非局部均值滤波和用于高光谱分类的新颖度量方式的NLM
文章目录
- 1 均值和非局部均值滤波
- 2 论文【使用新的相似性度量方法做非局部均值滤波】
- 2.1 类相似性度量
- 2.2 参数估计算法
- 2.3 根据非局部上下文信息分类
paper: Hyperspectral Image Classification Based on Nonlocal Means With a Novel Class-Relativity Measurement
均值与非局部均值滤波的思想与普通网络和attention网络的思想我认为是一致的,非常像,对我来说认为两者思想一样是一个聚合总结的过程,也许等我了解的更多,我会经历一个发散找到两者不同的过程。
1 均值和非局部均值滤波
均值滤波器利用滑窗的方式以滑窗的均值代替中心像素的值,进行滤波。缺点:
- 当方框的半径越大,得到的图像中那些变化较大的地方(边缘)计算后变化就越小,即边缘不明显,即模糊;
- 而且像素之间的相似性并不局限于一个很小的块,像是长边缘,或者结构纹理就可能再很远的地方仍然存在相似性。
非局部均值滤波器是图像去噪一种很好的方法,基本原理与均值滤波类似,都是要取平均值,但是非局部均值滤波在计算中加入了每一个点的权重值,所以能够保证在相邻且相差很大的点在方框中求平均值时相互之间的影响减小,也就对图像边缘细节部分保留很多,这样图像看起来会更清晰。
- 首先在一个点A周围取一个大的框(搜索框),设边长为s,A在方框的中心,然后再在方框中取小的方框,即相似框,设边长为d
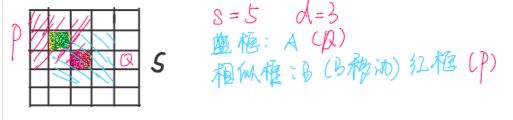
如图所示,红色的点为中心点A,整个 5 × 5 5\times 5 5×5的矩形为中心点A的搜索框,即 s = 5 s=5 s=5,方框中取小的相似框边长为3,即 d = 3 d=3 d=3,这时中心点A对应的相似框为蓝色部分 3 × 3 3\times 3 3×3的区域Q,以绿色点为中心的相似框为红斜线部分P,计算P与Q的差值,并加入高斯核计算得到的加权值 - 在搜索框内找到所有边长为d 的小方框,即红色斜线框P在搜索框内移动,记录中心点的坐标,记录所有相似框与Q相减,并且加入高斯核计算得到的加权值,这样可以得到一个二维数组,里面存放着各个点的差值乘以权重后的值,加入高斯核主要是因为距离中心点距离不同对中心点的影响大小也不同,离中心点越近,权重值越大一些而且高斯核的权重和是1,所以就不用再归一化了。

加入高斯核后,由下图可以看到距离中心点越近权重越大。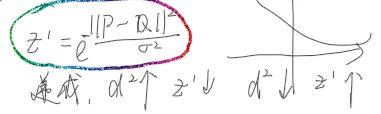
- 然后将这个二维数组求和,得到的值就是这个相似框的中心点B对于A的权重值。计算出A周围所有点的权重值,其实这个时候这个值和权重是成反比的,以A本身为例(以A为中心点的相似框),计算出来A对于A的所谓权重值是零。然后根据计算出来的值用一个指数减函数就得到了成正比的权重关系,具体的函数见下面的代码,w=exp(-d/h),就是这个,其中d就是计算出来的值啦,代入后w就是成正比的权重关系啦,h是一个滤波百分比值,可以先固定为一个常数, 而且这个计算出来w就是一个自动归一化的(0,1)的值。
- 然后就是根据得到的权重值【需要将所有的权重值规范化,使其和为1】以及各个点本身的灰度值计算出非局部均值滤波后A点的灰度值。
- 以此类推,可以计算出图中所有点经过非局部均值滤波后的值
优点:
可以既去除噪声,又保留图像边缘细节 ;当然去噪声指的一般是高斯白噪声,因为高斯白噪声的均值是0,所以求和取平均会比较有效果
缺点:
效率比较低
2 论文【使用新的相似性度量方法做非局部均值滤波】
我们看到前面的非局部均值滤波求解相似块的相似性的时候使用高斯核进行计算,这篇文章利用KL散度设计了一种新颖的相似性度量方法。
X = { x 1 , … , x n } ∈ R B × n X=\left\{x_{1}, \ldots, x_{n}\right\} \in R^{B \times n} X={x1,…,xn}∈RB×n 表示 n n n个像素B维特征的高光谱图像
Ω ≡ { 1 , … , K } \Omega \equiv\{1, \ldots, K\} Ω≡{1,…,K} K个标签的集合
