python学习笔记(二十七) -- 常用内建模块(二) Base64、MD5、SHA1、hmac
目录
base64
hashlib
MD5
SHA1
hmac
base64
原理
base64就是对二进制数据进行编码,比如我有6字节的二进制数据,然后每3个字节分为一组,也就是一组有3*8 = 24bit(1个字节由8位二进制数组成) ,然后把这个 24bit 分为4组,也就是每一组有6个bit。其实说白了base64就是将二进制数据每6个bit分为一组,6个bit就是6位二进制的数,最大的是111111,对应十进制就是63,也就是6位二进制数能够表示 0~63个字符。然后base64有一个字符与二进制数对应的表,如下
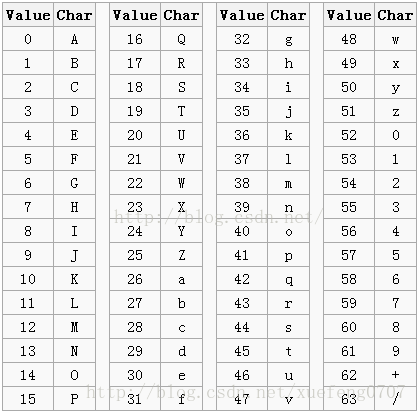
比如 6位二进制数是111111 那么对应的就是 / ,就会将 / 最终返回给我们
下表为 base64位编码过程
| 文本 | M | a | n | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASCII编码 | 77 | 97 | 110 | |||||||||||||||||||||
| 二进制位 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| 索引 | 19 | 22 | 5 | 46 | ||||||||||||||||||||
| Base64编码 | T | W | F | u |
||||||||||||||||||||
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?此时,需在原数据后面添加1个或2个零值字节,使其字节数是3的倍数。然后,在编码后的字符串后面添加1个或2个等号“=”,表示所添加的零值字节数。解码的时候,会自动去掉。
下面来看一下Base64编码的优缺点。
优点:可以将二进制数据转换成可打印字符,方便传输数据;对数据进行简单的加密,肉眼安全。
缺点:内容编码后的体积会变大,编码和解码需要额外的工作量。
它的使用场景有很多,比如将图片等资源文件以Base64编码形式直接放于代码中,使用的时候反Base64后转换成Image对象使用;有些文本协议不支持不可见字符的传递,只能转换成可见字符来传递信息。有时在一些特殊的场合,大多数消息是纯文本的,偶尔需要用这条纯文本通道传一张图片之类的情况发生的时候,就会用到Base64,比如多功能Internet 邮件扩充服务(MIME)就是用Base64对邮件的附件进行编码的。
使用方法
下面用法会报错
# 错误示例
>>> import base64
>>> s = '我是字符串'
>>> a = base64.b64encode(s) # 3.0版本以上 不允许接收 str 为参数 必须为byte
Traceback (most recent call last):
File "", line 1, in
a = base64.b64encode(s)
File "D:\工作软件\python\lib\base64.py", line 58, in b64encode
encoded = binascii.b2a_base64(s, newline=False)
TypeError: a bytes-like object is required, not 'str' 正确用法
>>> import base64
>>> s = '我是字符串'
# 先进行编码 转换为字节
>>> s = s.encode() # 默认是utf8
>>> s # byte类型数据以16进制来表示
b'\xe6\x88\x91\xe6\x98\xaf\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2'
>>> a = base64.b64encode(s) # 在编码时会自动将16进制转换为2进制,然后每6bit一组,再找到对应的字符
>>> a
b'5oiR5piv5a2X56ym5Liy'
>>> base64.b64decode(b'5oiR5piv5a2X56ym5Liy').decode('utf8')
'我是字符串'
# 转成其他编码也是可以的
>>> s = s.encode('gbk')
>>> s
b'\xce\xd2\xca\xc7\xd7\xd6\xb7\xfb\xb4\xae'
>>> a = base64.b64encode(s)
>>> a
b'ztLKx9fWt/u0rg=='
>>> base64.b64decode(b'ztLKx9fWt/u0rg==').decode('gbk')
'我是字符串'由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_:
>>> base64.b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd++//'
>>> base64.urlsafe_b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd--__'
>>> base64.urlsafe_b64decode('abcd--__')
b'i\xb7\x1d\xfb\xef\xff'
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
Base64是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。
Base64适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:
# 标准Base64:
'abcd' -> 'YWJjZA=='
# 自动去掉=:
'abcd' -> 'YWJjZA'
去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
