SQL的一些用法总结
1、select 语句
1、NULL表示 不可用、未赋值、不知道、不适用 , 它既不是0 也不是空格。
2、字符串连接操作符: “||”
3、DISTINCT 去除重复行。
4、比较操作符:<> 不等于
2、单行函数
1、大小写转换函数:
LOWER('SQL Course') sql course
UPPER('SQL Course') SQL COURSE
INITCAP('SQL course') Sql Course
2、字符串操作函数
CONCAT('Hello', 'World') HelloWorld 字符串合并
SUBSTR('HelloWorld',1,5) Hello 字符串截取
LENGTH('HelloWorld') 10 字符串长度
INSTR('HelloWorld', 'W') 6 返回字符串的位置
LPAD(salary,10,'*') *****24000 向左填充
RPAD(salary, 10, '*') 24000***** 向右填充
TRIM('H' FROM 'HelloWorld') elloWorld trim只能在首尾截取
TRIM(' HelloWorld') HelloWorld
TRIM('Hello World') Hello World
3、数字操作函数:
ROUND(45.926, 2) 45.93 数字截取小数点后几位,四舍五入
TRUNC(45.926, 2) 45.92 数字截取小数点后几位,无四舍五入
MOD(1600, 300) 100 取余
4、日期操作函数:
MONTHS_BETWEEN ('01-SEP-95','11-JAN-94') 19.6774194 ADD_MONTHS ('11-JAN-94',6) 11-Jul-94
NEXT_DAY ('01-SEP-95','FRIDAY') 8-Sep-95 下星期的星期五是哪天
NEXT_DAY ('01-SEP-95',1) 3-Sep-95
NEXT_DAY ('1995-09-01',1)
ORA01861:literal does not match format string
NEXT_DAY (to_date('1995-09-01','YYYY-MM-DD'),1) 3-Sep-95 LAST_DAY('01-FEB-95') 28-Feb-95 本月的最后一天
ROUND('25-JUL-95','MONTH') 1-Aug-95
月份按**1-15日和16-30日**四舍五入到最近的 几月1日
ROUND('25-JUL-95' ,'YEAR') 1-Jan-96
年份按**1-6月和7-12月**四舍五入到最近的 几几年1月
TRUNC('25-JUL-95' ,'MONTH') 1-Jul-95 当月的第一天
TRUNC('25-JUL-95','YEAR') 1-Jan-95 这一年的第一天
5 、TO_CHAR() 函数:
日期到字符串的转换:TO_CHAR(date, 'format_model')
YYYY 4位数字表示的年份
YEAR 英文描述的年份 MM 2位数字表示的月份
MONTH 英文描述的月份
MON 三个字母的英文描述月份简称
DD 2位数字表示的日期
DAY 英文描述的星期几
DY 三个字母的英文描述的星期几简称
HH24:MI:SS AM 时分秒的格式化
DDspth 英文描述的月中第几天
fm 格式化关键字,可选
数字到字符串的转换:TO_CHAR(number, 'format_model')
9 表示一个数字
0 强制显示0
$ 放一个美元占位符
L 使用浮点本地币种符号
. 显示一个小数点占位符
, 显示一个千分位占位符
6TO_NUMBER() 函数:
字符串到数字的转换: TO_NUMBER(char[, 'format_model'])
7 TO_DATE() 函数:
字符串到日期的转换: TO_DATE(char[, 'format_model'])
8、常用单行函数:
NVL (expr1, expr2) 如果expr1为空,这返回expr2
NVL2 (expr1, expr2, expr3) 如果expr1为空,这返回expr3(第2个结果)否则返回expr2
NULLIF (expr1, expr2) 如果expr1和expr2相等,则返回空
COALESCE (expr1, expr2, ..., exprn)
如果expr1不为空,则返回expr1,结束;否则计算expr2,直到找到 一个不为NULL的值 或者如果全部为NULL,也只能返回NULL 了
9、条件表达式:case when 和decode实现if-then-else逻辑
Case语句:
Case 字段名 when 条件表达式1 then 返回表达式1
when 条件表达式2 then 返回表达式2
else 返回表达式3
end
decode语句:
decode(字段名,匹配值1,返回值1,匹配值2,返回值2,…,默认值)
3、分组计算函数
分组计算函数(常用):
1、求和 (SUM)
2、求平均值(AVG)
3、计数(COUNT)
4、求标准差(STDDEV)
5、求方差(VARIANCE)
6、求最大值(MAX)
7、求最小值(MIN)
Group by后面的字段要加上select后面的字段,除了分组计算函数部分的字段。
Select [column,] group_function(column), ... from table [where condition] [group by column] [order by column];
红色部分的字段一般要一致
不能在Where 条件中使用分组计算函数表达式,当出现这样的需求的时候,使用Having 子句。
当分组函数遇到null时,只计算有值的部分。
1、count函数说明:
COUNT(*) : 返回满足选择条件的所有行的行数,包括值为空的行和重复的行
COUNT(expr): 返回满足选择条件的且表达式不为空行数。 COUNT(DISTINCT expr): 返回满足选择条件的且表达式不为空,且不重复的行数。
2、group by 子句增强
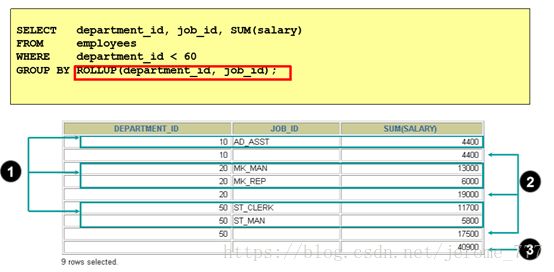
在Group By 中使用Rollup 产生常规分组汇总行 以及分组小计:
Rollup 后面跟了n个字段,就将进行n+1次分组,从右到左每次减少一个字段进行分组;然后进行 union
在Group By 中使用Cube 产生Rollup结果集 + 多维度的交叉表数据源:
常规分组行;2,3 、4 分层小计行;其中3是交叉表数据源需要的 job_id 维度层面的小计。 Cube 后面跟了n个字段,就将进行2的N次方的分组运算,然后进行;