Y = { y 1 , … , y n } ∈ Ω n Y=\left\{y_{1}, \ldots, y_{n}\right\} \in \Omega^{n} Y={y1,…,yn}∈Ωn HIC(高光谱图像分类)的最终目的是将标签划分到标签集合 Ω \Omega Ω
本文,首先将高光谱图像投影到主成分分析的空间,获得一幅多维图像P。选择该图像的前 d d d维 P f = P 1 , P 2 , … , P d P_f = P_{1}, P_{2}, \ldots, P_{d} Pf=P1,P2,…,Pd, P = P f + P r P= P_f+P_r P=Pf+Pr, P r P_r Pr表示剩余由噪声控制的图像,因为它们是综合的、压缩的、降噪的表示,并且与原始图像X中的每个像素相关联。该图像的剩余维度主要是噪声。
多项逻辑回归数学和统计基础稳固,能够很好的解决由光谱特性给HIS带来的不适定分类问题,利用 P f P_f Pf在像素点 i i i的PCA特征向量,得到像素点 i i i的类别后验为 p ( y i ∣ P f i ) p\left(y_{i} | P_{f}^{i}\right) p(yi∣Pfi): p ( y i = k ∣ P f i , ω ) ≡ exp ( ω ( k ) h ( x i ) ) ∑ k = 1 K exp ( ω ( k ) h ( x i ) ) p\left(y_{i}=k | P_{f}^{i}, \boldsymbol{\omega}\right) \equiv \frac{\exp \left(\boldsymbol{\omega}^{(k)} \mathbf{h}\left(\mathbf{x}_{i}\right)\right)}{\sum_{k=1}^{K} \exp \left(\boldsymbol{\omega}^{(k)} \mathbf{h}\left(\mathbf{x}_{i}\right)\right)} p(yi=k∣Pfi,ω)≡∑k=1Kexp(ω(k)h(xi))exp(ω(k)h(xi))其中 h ( x ) ≡ [ h 1 ( x ) , … , h m ( x ) ] T \mathbf{h}(\mathbf{x}) \equiv\left[h_{1}(x), \ldots, h_{m}(x)\right]^{T} h(x)≡[h1(x),…,hm(x)]T指输入的 m m m个固定函数,通常指特征, ω ( x ) ≡ [ ω 1 ( 1 ) T , … , ω 1 ( K ) T ] T \omega(\mathbf{x}) \equiv\left[\omega_{1}(1)^{T}, \ldots, \omega_{1}(K)^{T}\right]^{T} ω(x)≡[ω1(1)T,…,ω1(K)T]T表示逻辑回归器。RBF核用于提高转换空间的可分性, K ( x , z ) = exp ( − ∥ x − z ∥ 2 / ( 2 ρ 2 ) ) K(\mathbf{x}, \mathbf{z})=\exp \left(-\|\mathbf{x}-\mathbf{z}\|^{2} /\left(2 \rho^{2}\right)\right) K(x,z)=exp(−∥x−z∥2/(2ρ2)),因此特征可以表示为 h ( x i ) ≡ [ 1 , K ( P f i , P f 1 ) … , K ( P f i , P f L ) ] T \mathbf{h}\left(\mathbf{x}_{i}\right) \equiv\left[1, K\left(P_{f}^{i}, P_{f}^{1}\right) \ldots, K\left(P_{f}^{i}, P_{f}^{L}\right)\right]^{T} h(xi)≡[1,K(Pfi,Pf1)…,K(Pfi,PfL)]T【L表示训练样本的个数】。同时,逻辑回归器 ω ^ \hat{\omega} ω^参数通过变量分裂和增广拉格朗日(LORSAL)算法学习得到【参数学习用一些优化方法学习得到。】。
2.1 类相似性度量
