软件下载
docker pull wurstmeister/zookeeper
docker pull wurstmeister/kafka
zookeeper伪集群安装
- 这里演示使用,只部署单节点。如需高可用,则最好部署多台zk节点
- 默认容器内配置文件在/conf/zoo.cfg,数据和日志目录默认在/data 和 /datalog,需要的话可以将上述目录映射到宿主机的可靠文件目录下
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper
kafka集群安装
- 使用docker命令可快速在同一台机器搭建多个kafka,只需要改变端口即可
- 节点1
# 此处zk地址不能使用127.0.0.1或者localhost 如果IP变了之后需要重新生成容器
# 端口 2181 即zk地址
docker run -d --name kafka1 -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=172.31.15.175:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.31.15.175:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
docker run -d --name kafka2 -p 9093:9093 -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=172.31.15.175:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.31.15.175:9093 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 -t wurstmeister/kafka
docker run -d --name kafka3 -p 9094:9094 -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=172.31.15.175:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.31.15.175:9094 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9094 -t wurstmeister/kafka
- 最终kafka集群搭建完成,对应端口为 9092、9093、9094 通过命令docker ps

kafka-manager安装
# 根据自己需要 确认是否增加restart参数 由于本人公司和家里IP不同,所以没加此参数
# --restart=always 在容器退出时总是重启容器
docker run -itd --name=kafka-manager -p 9000:9000 -e ZK_HOSTS="172.31.15.175:2181" sheepkiller/kafka-manager
topic创建
- 访问 localhost:9000
- 创建集群界面
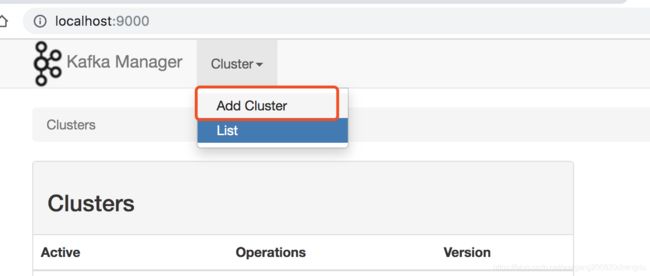
如下图所示 其他默认值即可

- topic创建界面
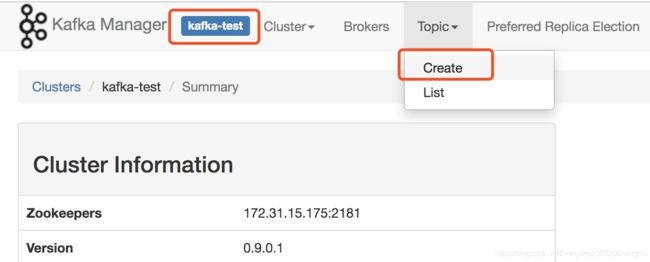
只需填写topic名字即可

topic列表

应用测试topic是否可用
4.0.0
com.zbj.kafka
kafka-demo
1.0-SNAPSHOT
org.apache.kafka
kafka_2.12
2.3.0
com.google.guava
guava
21.0
package com.zbj.kafka;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* KafkaProducer
*
* @author weigang
* @create 2019-09-16
**/
public class KafkaProducer {
private final Producer producer;
public final static String TOPIC = "kafka-1";
private KafkaProducer() {
Properties properties = new Properties();
// kafka端口
properties.put("bootstrap.servers", "172.31.15.175:9092,172.31.15.175:9093,172.31.15.175:9094");
// 配置value的序列化类
//properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", StringSerializer.class.getName());
// 配置key的序列化
properties.put("key.serializer", StringSerializer.class.getName());
//request.required.acks
//0, which means that the producer never waits for an acknowledgement from the broker (the same behavior as 0.7). This option provides the lowest latency but the weakest durability guarantees (some data will be lost when a server fails).
//1, which means that the producer gets an acknowledgement after the leader replica has received the data. This option provides better durability as the client waits until the server acknowledges the request as successful (only messages that were written to the now-dead leader but not yet replicated will be lost).
//-1, which means that the producer gets an acknowledgement after all in-sync replicas have received the data. This option provides the best durability, we guarantee that no messages will be lost as long as at least one in sync replica remains.
properties.put("request.required.acks", "-1");
producer = new org.apache.kafka.clients.producer.KafkaProducer<>(properties);
}
void producer() {
int messageNo = 1000;
final int COUNT = 100000;
while (messageNo < COUNT) {
String key = String.valueOf(messageNo);
String data = "hello kafka message " + key;
producer.send(new ProducerRecord<>(TOPIC, key, data));
System.out.println(data);
messageNo ++;
}
}
public static void main(String[] args) {
new KafkaProducer().producer();
}
}
package com.zbj.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
/**
* KafkaConsumer
*
* @author weigang
* @create 2019-09-16
**/
public class KafkaConsumer {
private final org.apache.kafka.clients.consumer.KafkaConsumer consumer;
private KafkaConsumer() {
Properties props = new Properties();
props.put("bootstrap.servers", "172.31.15.175:9092");
props.put("group.id", "zbj-group");
props.put("max.poll.records", 100);
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
//props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new org.apache.kafka.clients.consumer.KafkaConsumer(props);
}
void consume() {
consumer.subscribe(Arrays.asList(KafkaProducer.TOPIC));
final int minBatchSize = 200;
List> buffer = new ArrayList<>();
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
// 入库操作
//insertIntoDb(buffer);
for (ConsumerRecord record : buffer) {
System.out.println(record.key() + "-> " + record.value());
}
consumer.commitSync();
buffer.clear();
}
}
}
public static void main(String[] args) {
new KafkaConsumer().consume();
}
}
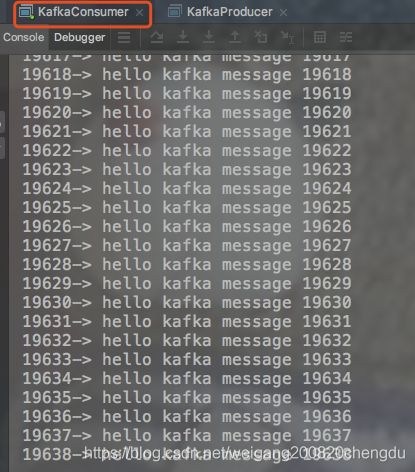
- 先启动消费者 在启动生成者
- 出现如下图 即成功
参考文章
- Mac 使用 docker 搭建 kafka 集群 + Zookeeper + kafka-manager
- kafka官网