Python基础知识点:多进程的应用讲解
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:东哥IT笔记
现在很多CPU都支持多核,甚至是手机都已经开始支持多核了。而Python的GIL(Global Interpreter Locko)则使得其没法使用这些多核带来的优势。还好从Python2.6开始,引入了multiprocessing模块,我们终于可以使用多核带来的便利了。
本文,你会学习到下面这些内容:
- 使用多进程的优点
- 使用多进程的缺点
- 使用multiprocessing来创建多进程
- Process的子类化
- 创建进程池
本文并不是一个multiprocessing的全面的介绍,假如你想全面的了解它,可以参见官方的文档:
https://docs.python.org/2/library/multiprocessing.html下面让我们开始吧!
使用多进程的优点
使用多进程有很多优点:
- 多进程使用独立的内存空间
- 相比于线程,代码更加直观
- 能够使用多个CPU/多核
- 避免GIL
- 子进程可以被kill(和thread不同)
- multiprocessing有和threading.Thread类似的接口
- 对CPU绑定的进程比较好(加密,二进制搜索,矩阵乘法等)
下面我们来看看使用多进程有什么缺点:
使用多进程的缺点
使用多进程也有一些缺点:
- 进程间通信更加复杂
- 内存的占用大于线程
使用multiprocessing来创建进程
multiprocessing是用来模拟threading.Thread类工作的。下面就是一个使用它的例子:
import multiprocessing
import random
import time
def worker(name: str) -> None:
print(f'Started worker {name}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} worker finished in {worker_time} seconds')
if __name__ == '__main__':
processes = []
for i in range(5):
process = multiprocessing.Process(target=worker,
args=(f'computer_{i}',))
processes.append(process)
process.start()
for proc in processes:
proc.join()首先第一步需要import multiprocessing模块,另外两个import分别是为random和time服务的。
worker函数就是用来假装做一些事情,传入一个name的参数,没有什么返回,他首先打印name的值,然后随机sleep一段时间用来模拟做一段很长时间的工作,最后打印work finish。
紧接着,你使用multiprocessing.Process创建了5个进程,他的使用和threading.Tread()比较类似,你告诉Process哪个目标函数需要调用,以及会传入什么参数给他们,然后你调用了start函数来启动进程。另外你会把这些进程加入到一个list中。
最后,你遍历这个list,调用join方法,这个方法其实就是告诉Python等到进程结束。
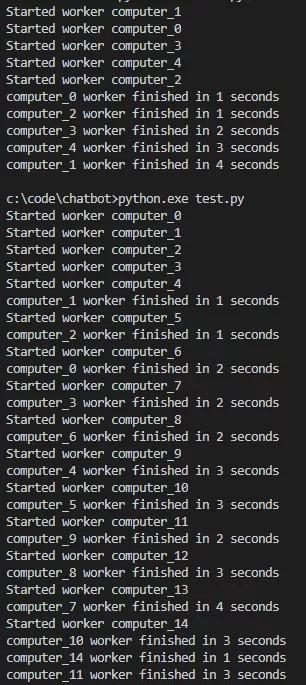
假如你run这个函数,你会看到类似下面这样的输出:
其实你每次运行这个函数,结果都会有稍许的不同,主要还是因为你调用了random函数,你可以试试,看看你自己的输出。
Process的子类化
multiporcessing模块中的Process类是可以子类化的,他和threading.thread的类差不多。我们来看下面代码:
# worker_thread_subclass.py
import random
import multiprocessing
import time
class WorkerProcess(multiprocessing.Process):
def __init__(self, name):
multiprocessing.Process.__init__(self)
self.name = name
def run(self):
"""
Run the thread
"""
worker(self.name)
def worker(name: str) -> None:
print(f'Started worker {name}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} worker finished in {worker_time} seconds')
if __name__ == '__main__':
processes = []
for i in range(5):
process = WorkerProcess(name=f'computer_{i}')
processes.append(process)
process.start()
for process in processes:
process.join()这里,我们写了一个multiprocess.Process()的子类,并且重写了run()方法。
其他方面和上面的例子其实是类似的,现在我们可以来看看具体的输出,和上面的也类似。

创建一个进程池
假如你有很多进程需要运行,有时你希望能够限制进程运行的数目。比如说,你需要运行20个进程,但是你只有4个核,那么你可以使用multiprocessing模块来创建一个进程池,用它来限制每次进程运行的数目到4个。
下面是示例的代码:
import random
import time
from multiprocessing import Pool
def worker(name: str) -> None:
print(f'Started worker {name}')
worker_time = random.choice(range(1, 5))
time.sleep(worker_time)
print(f'{name} worker finished in {worker_time} seconds')
if __name__ == '__main__':
process_names = [f'computer_{i}' for i in range(15)]
pool = Pool(processes=5)
pool.map(worker, process_names)
pool.terminate()这个例子中,worker函数还是一样的,主要是后面的代码, 我们创建了一个进程池,它的数目是5,也就意味着最大的运行数目是5。使用这个pool,你需要调用map()方法,然后把你需要的调用的方法和参数传递给他。
这样的话,Python每次只会使用5个进程来运行直到结束。最后你需要调用terminate()函数,否则你会发现下面的错误:
/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/multiprocessing/resource_tracker.py:216:
UserWarning: resource_tracker: There appear to be 6 leaked semaphore objects to clean up at shutdown
这个代码的具体输出如下所示: