伯克利人工智能研究:基于模型的强化学习与神经网络动力学
来源:ATYUN AI平台
让机器人在现实世界中自主行动是很困难的。即使拥有昂贵的机器人和世界级的研究人员,机器人在复杂的、非结构化的环境中仍然难以自主导航和交互。
图1:一个学习的神经网络动态模型使一个六足机器人能够学习运行和跟踪所需的轨迹,只用了17分钟
能够处理所有复杂问题的工程系统是很难的。从非线性动力学和局部观测到不可预测的地形和传感器故障,机器人特别容易受到墨菲定律的影响:会出错的事总会出错。我们不是通过编码机器人可能遇到的每一个可能的场景来对抗墨菲定律,相反,我们可以选择接受失败的可能性,并让我们的机器人从中学习。从经验中学习控制策略是很有利的,因为与手工设计的控制器不同,学习控制器可以通过更多的数据来适应和改进。因此,当出现了一个场景,在这个场景中,所有事情都出错了,尽管机器人仍然会失败,但是,当下一次遇到类似的情况时,学习的控制器很有希望改正它之前犯过的错误。为了解决现实世界中任务的复杂性,目前基于学习的方法经常使用深度神经网络,这些神经网络强大但不数据有效:这些基于尝试和犯错(trial-and-error)的学习者通常会经历第二次,第三次,甚至是成千上万次失败。在现实世界中,现代深度强化学习方法的低效率是利用以学习为基础的方法的主要瓶颈之一。
我们一直在研究用神经网络进行机器人控制的简单并高效的学习方法。对于复杂的模拟机器人,以及现实世界的机器人(图1),我们的方法能够学习机器人的运动技能,只使用从机器人在环境中随机采集的几分钟数据。在这篇博客文章中,我们将概述我们的方法和结果。更多的细节可以在本文底部的研究论文中找到。
样本效率:无模型的VS基于模型的
从经验中学习机器人技能通常基于强化学习。强化学习算法一般可分为两类:学习策略或价值函数的无模型,以及学习一种动态模型的基于模型。虽然无模型的深度强化学习算法能够学习大量的机器人技能,但它们通常会承受非常高的样本复杂度,通常需要数百万个样本才能获得良好的性能,而且通常只能一次学习一项任务。尽管之前的一些工作已经为实际操作任务部署了这些无模型的算法,但是这些算法的高复杂性和不灵活性阻碍了它们在现实世界中被广泛用于学习移动技能。
基于模型的强化学习算法通常被认为是更有效率的。然而,为了实现好的效率样本,这些传统的基于模型的算法使用相对简单的函数近似器(function approximator),它不能很好地概括复杂的任务,或概率性的动力学模型,如高斯过程(Gaussian Process),但它能很好地概括,但会对复杂性和高维域产生分歧,如能够诱导不连续的动态摩擦接触系统。相反,我们使用中等规模的神经网络作为函数近似器,它们可以达到极好的样本效率,同时还能表达出对各种复杂和高维度运动任务的泛化和应用的表达能力。
基于模型的深度强化学习的神经网络动力学
在我们的工作中,我们的目标是将深度神经网络模型在其他领域的成功扩展到基于模型的强化学习中。近年来,在将神经网络与基于模型的强化学习结合起来之前,还没有实现与更简单模型相竞争的结果,比如高斯过程。例如,在一篇名为“连续深度Q学习与基于模型的加速度”的论文1中,作者发现即使是线性模型在合成经验生成方面也取得了较好的成绩,而在论文2“通过随机值梯度学习连续控制策略”中,作者看到了将神经网络模型引入到无模型的学习系统中能够得到相对适度的成绩。我们的方法依赖于一些关键的决策。首先,我们在一个模型预测控制框架中使用学习的神经网络模型,在这个模型中,系统可以迭代地重新规划和修正它的错误。其次,我们使用的是相对短期的预测,这样我们就不必依赖模型来对未来做出非常准确的预测。这两个相对简单的设计决策使我们的方法能够执行各种各样的运动任务,而这些任务以前没有通过通用的基于模型的强化学习方法来演示,这些方法直接在原始状态观察中运行。