欧式距离是测量两个样本相似性最重要最广泛的方法,实践中,为了减小噪声影响并扩充样本容量,使用以 x i x_i xi和 x j x_j xj为中心的正方形框 N i N_{i} Ni和 N j N_{j} Nj的相似性代替两个样本的相似性,即第一部分介绍的非局部滤波。相似性度量公式变为: R i , j = exp ( − ∥ I N i − I N j ∥ 2 σ 2 ) R_{i,j}=\exp \left(-\frac{\left\|I_{N_{i}}-I_{N_{j}}\right\|^{2}}{\sigma^{2}}\right) Ri,j=exp(−σ2∥∥INi−INj∥∥2)其中 I N i I_{N_{i}} INi和 I N j I_{N_{j}} INj表示以以 x i x_i xi和 x j x_j xj为中心的图像块, R i R_{i} Ri表示两个像素的相似性。
在传统的非局部均匀滤波算法中,权重是基于欧式距离计算的,实际上,测度应该是根据任务决定的,因此本文用于高光谱图像分类的一个直观改变时使用任务依赖距离代替计算权值时的欧式距离。文章假设非局部相似块有相似的类别结构,根据KL散度提出一种类相似性测量方法。
为了简便,令 p ( y i ∣ ω ^ ) ≡ p ( y i ∣ P f i , ω ^ ) ≡ [ p ( y i = 1 ∣ ω ^ ) , … , p ( y i = K ∣ ω ^ ) ] T p\left(y_{i} | \hat{\boldsymbol{\omega}}\right) \equiv p\left(y_{i} | P_{f}^{i}, \hat{\omega}\right) \equiv \left[p\left(y_{i}=1 | \hat{\boldsymbol{\omega}}\right), \ldots, p\left(y_{i}=K | \hat{\omega}\right)\right]^{T} p(yi∣ω^)≡p(yi∣Pfi,ω^)≡[p(yi=1∣ω^),…,p(yi=K∣ω^)]T, p ( y i ∣ ω ^ ) p\left(y_{i} | \hat{\boldsymbol{\omega}}\right) p(yi∣ω^)和 p ( y j ∣ ω ^ ) p\left(y_{j} | \hat{\boldsymbol{\omega}}\right) p(yj∣ω^)表示两个样本 i i i和 j j j的后验概率向量, k ∈ Ω k \in \Omega k∈Ω, x i x_i xi到 x j x_j xj的距离表示为: d i , j = ∑ k = 1 K p ( y i = k ∣ ω ^ ) log ( p ( y i = k ∣ ω ^ ) p ( y j = k ∣ ω ^ ) ) d_{i, j}=\sum_{k=1}^{K} p\left(y_{i}=k | \widehat{\boldsymbol{\omega}}\right) \log \left(\frac{p\left(y_{i}=k | \widehat{\boldsymbol{\omega}}\right)}{p\left(y_{j}=k | \widehat{\boldsymbol{\omega}}\right)}\right) di,j=k=1∑Kp(yi=k∣ω )log(p(yj=k∣ω )p(yi=k∣ω )) ∑ k = 1 K p ( y i = k ∣ ω ^ ) = 1 \sum_{k=1}^{K} p\left(y_{i}=k | \widehat{\boldsymbol{\omega}}\right)=1 k=1∑Kp(yi=k∣ω )=1