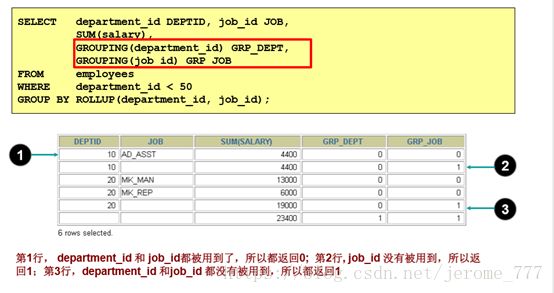
GROUPING函数:没有被Grouping到返回1,否则返回0
使用Grouping Set 来代替多次UNION:

4、子查询
1、单行比较必须对应单行子查询(返回单一结果值的查询); 比如= , > 。
2、多行比较必须对应多行子查询(返回一个数据集合的查询);比如IN , > ANY, > ALL 等。
3、子查询进阶:
- 非相关子查询当作一张表来用;
- 子查询中参考了外部主查询中的表
- 使用Exists操作
- 使用 Not Exists操作
- 在Update 语句中使用相关子查询。
Update 表名 set 字段名=(select…)
- 在DELETE 语句中使用相关子查询
Delete from 表名 where 字段名 = (select…)
- 使用WITH子句
With
名字 as (select 语句)
后面可以用这个名字来代替这个select语句。
5、递归查询
递归查询: 使用语句SQL语句即可把整个递归树全部查询出来
SELECT [LEVEL], column, expr...
FROM table
[WHERE condition(s)]
[START WITH condition(s)]
[CONNECT BY PRIOR condition(s)] ;
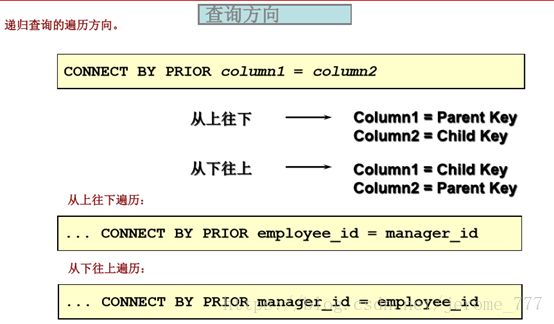
使用LEVEL关键字和 LPAD函数 ,在OUTPUT中显示树形层次。
6、DML语句
1、从另一个表中 Copy 一行 语法:
INSERT INTO table [ column (, column) ] subquery;
注意:在这种方式下,不要使用VALUES 关键字
MERGE 语句: 比较整合语句, 语法:
对两张表进行比较整合
MERGE INTO table_name table_alias
USING (table|view|sub_query) alias
ON (join condition)
WHEN MATCHED THEN
UPDATE SET
col1 = col_val1,col2 = col2_val
WHEN NOT MATCHED THEN
INSERT (column_list) VALUES (column_values);
2、insert增强
一个来源插入多个表:
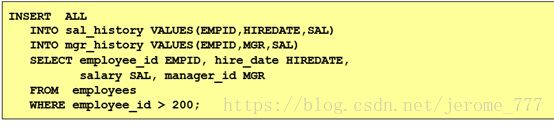
一个来源插入多个目标表(有条件,首次匹配即跳到下一条)