- 论文1:https://arxiv.org/pdf/1603.00748.pdf
- 论文2:https://arxiv.org/pdf/1510.09142.pdf
图2显示了我们基于模型的增强学习方法的图表。我们维护一个反复添加的轨迹数据集,我们使用这个数据集来训练我们的动态模型。数据集用随机轨迹初始化。然后,我们通过使用数据集训练一个神经网络动态模型,并使用学习的动态模型预测控制器(MPC)收集额外的轨迹来聚集到数据集上,从而执行强化学习。
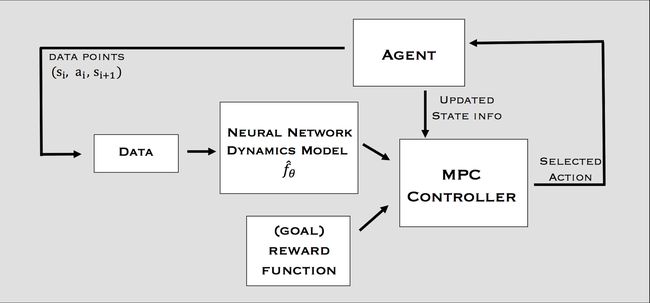
图2:基于模型的强化学习算法的概述
动态模型
我们将学习的动态函数参数化为一个深神经网络,它是由一些需要学习的权重参数化的。我们的动态函数将作为输入当前状态(state)站立行为at和输出预测的状态差异st+1−st。动态模型本身可以在一个受监督的学习环境中进行训练,收集的训练数据来自于成对的输入(st,at)和相应的输出标签(st+1,st)。
请注意,我们所提到的“状态”可以随着agent的变化而变化,它可以包括诸如质量位置的中心、质量速度的中心、关节位置和其他可测量的数量等要素。
控制器
为了使用学习的动态模型来完成一个任务,我们需要定义一个对任务进行编码的回报函数。例如,一个标准的“x_vel”回报可以编码一个前进的任务。对于轨迹跟踪的任务,我们制定了一个回报函数,它能激励我们沿着轨迹运动,并沿着轨迹向前推进。
利用学习的动态模型和任务回报函数,我们建立了一个基于模型的控制器。在每个时间步长中,agent计划H步长通过随机生成K候选动作序列,使用学到的动态模型来预测这些动作序列的结果,并选择相对应的最高累积回报的序列(图3)。然后我们仅仅执行动作序列的第一个行动,然后重复下一个时间步长的规划过程。这种重新规划使方法在学习动态模型中变得不准确。
图3:利用学习的动态模型模拟多个候选动作序列的过程,预测其结果,并根据回报函数选择最佳的结果
结果
首先,我们在强化学习平台MuJoCo上评估了我们的方法,agent包括游泳运动员、蚂蚁和猎豹。图4显示,使用我们的学习的动态模型和MPC控制器,这些agent能够遵循一组稀疏的路标所定义的路径。此外,我们的方法只用了几分钟的随机数据来训练学习的动态模型,显示了它的样本效率。
注意,使用这种方法,我们只对模型进行了一次训练,但是仅仅通过更改回报函数,我们就可以在运行时应用模型到各种不同的期望轨迹,而不需要单独的特定于任务的训练。
图4:跟随游泳者、蚂蚁和猎豹移动的轨迹。为了执行这些不同的轨迹,每个agent使用的动态模型只训练一次,只使用随机收集的训练数据
