一次频繁Full GC的排查过程
问题描述
最近公司的线上监控系统给我推送了一些kafka lag持续增长的消息,我上生产环境去看了相应的consumer的情况,发现几台机器虽然还在处理消息,但是速度明显慢了很多。
问题猜测与验证
我猜测是JVM频繁做Full GC,导致进程也跟着频繁卡顿,处理消息的速度自然就慢了。为了验证这个想法,先用jstat看看内存使用情况:
jstat -gcutil 1 1000 #1是进程号
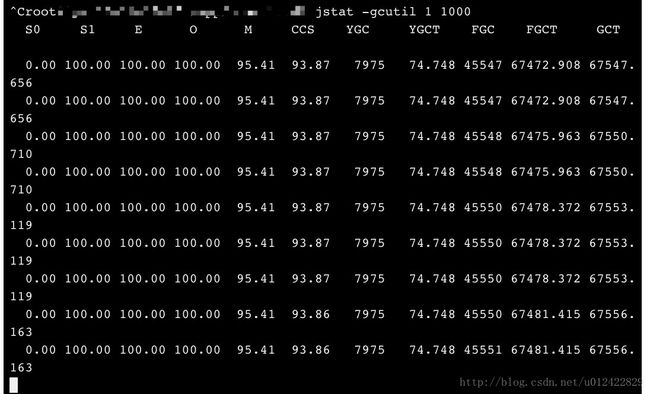
结果如我所料,几乎1秒钟就要做一次FGC,能安安静静的做个正常的consumer才有鬼了。
赶紧留了一台consumer拿来做分析,把别的几台consumer都重启。不管怎样,先恢复消费能力再说!
内存泄露root cause排查
1秒一次FGC,那肯定是发生内存泄露了。
二话不说,把堆dump下来先!
jmap -F -dump:format=b,file=heapDump 1 #1是进程号