d i , j d_{i, j} di,j是非负的,也就是 d i , j ≥ 0 d_{i, j} \geq 0 di,j≥0,当且仅当 p ( y i ∣ ω ^ ) ≡ p ( y i ∣ ω ^ ) p\left(y_{i} | \hat{\boldsymbol{\omega}}\right) \equiv p\left(y_{i} | \hat{\boldsymbol{\omega}}\right) p(yi∣ω^)≡p(yi∣ω^)时等号成立。这个测量是非对称的, d i , j ≠ d j , i d_{i, j} \neq d_{j, i} di,j̸=dj,i,对称版本可以写为: d i , j ′ = D ( p ( y i ∣ ω ^ ) , p ( y j ∣ ω ^ ) ) = D ( p ( y j ∣ ω ^ ) , p ( y i ∣ ω ^ ) ) = d i , j + d j , i \begin{aligned} d_{i, j}^{\prime} &=D\left(p\left(y_{i} | \widehat{\boldsymbol{\omega}}\right), p\left(y_{j} | \widehat{\boldsymbol{\omega}}\right)\right) \\ &=D\left(p\left(y_{j} | \widehat{\boldsymbol{\omega}}\right), p\left(y_{i} | \widehat{\boldsymbol{\omega}}\right)\right)=d_{i, j}+d_{j, i} \end{aligned} di,j′=D(p(yi∣ω ),p(yj∣ω ))=D(p(yj∣ω ),p(yi∣ω ))=di,j+dj,i
与两个分布的KL散度一样,这种测量能够看作 x i x_i xi和 x j x_j xj之间的判别信息,距离越小,两个样本属于同一类的可能性越大。因此,两个 l × l l \times l l×l的图像块 N i N_{i} Ni和 N j N_{j} Nj之间的距离测度为: d N i , N j = ∑ m = 1 M d N i ( m ) , N j ( m ) ′ = ∑ m = 1 M ∑ k = 1 K { p ( y N i ( m ) = k ∣ ω ^ ) log ( p ( y N i ( m ) = k ∣ ω ‾ ) p ( y N j ( m ) = k ∣ ω ‾ ) ) + p ( y N j ( m ) = k ∣ ω ^ ) log ( p ( y N j ( m ) = k ∣ ω ^ ) p ( y N i ( m ) = k ∣ ω ^ ) ) } \begin{array}{l}{d_{N_{i}, N_{j}}} \\ {=\sum_{m=1}^{M} d_{N_{i}(m), N_{j}(m)}^{\prime}} \\ {=\sum_{m=1}^{M} \sum_{k=1}^{K}\left\{p\left(y_{N_{i}(m)}=k | \widehat{\boldsymbol{\omega}}\right) \log \left(\frac{p\left(y_{N_{i}(m)}=k | \overline{\omega}\right)}{p\left(y_{N_{j}(m)}=k | \overline{\omega}\right)}\right)+p\left(y_{N_{j}(m)}=k | \widehat{\omega}\right) \log \left(\frac{p\left(y_{N_{j}(m)}=k | \widehat{\omega}\right)}{p\left(y_{N_{i}(m)}=k | \widehat{\omega}\right)}\right) \}\right.} \end{array} dNi,Nj=∑m=1MdNi(m),Nj(m)′=∑m=1M∑k=1K{p(yNi(m)=k∣ω )log(p(yNj(m)=k∣ω)p(yNi(m)=k∣ω))+p(yNj(m)=k∣ω )log(p(yNi(m)=k∣ω )p(yNj(m)=k∣ω ))}
其中M是图像块中元素的个数 M = l 2 M=l^{2} M=l2,也就是两个相似块的相似性等于相似块内所有像素新的相似性测度的和。
因此,此时的相似性度量公式变为: R i , j = exp ( − d N i , N j σ 2 ) R_{i,j}=\exp \left(-\frac{d_{N_i,N_j}}{\sigma^{2}}\right) Ri,j=exp(−σ2dNi,Nj)其中需要估计的参数有核宽度参数 σ \sigma σ,PCA降维保留的维度数 d d d.
