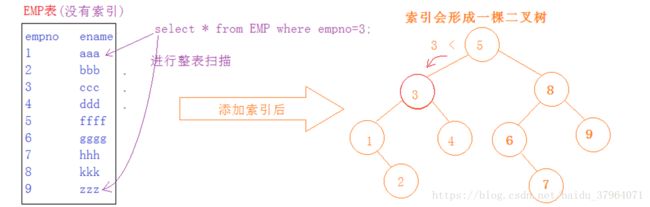
补充说明:
- 占用磁盘空间
- 当添加一条记录,除了添加到表中,还要维护二叉树,速度有影响,但不大。
- 当我们添加一个索引,不能够解决所有查询问题,需要分别给字段建立索引;
- 索引是以空间换时间
创建索引
1.创建主键索引
方式一:在创建表时,直接在字段名后指定primary key。
eg:create table 表名(id int primary key,name varchar(20));
方式二:在创建表的最后,指定某列或某几列为主键索引。
eg:create table 表名(id int, name varchar(20),primary key);
方式三:创建表以后再添加主键。
eg:create table 表名(id int, name varchar(20));
alter table 表名 add primary key(id);
主键索引的特点:
1. 一个表中,多有一个主键索引,可以使用复合主键
2. 主键索引的效率高(主键不可重复)
3. 创建主键索引的列,它的值不能为null,且不能重复
4. 主键索引的列基本上是int
2.创建唯一索引
方式一:在表定义时,在某列后直接指定unique唯一属性。
create table 表名(id int primary key, name varchar(20) unique);
方式二:创建表时,在表的后面指定某列或某几列为unique。
create table 表名(id int primary key, nam varchar(20), unique(name));
方式三:创建以后再添加唯一键。
create table 表名(id int primary key, name varchar(20));
alter table add unique(name);
唯一索引的特点:
1. 一个表中可以有多个唯一索引
2. 查询效率高。
3. 如果在某一列上建立一个唯一索引,必须保证这列不能有重复数据。
4. 如果一个唯一索引上指定not null,等价于主键索引
3.创建普通索引
方式一:在表的定义最后,指定某列为索引
create table 表名(id int primary key, name varchar(20), index(name));
方式二:创建表完以后指定某列为普通索引
create table 表名(id int primary key, name varchar(20));
alter table add index(name);
方式三:创建一个索引名为idx_name的索引
create table 表名(id int primary key, name varchar(20));
create index idx_name on 表名(name);
普通索引的特点:
1. 一个表中可以有多个普通索引
2. 如果某列需要创建索引,但是该列存在重复数据,此时只能创建普通索引
4.创建全文索引
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文
创建全文索引
- 建表:
create table articles(
id int not null primary key auto_increment,
title varchar(200),
body text,
FULLTEXT(title,body)
)engine=MyISAM;

- 添加数据
insert into articles (title,body)
values (‘MySQL Tutorial’,’DBMS stands for DataBase …’),
(‘Optimizing MySQL’,’In this tutorial we will show …’),
(‘MySQL vs. YourSQL’,’In the following database comparison …’), (‘MySQL Security’,’When configured properly, MySQL …’); - 查询有没有database数据
(1)如果使用如下查询方式,虽然查询出数据,但是没有使用到全文索引

(2)使用全文索引
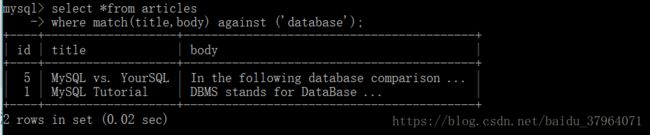
通过explain 来分析这个sql语句

4. 删除索引
方法一:删除主键
alter table 表名 drop primary;
方法二:其他索引的删除
alter table 表名 drop index 索引名;
方法三:
drop index 索引名 on 表名;
drop index empno on emp;

创建索引的原则
1、比较频繁查询的字段应该创建索引来提高查询效率
2、唯一性太差的字段不适合单独创建索引
3、更新非常频繁的字段不适合创建索引
4、字段根本不会出现在where字句中,该字段不应该创建索引
事务
事务就是一组dml语句组成,这些语句在逻辑上存在相关性,这一组dml语句具有原子性,要么全部成功,要么全部失败。MySQL提供一种机制,保证我们达到这样的效果。事务还规定不同的客户端看到的数据是不相同的。
我们具体使用一下:
1. 创建一个表account:

2. 开启事务:start transaction;

3. 设置保存点:savepoint aaa;
![]()
4. 插入数据等基本操作

5.如果需要,可以回到保存点

6. 继续对表进行操作

7. 设置保存点

8. 回到保存点

9. 提交事务:commit;
![]()
注意:
- 事务一旦提交,则不可以回退。若没设置保存点,则回退到最开始的时候。
- 如果一个事务被提交了,则不可以回退(commit)
- 可以选择回退到哪个保存点
- InnoDB支持事务,MyISAM不支持事务
- 开始事务可以使 start transaction 也可以是 set autocommit = 0;
事务的隔离级别
当MySQL表被多个线程或者客户端开启各自事务操作数据库中的数据时,MySQL提供了一种机制,可以让不同的事务在操作数据时,具有隔离性,从而保证数据的一致性。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| 读未提交 | 是 | 是 | 是 | 不加锁 |
| 读已提交 | 否 | 是 | 是 | 不加锁 |
| 可重复读 | 否 | 否 | 否 | 不加锁 |
| 可串行化 | 否 | 否 | 否 | 加锁 |
如何设置事务的隔离级别 ?
语法:set session transaction isolation level read uncommitted;
默认的是可重复读,自动避免了脏读、不可重复读、幻读。
| 隔离级别 | 解释 |
|---|---|
| 脏读 | 一个客户端(事务)会读取到另外一个客户端(事务)没有提交的修改数据 |
| 不可重复读 | 同一个查询在同一个事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生不可重复读。 |
| 幻读 | 同一个查询在同一个事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读 |
示例:
开启两个客户端:
![]()
其一插入数据:

另一个发生幻读:

事务的ACID特性
- 原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency):事务必须使数据库从一个一致性状态变到另外一个一致性状态。
- 隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据 所干扰,多个并发事务之间要相互隔离。
- 持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中的数据的修改就是永久性的,接下来即使数据库发生故障也 不应该对其有任何影响。
视图
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。视图的数据变化会影响到基表,基表的数据变化也会影响到视图。
创建视图
语法:
create view 视图名
as select语句
示例:
create view ename_dname_v
as
select ename,dname
from emp,dept
where emp.deptno = dept.deptno;
注意:
1. 修改了视图,对基表数据有影响
2. 修改了基表,对视图有影响
删除视图
语法:
drop view 视图名
视图和表的区别
- 表要占用磁盘空间,视图不需要
- 视图不能添加索引
- 使用视图可以简化查询
- 视图可以提高安全性