生成的heapDump文件有将近2个G的大小,这么大个文件,为了不影响生产环境的机器,还是scp到本地进行分析吧!
jhat了一下,直接卡在那里不动了。没办法,祭出VisualVM来帮忙。导入文件之后,发现有一大堆HashMap的Node在那占着:
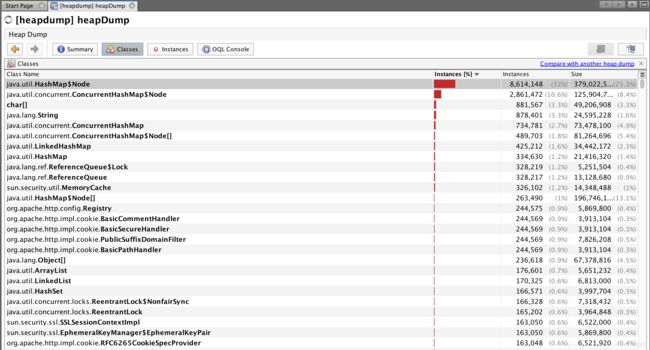
然而并不知道这是个啥,点进去看看内容,发现有一大堆node的key类型是X509CertImpl:
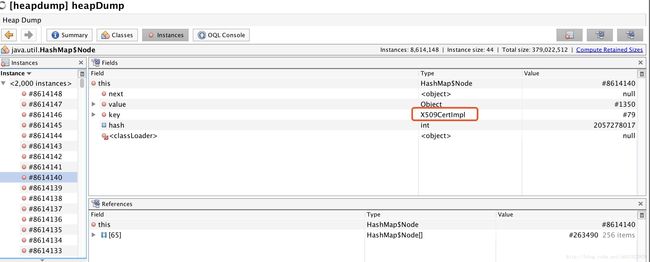
这时候我意识到,问题可能出在网络连接上面。但是还是没法定位到具体的代码。
没办法,接着向上找线索。不断地通过OQL查询Referrers:
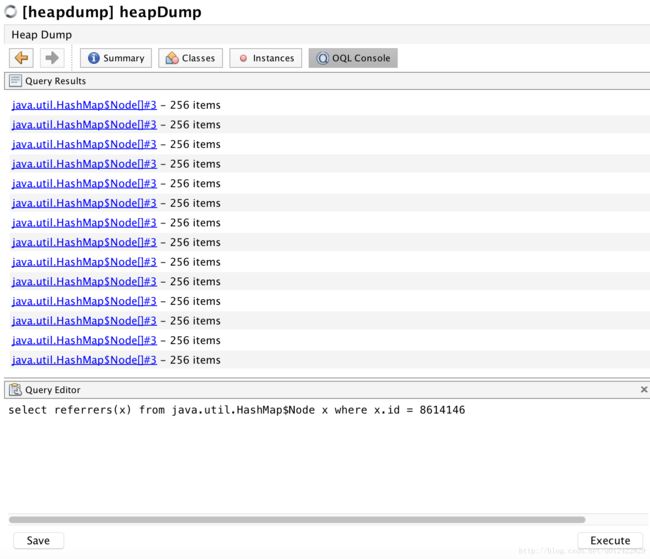
接着查询:
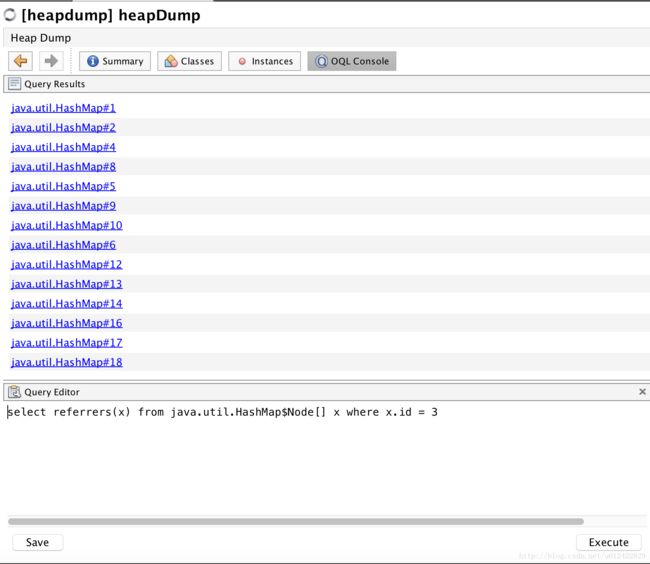
接着查询:
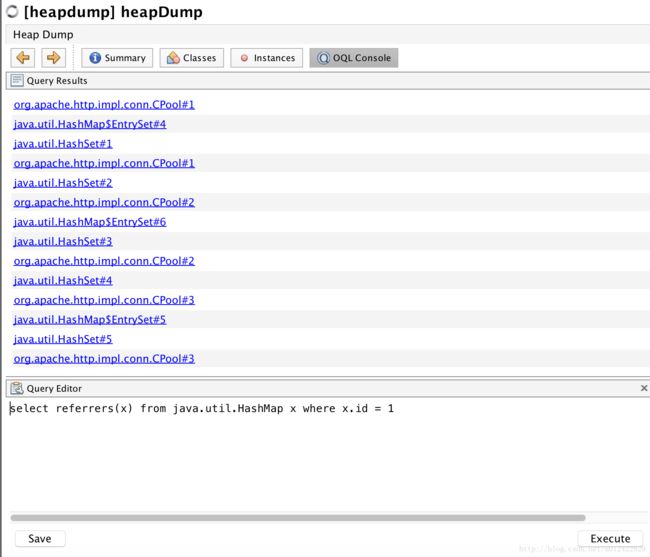
这时候看到了连接池的踪迹,感觉离真相不远了!