我们的方法的哪些方面对实现良好的性能很重要? 首先,我们研究了变化的MPC的规划范围地平线(Horizon)H的影响。图5显示,如果地平线太短,可能是因为无法恢复的贪婪(greedy)行为,表现会受到影响。对于猎豹来说,由于学习的动态模型的不准确,它的表现也会受到影响。图6展示了一个单一的100步长预测的学习的动态模型,显示开环(open-loop)对某些状态要素的预测最终与真实值偏离。因此,一个中期规划的地平线最好是避免贪婪的行为,同时最小化不准确模型的有害影响。
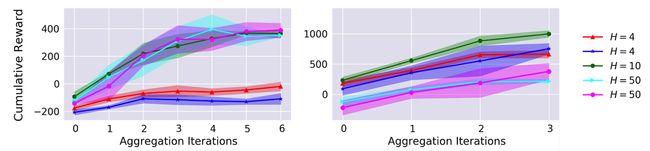
图5:由控制器使用不同的地平线值进行规划的任务性能图。太低的地平线是不好的,太高也不行
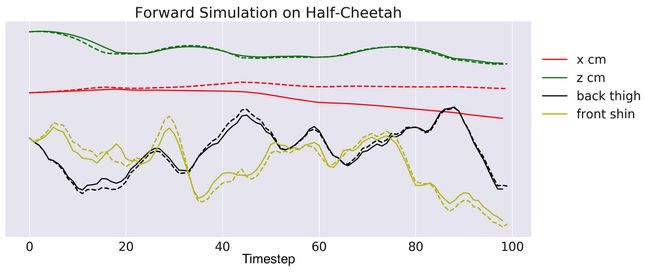
图6:动态模型的100步长前向模拟(开环),表明对某些状态元素的开环预测最终会偏离真实值
我们还改变了用于训练动态模型的初始随机轨迹的数量。图7显示,虽然较高的初始训练数据会导致更高的初始性能,但数据聚合使得即使是低数据初始化实验也能达到较高的最终性能水平。这就突出了强化学习的on-policy数据如何提高样本效率。
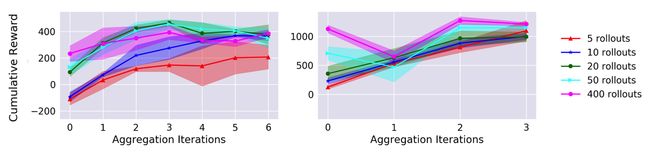
图7:使用不同数量的初始随机数据进行训练的动态模型的任务表现图
值得注意的是,基于模型的控制器的最终性能仍然远远低于一个非常优秀的无模型的学习者(当无模型的学习者接受了数千次的训练时)。这种次优性能有时被称为“模型偏差”,在基于模型的强化中是一个已知的问题。为了解决这个问题,我们还提出了一种混合的方法,它结合了基于模型的和无模型的学习,消除了收敛的渐近偏差。这种混合方法,以及额外的分析,都可以在我们的论文中找到。
学习在现实世界中运行

图8:这个机器人长约10厘米,重量约为30克,每秒钟可移动27个身长,并使用两个马达来控制6条腿
由于我们的基于模型的强化学习算法可以使用比无模型的算法更少的经验来学习移动步态,因此可以直接在一个现实世界的机器人平台上进行评估。在其他的工作中,我们研究了这个方法如何完全从现实世界的经验中学习。
对于许多应用来说,Millirobot(图8)是一种很有前途的机器人类型,因为它们的体积小,制造成本低。然而,控制这些Millirobot机器人是很困难的,因为它们动力不足、功率受限制并且体积太小。虽然手动控制的控制器有时可以控制这些Millirobot机器人,但它们通常在动态机动和复杂地形上遇到困难。因此,我们利用上面的基于模型的学习技术,使这种机器人能够实现轨迹跟踪。图9显示,我们的基于模型的控制器在经过了17分钟的随机数据训练后,可以精确地跟踪轨迹。
图9:使用基于模型的学习方法,遵循各种期望轨迹的速度
- 文章:https://arxiv.org/pdf/1708.02596.pdf
- 代码:https://github.com/nagaban2/nn_dynamics
本文转自ATYUN人工智能媒体平台,原文链接:伯克利人工智能研究:基于模型的强化学习与神经网络动力学
更多推荐
吴恩达等四位大咖对2019年AI的预测和见解
腾讯云 | 巧用机器学习定位云服务器故障
据传腾讯AI Lab主任张潼已离职,或将重返学术界
阿里达摩院 | 阿里有一群高智商员工全年无休从不领工资
 欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]
欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]