列转行(一行变多行,交叉报表的反操作)。

7、数据库对象-表
| 数据类型 |
描述 |
| VARCHAR2(size) |
可变长字符串 |
| CHAR(size) |
定长字符串 |
| NUMBER(p,s) |
可变长数值 |
| DATE |
日期时间 |
| LONG |
可变长大字符串,最大可到2G |
| CLOB |
可变长大字符串数据,最大可到4G |
| RAW and LONG RAW |
二进制数据 |
| BLOB |
大二进制数据,最大可到4G |
| BFILE |
存储于外部文件的二进制数据,最大可到4G |
| ROWID |
64进制18位长度的数据,用以标识行的地址 |
| TIMESTAMP |
精确到分秒级的日期类型(9i以后提供的增强数据类型) |
| INTERVAL YEAR TO MONTH |
表示几年几个月的间隔(9i以后提供的增强数据类型-极其少见) |
| INTERVAL DAY TO SECOND |
表示几天几小时几分几秒的间隔(9i以后提供的增强数据类型-极其 少见) |
复制表:
CREATE TABLEA as select * from tableb
如果只想保留表结构,但不想要数据,可以:
CREATE TABLEA as select * from tableb where 1=2
更改表的语法:
添加列:
ALTER TABLE table
ADD (column datatype [DEFAULT expr] [, column datatype]...);
更改列:
ALTER TABLE table
MODIFY (column datatype [DEFAULT expr] [, column datatype]...);
删除列:
ALTER TABLE table
DROP (column);
8、数据库对象-约束
常用的约束有如下几种:
NOT NULL (非空约束)
UNIQUE (唯一性约束)
PRIMARY KEY (主键约束)
FOREIGN KEY (外键约束)
CHECK (自定义约束)
- 单独创建约束语法:
ALTER TABLE tablename ADD CONSTRAINT constraintname constrainttype (column1,…);
2、外键约束类型:
• REFERENCES: 表示列中的值必须在父表中存在
• ON DELETE CASCADE: 当父表记录删除的时候自动删除子表中的相应记录.
• ON DELETE SET NULL: 当父表记录删除的时候自动把子表中相应记录的值设为NULL
9、数据库对象-序列、索引、同义词
1、序列的创建:
CREATE SEQUENCE sequence
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}]
[{CACHE n | NOCACHE}];
从序列取值: CURRVAL 取当前值, NEXTVAL取下一个值
- 索引
Create index 索引名 on 表名(字段名)
函数索引:
当查询语句的Where条件中,对于某些列使用了函数表达式时,普通索引对查询没有帮助,如果想利用索引,则 必须创建函数索引,比如在下面的例子中,
SELECT * FROM departments WHERE UPPER(department_name) = 'SALES';
CREATE INDEX upper_dept_name_idx
ON departments(UPPER(department_name));
10、集合操作
UNION: 去除重复记录。
UNION ALL : 保留重复记录
INTERSECT : 取交集
MINUS : 取差集
- SQL进阶
1、分析函数提供一系列比较高级的SQL功能。分析函数时建立在数据窗口(over在一定的数据库范 围进行数据分析),在一定的数据范围进行排序、汇总等。


2、全局临时表:

3、物化视图