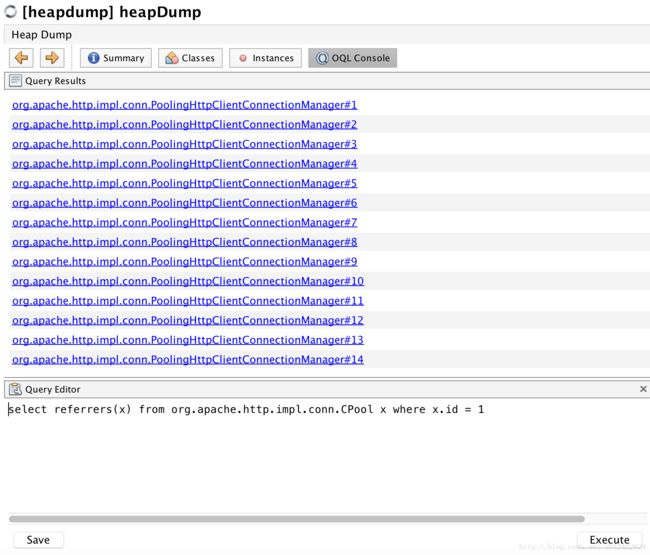
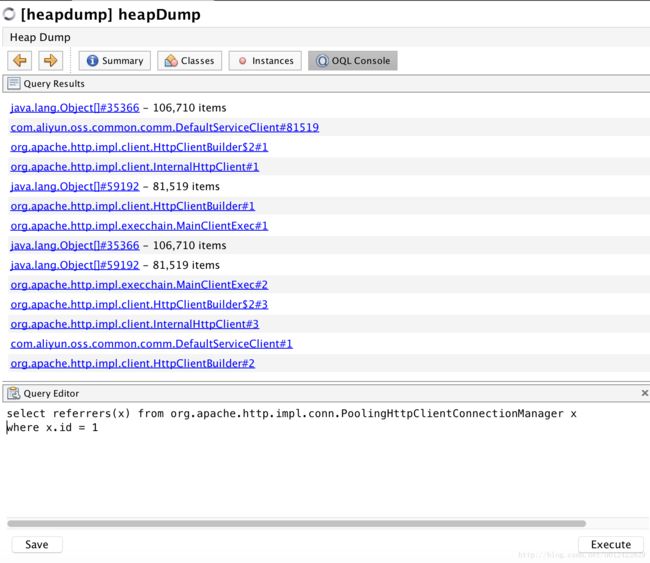
到了这里,我心里大概知道了答案:问题一定出在阿里云OSS身上。再结合这张图:
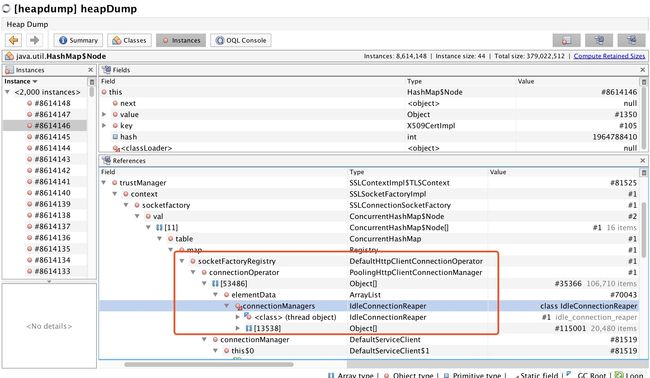
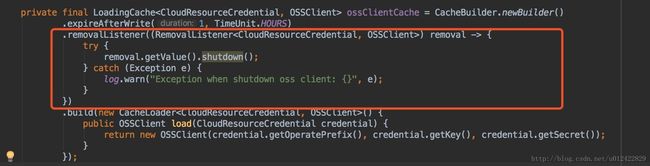
就可以猜出是因为使用了OSS的客户端,但是没有正确的释放资源,导致client被回收时,它所创建的资源因为还有别的referrer, 却没有被回收。
再去oss github上的sample一看,果然有这么一段:
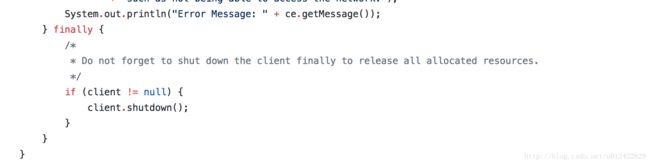
而这个shutdown方法做的正是释放Idle资源的事儿:
public void shutdown() {
IdleConnectionReaper.removeConnectionManager(this.connectionManager);
this.connectionManager.shutdown();
}问题修复
知道了原因,修复也是很轻松的事儿。 在创建client的缓存里加个removeListener,用来主动调用client.shutdown(), 美滋滋: