Linux性能优化读书笔记(6):文件系统
一、ext文件系统特性
磁盘分区完成之后,还要进行格式化,这个格式化操作就是指定文件系统。传统的磁盘与文件系统应用,一个分区只能够被格式化为一个文件系统,但是目前,我们格式化时已经不再说针对硬盘分区来格式化了(一个分区格式化为多个文件系统)。称呼一个可被挂载的数据为一个文件系统而不是一个分区。
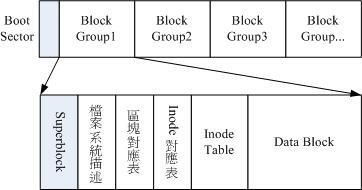
磁盘设备执行文件系统格式化时,会被分成三个存储区域
- 超级区块superlock,记录此文件系统的整体信息,包括inode和数据区块的总量使用量,以及文件系统格式
- 索引节点区inode,记录文件属性,一个文件占用一个inode,同时记录次文件的数据所在的数据块区块号码
- 数据块区(data block),实际记录文件内容。同时每个区块仅能容纳一个文件的数据,所有文件过大,会占用多个区块,如果文件过小,那么区块容量会被浪费
索引节点是存储在磁盘中的数据,自然会缓存到内存中(Cache),协调慢速设备与快速CPU性能差异。
Linux的正统文件系统为ext2(Linux second Extended file system)。他是一个索引式文件系统,也就是说inode记录的文件数据的实际存放位置为2、7、13/15这四个区块,那么排列磁盘读取顺序,可以一口气将四个区块读出来。
而U盘使用文件系统为FAT格式,FAT没有inode节点,无法将这个文件的所有区块一开始就读出来,每个区块号码都记录在前一个区块中。如果同一个文件写入的区块太分散,那么磁头无法在磁盘转一圈就读到所有数据,所以FAT系统需要碎片整理。
事实上,ex2文件系统格式化基本上是区分多个区块群组的,每个区块群组都有独立的inode,数据区块和超级区块系统。
inode节点记录的数据至少有下面这些:
- 文件读写属性(read,write,excute),拥有者与用户组
- 大小、建立时间,最近读取时间,最近修改时间
- 但是不包含文件名,文件名记录在目录的数据区块中,故文件名的增改删与目录的w权限有关
inode只有128B,所以记录区块号码时使用分级记录,使用间接的区块来记录编号
超级区块superlock记录的主要信息有:
- 数据区块与inode总量,未使用和已使用的inode和数据区块数量、大小(block为1/2/4k,inode为128B或256B)
- 文件系统挂载时间,文件系统是否挂载的标志位
区块对照表可以知道哪些区块是空的,找到可使用的空区块记录文件数据。同理,删除某些文件,占用得我区块号码就要释放出来。inode对照表与区块对照表类似,记录使用或者未使用的inode号码。
当在文件系统建立目录,文件系统会分配一个inode(通过ls命令可以看到目录也有inode)和至少一个数据区块给该目录。
- inode记录目录的的相关权限和属性,并记录分配到的那块区块号码
- 区块则记录这个目录下的文件名与该文件占用的inode号码
下图为记录于目录所属区块内的文件名与inode号码对应的示意图

所以,就像我们所说的,文件的inode本身并不记录文件名,文件名的记录是放在目录的数据区块中
linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构。将一个文件系统的顶层目录挂到另一个文件系统的子目录上,使它们成为一个整体.挂载点一定是目录,该目录为进入该文件系统的入口,磁盘分区(文件系统)的数据放在该目录下
例如,如果分区 /dev/hda5 被 挂载在 /usr 上,这意味着所有在 /usr 之下的文件和目录在物理意义上位于 /dev/hda5 上。因此文件 /usr/share/doc/FAQ/txt/Linux-FAQ 被储存在 /dev/hda5上,而文件 /etc/X11/gdm/Sessions/Gnome 却不是。