2.2 参数估计算法
首先要确定PCA分析选择图像的前 d d d维 P f = P 1 , P 2 , … , P d P_f = P_{1}, P_{2}, \ldots, P_{d} Pf=P1,P2,…,Pd中参数 d d d和RBF核中核参数 σ \sigma σ。PCA能够通过只保留最大的 d d d个特征向量并去除噪声部分,有效地缩减特征维度。大家普遍认为核宽度参数 σ \sigma σ是噪声标准差 σ n \sigma_n σn的一个函数。噪声标准差需要噪声图像,根据PCA原理可知,获得噪声图像 I n I_n In一种直观方法是取PCA处理剩余由噪声控制图像 P r P_r Pr的的平均值。所以 d d d根据论文8中方法估计, σ n 2 \sigma_n^2 σn2由噪声图像的方差 V a r ( I n ) Var(I_n) Var(In)估计。这种噪声方差的估计策略完全依赖于图像,而不依赖额外的信息,从该意义上来说,这种估计方法是完全数据驱动的。
假设 σ \sigma σ的值是 σ n \sigma_n σn的线性函数,由所选子空间 d d d和邻域大小 l × l l \times l l×l共同表示的线性关系被认为是一种低精度估计。本文中使用论文13的方法来估计 σ \sigma σ的值, σ \sigma σ与噪声标准差 σ n \sigma_n σn的关系可以写为: σ = h × σ n h = 2 l 2 ln ( 1 / γ ) \begin{aligned} \sigma &=h \times \sigma_{n} \\ h &=\sqrt{\frac{2 l^{2}}{\ln (1 / \gamma)}} \end{aligned} σh=h×σn=ln(1/γ)2l2
常量 h h h基于具有 σ n 2 \sigma_n^2 σn2噪声特征的 I n I_n In的相同块之间的期望距离进行估计的,因此,对于 l × l l\times l l×l邻域大小,期望欧式距离的平方是 2 l 2 σ n 2 2l^2\sigma_n^2 2l2σn2.假设这样邻域之间的权重至少为 γ \gamma γ,然后可以使用第二个公式估计参数 h h h。参数 γ ( 0 ≤ γ ≤ 1 ) \gamma(0\le \gamma \le 1) γ(0≤γ≤1)是量化在一定噪声水平下两个相同邻域相似性的自由参数,其合理取值范围为0.6-0.9。
2.3 根据非局部上下文信息分类
空间上下文信息是准确分类的有效方法。本文中,利用NLM方法包含距离中心比较远的上下文信息。因此,对于给定的 ω ^ \hat{\omega} ω^,标签Y的最大后验概率为 Y ^ = arg max Y ∈ Ω n ∑ i = 1 n ∑ j ∈ S i w i , j ′ p ( y j ∣ ω ^ ) \hat{Y}=\arg \max _{Y \in \Omega^{n}} \sum_{i=1}^{n} \sum_{j \in S_{i}} w_{i, j}^{\prime} p\left(y_{j} | \widehat{\boldsymbol{\omega}}\right) Y^=argY∈Ωnmaxi=1∑nj∈Si∑wi,j′p(yj∣ω )其中 w i , j ′ = exp ( − d N i , N j / σ 2 ) ∑ j ∈ S i exp ( − d N i , N j / σ 2 ) w_{i, j}^{\prime}=\frac{\exp \left(-d_{N_{i}, N_{j}} / \sigma^{2}\right)}{\sum_{j \in S_{i}} \exp \left(-d_{N_{i}, N_{j}} / \sigma^{2}\right)} wi,j′=∑j∈Siexp(−dNi,Nj/σ2)exp(−dNi,Nj/σ2) Y ^ \hat{Y} Y^表示最大后验估计得到的标签/分类。核宽度参数 σ \sigma σ使用 γ = 0.9 \gamma = 0.9 γ=0.9估计, w i , j w_{i,j} wi,j描述像素 j j j对于像素 i i i新的值的贡献,这里表示非局部特征向量 p ( y i ∣ ω ^ ) p\left(y_{i} | \hat{\omega}\right) p(yi∣ω^)和 p ( y j ∣ ω ^ ) p\left(y_{j} | \hat{\omega}\right) p(yj∣ω^)相似性的一个函数,更具体地权重 w i , j w_{i,j} wi,j在本文中是KL散度距离的函数,且随距离增大而减小。因此,与像素 i i i相似的非局部特征对像素 i i i的真实未知特征的估计会产生很大的影响,反之亦然。核宽度参数 σ \sigma σ的作用像是控制滤波平滑度。全局平均是指图像的每个特征都对像素 i i i的特征更新做了共享。但是为了缓解计算负担,搜索框 S i S_i Si一般限制在以像素 i i i为中心的一个比较小的窗口。因此,算法复杂度限制在 O ( n s 2 ) O\left(n s^{2}\right) O(ns2)而不是 O ( n 2 ) O\left(n ^{2}\right) O(n2), n n n表示像素总数, s 2 s^2 s2表示小的搜索框S中像素的数量 s × s s\times s s×s。
attention不就是这嘛……