如下:
import base64
def base64encode(raw):
return base64.urlsafe_b64encode(raw).strip("=")
def base64decode(data):
return base64.urlsafe_b64decode(data + "=" * (-len(data)%4))hashlib
MD5
使用场景:
对数据库存储的密码进行编码,避免数据库泄露造成用户密码泄露带来巨大损失。
如下:
| name | password |
|---|---|
| michael | 123456 |
| bob | abc999 |
| alice | alice2008 |
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。
正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
| username | password |
|---|---|
| michael | e10adc3949ba59abbe56e057f20f883e |
| bob | 878ef96e86145580c38c87f0410ad153 |
| alice | 99b1c2188db85afee403b1536010c2c9 |
当用户登录时,首先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明口令输入正确,如果不一致,口令肯定错误。
具体用法如下:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?'.encode('utf-8')) # 通过update将要加密的byte放进md5
print(md5.hexdigest()) # 进行加密计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
# 使用哪种编码格式对字符串进行编码,最终md5加密后的结果都是一样的
>>> import hashlib
>>> md5 = hashlib.md5()
>>> md5.update('how to use md5 in '.encode('utf-8'))
>>> md5.update('python hashlib?'.encode('utf-8'))
>>> print(md5.hexdigest())
d26a53750bc40b38b65a520292f69306
>>> md5 = hashlib.md5()
>>> md5.update('how to use md5 in '.encode('gbk'))
>>> md5.update('python hashlib?'.encode('gbk'))
>>> print(md5.hexdigest())
d26a53750bc40b38b65a520292f69306
>>> md5 = hashlib.md5()
>>> md5.update('how to use md5 in '.encode('ascii'))
>>> md5.update('python hashlib?'.encode('ascii'))
>>> print(md5.hexdigest())
d26a53750bc40b38b65a520292f69306MD5使用32个16进制数字来表示 加密后的 内容,如果被加密的字符串有一个字符改动,整个加密后的数字会完全改变。
>>> md5 = hashlib.md5()
>>> md5.update('how to use md5 in '.encode('ascii'))
>>> md5.update('python hashlib'.encode('ascii')) # 去掉了 hashlib后面的问号
>>> print(md5.hexdigest())
846014c3556d79e878be15fde5426e8a # 变动很大SHA1
SHA1比MD5加密性更强,它的加密后的结果是用40个16进制的数字来表示的。(相当于160bit)
>>> import hashlib
>>> sha1 = hashlib.sha1()
>>> sha1.update('how to use sha1 in '.encode('utf-8'))
>>> sha1.update('python hashlib?'.encode('utf-8'))
>>> print(sha1.hexdigest())
2c76b57293ce30acef38d98f6046927161b46a44比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法不仅越慢,而且摘要长度更长。
hmac
hmac在MD5和SHA1的基础上进行了进一步的安全性优化
>>> import hmac
>>> message = b'Hello,world!' # 待加密的字符串 必须为bytes类型
>>> key = b'secret' # 加密因子 必须为bytes类型
>>> h = hmac.new(key,message,digestmod='sha1') # 基于sha1加密
>>> h.hexdigest()
'942e0d84cdb8c056819d8575e94134a93993eee1'
>>> h = hmac.new(key,message,digestmod='MD5') # 基于MD5加密
>>> h.hexdigest()
'21db988f124ebc9fade5492afb9df52d'
>>>
>>> key = b'secret1' # 更改加密因子
>>> h = hmac.new(key,message,digestmod='MD5')
>>> h.hexdigest()
'7f00c6bcba9b157124335a39a862a95d' # 加密结果改变