继续以上的例子,/usr 之下的一个或多个目录还有可能是其它分区的挂载点。例如,某个分区(假设为,/dev/hda7)可以被挂载到 /usr/local 下,这意味着 /usr/local/man/whatis 将位于 /dev/hda7 上而不是 /dev/hda5 上。
二、虚拟文件系统VFS(Virtual Filesystem Switch)与IO模型
Linux可以支持不同的文件系统,为了内核识别管理这些文件系统,通过VFS的内核功能来读取文件系统。VFS定义了一组所有文件系统都支持的数据结构和接口,用户进程和内核中其他子系统,只要跟VFS提供的统一接口交互即可,而不用知道底层各种文件系统的实现细节。
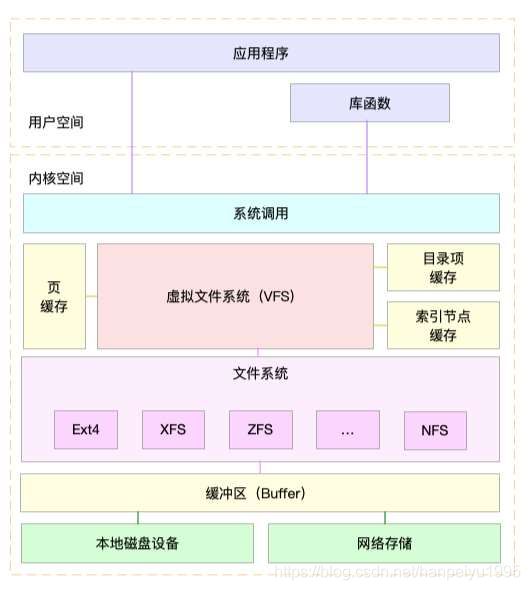
VFS提供一组标准文件访问接口,这些接口以系统调用方式,提供给应用程序。例如cat命令,首先调用open(),打开文件;然后调用read()和write()将文件内容输出到控制台标准输出中。
通常一个用户进程的IO分为两阶段:
1.数据准备阶段
2.内核空间复制回用户进程缓冲区空间
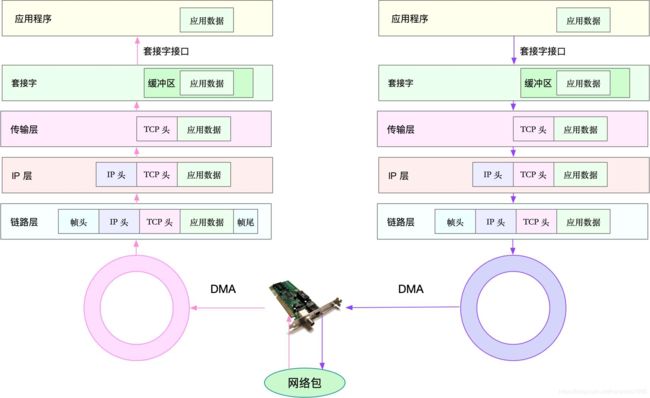
DMA汉语的意思就是直接内存访问,是一种不经过CPU而直接从内存存取数据的数据交换模式。在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了CPU资源占有率。
例如当网络帧到达网卡,网卡会 通过DMA方式,将网络包放到收包队列中,然后硬中断,告诉中断处理程序已经收到了网络报。
之后,网卡中断处理程序,为网络帧分配内核数据结构,拷贝到缓冲区中。在通过软中断,通知内核收到了新的网络帧
之后,内核协议栈从缓冲区取出网络帧,通过网络协议栈(七层或四层模型),从下而上处理。、
文件读写方式的差异,导致IO分类多种多样,主要分为四类:
第一种,是否利用标准库缓存,把文件IO分为缓冲IO和非缓冲IO
- 非缓冲IO并不是指内核不提供缓冲,而是只单纯的系统调用,不是函数库的调用。每调用一次write或read函数,直接系统调用,不经过标准库缓存。(系统内核对磁盘的读写都会提供一个块缓冲(在有些地方也被称为内核高速缓存),当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓冲进行排队,当块缓冲达到一定的量时,才会把数据写入磁盘。)
- 缓冲IO,指进程对输入输出流进行了改进,提供了一个流缓冲,当用fwrite函数网磁盘写数据时,先把数据写入流缓冲区中,当达到一定条件,比如流缓冲区满了,或刷新流缓冲,这时候才会把数据一次送往内核提供的块缓冲,再经块缓冲写入磁盘。(双重缓冲)
因此,带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。
第二种,是否利用操作的页缓存,把文件IO分为直接IO和非直接IO。
- 直接IO指跳过操作系统的页缓存,直接跟文件系统交互来访问文件
- 非直接IO,文件读写时,先经过系统的页缓存,再由内核或者额外系统调用,真正写入磁盘。
直接IO和非直接IO本质上还是和文件系统交互。在数据库场景下,跳过文件系统读写磁盘,就是通常所说的裸IO
老李去火车站买票,排队三天买到一张退票。
耗费:在车站吃喝拉撒睡 3天,其他事一件没干。
1.同步阻塞IO:
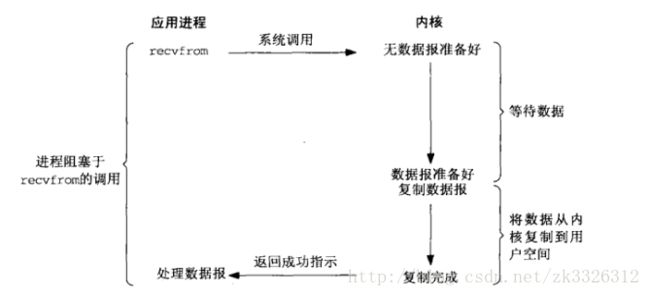
用户线程通过系统调用read发起IO读操作((通过VFS提供的接口)),由用户空间转到内核空间。内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态。内核等到数据包到达后,然后将接收的数据拷贝到用户空间,完成read操作。
老李去火车站买票,排队三天买到一张退票。
耗费:在车站吃喝拉撒睡 3天,其他事一件没干。
2.同步非阻塞IO
非阻塞Io:当用户进程发出IO操作时,在第一个阶段如果内核数据还没准备好,并不会锁住用户进程,而是立刻返回一个error。然后用户进程收到error,就知道没准备好,就会再去问内核有没有准备好,直到内核准备好,并且收到了用户进程的询问,就会立刻拷贝数据。在非阻塞IO模型中,用户进程需要不断的主动询问kernel数据好了没有。也就说非阻塞IO不会交出CPU,而会一直占用CPU
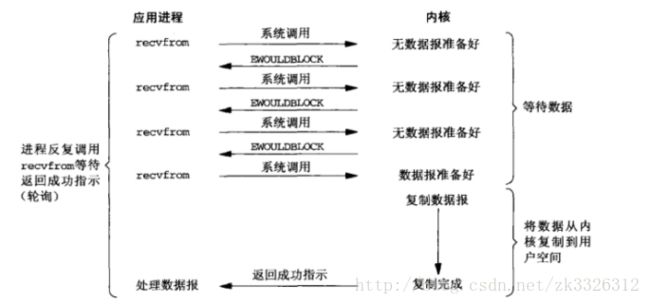
老李去火车站买票,隔12小时去火车站问有没有退票,三天后买到一张票。耗费:往返车站6次,路上6小时,其他时间做了好多事。
3、异步IO
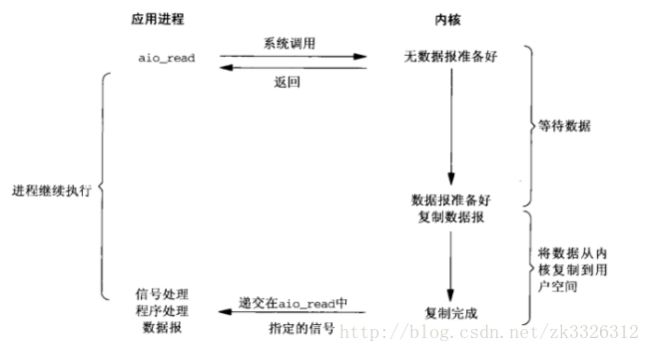
在异步IO模型中,当用户线程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它收到一个asynchronous read之后,它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何block。
然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要知道实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李并快递送票上门。
【同步/异步】表示是两个事件交互的是否有序依赖关系 :
同步:针对执行结果,A事件必须知道B事件的结果M后才执行得到结果。 例如阻塞和非阻塞IO都要知道内核数据是否准备好,再进行下一步拷贝工作。用户空间和内核是有有序依赖关系
异步:针对执行结果,执行A事件和执行B事件没有关系。例如上面的用户线程和内核交互是几乎没有关系的,表面上看用户进程的IO直接交给了内核去做,用户空间也不用得知内核数据是否准备好,收到信号即可。
阻塞/非阻塞表示执行过程出现的状态 :
阻塞:针对执行者来说,执行A事件,执行过程因为条件未满足,执行状态变成等待状态。
非阻塞:针对执行者来说,就是事件A执行遇到未满足条件,执行另外独立的C事件。
特别注意:异步只有异步,同步才有阻塞和非阻塞的说法!
三、XFS文件系统
在红帽系列的Linux默认使用的目前只有ExtX和XFS两种文件系统。在最新版本的RHEL(red hat enterprise linux)/CentOS都是默认使用了XFS。
XFS是一个日志式文件系统。
为了解决文件系统不一致,在文件系统中规划出一个区块,专门记录写入或修改文件时的步骤
1.预备。当系统写入一个文件,会在日志记录区块中记录某个文件准备写入的信息
2.实际写入:开始写入文件的权限与数据;开始更新metadata(超级区块,inode对照表及区块对照表)的数据
3.结束,完成数据域metadata更新,在日志记录区块当中完成该文件的记录。这样数据记录过程发生问题,检查日志记录区块,就可以知道哪个文件发生问题
XFS主要规划为三个部分:数据区(data section),文件系统活动登录区(log section),实时运行区(realtime section)
1.数据区类似于ext系列,与区块群组类似,分为多个存储区群组,包含1)整个文件系统超级区块2)剩余空间管理机制3)inode的分配和追踪。inode与区块都是系统需要时才动态配置生成,所以格式化操作非常快。而ext系统是预先规划区出所有的inode、区块元数据,未来可以直接使用,格式化时预先分配过慢
2.文件系统活动等录取,记录文件系统变化,类似于日志区。
3.实时运行区。