【原创】【Python 3.6】【人工智能】【深度学习】从零开始,利用CIFAR10数据库,创建深度全连接神经网络
CIFAR10数据库
CIFAR10是一套含有60000张大小为32×32彩色RGB图像的10分类图像数据库,其中的50000张图像为训练数据,10000张图像为测试数据,另外验证集的数据是从训练集中取出的。可以在下列网站下载CIFAR10数据库:
CIFAR10数据库下载地址
深度全连接神经网络
在本质上,深度全连接神经网络就是添加了多个隐含层的神经网络,互联网上的相关介绍已经足够多,在此不多赘述,只介绍本网络使用的超参数:
隐含层使用的激活函数:ReLU函数
输出层使用的损失函数:Softmax函数
训练集数据特征数量(即维度):32×32×3,3表示有RGB三个色彩通道。
为了提高训练速度,并故意地给出过拟合结果以体现该代码是正确的,在此减少训练集数量,训练集数量越少,训练准确度会越高,即出现过拟合现象
训练集数据量:500个
验证集数据量:1000个
由于该案例并不专注于模型的泛化能力,而是专注于如何使用代码实现该网络,所以不需要测试集。
隐含层层数:5层
隐含层神经元数量:从第一层到第五层隐含层 100 100 100 100 100
初始权重矩阵的标准差:0.1
训练迭代次数:500次
每个批次的训练集数量:500个
输出层神经元数量:10,即输出10个类别
学习率:0.001
正则化系数:0.0,无正则化
学习率衰减率:无衰减
训练结果
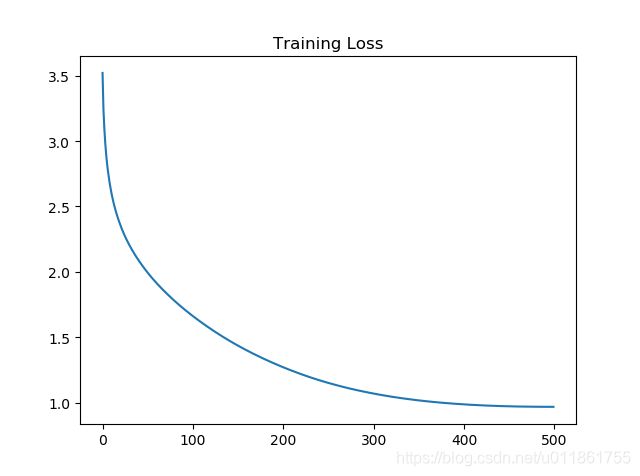
训练损失:
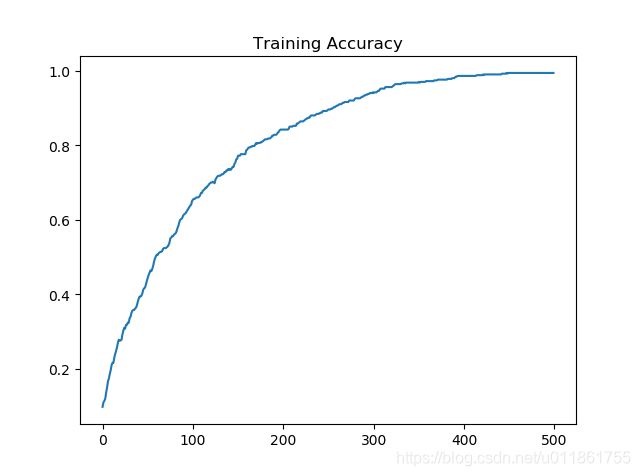
训练准确率:
验证准确率:

可以看到,由于未使用批量梯度下降,损失函数下降曲线十分光滑。而且由于未添加正则化,训练准确率在最后达到了100%,但是由于训练集太小,只有500个样本,所以导致验证准确率只有不到30%。
代码!
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import os
import _pickle as pickle
#获取CIFAR10图像数据集
def get_CIFAR10_data(num_training=50, num_validation=1000, num_test=0):
cifar10_dir = **请在这里写明CIFAR10图像数据库的文件夹路径,例如'E:/cifar-10-batches-py'**
xs = []
ys = []
for b in range(1,6):
f = os.path.join(cifar10_dir, 'data_batch_%d' % (b, ))
with open(f, 'rb') as f:
datadict = pickle.load(f, encoding = 'latin1')
X = datadict['data']
Y = datadict['labels']
X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
Y = np.array(Y)
xs.append(X)
ys.append(Y)
X_train = np.concatenate(xs)
y_train = np.concatenate(ys)
del X, Y
with open(os.path.join(cifar10_dir, 'test_batch'), 'rb') as f:
datadict = pickle.load(f, encoding = 'latin1')
X_test = datadict['data']
y_test = datadict['labels']
X_test = X_test.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
y_test = np.array(y_test)
#从原始训练集的50000张图中选出最后1000张图作为验证集
mask = range(num_training, num_training + num_validation)
X_val = X_train[mask]
y_val = y_train[mask]
mask = range(num_training)
X_train = X_train[mask]
y_train = y_train[mask]
#从原始测试集中的10000张图中选出最开始的1000张图作为测试集
mask = range(num_test)
X_test = X_test[mask]
y_test = y_test[mask]
#将训练集数据进行中心化
mean_image = np.mean(X_train, axis=0)
X_train -= mean_image
X_val -= mean_image
X_test -= mean_image
#重构尺寸
X_train = X_train.transpose(0, 3, 1, 2).copy()
X_val = X_val.transpose(0, 3, 1, 2).copy()
X_test = X_test.transpose(0, 3, 1, 2).copy()
return {
'X_train': X_train, 'y_train': y_train,
'X_val': X_val, 'y_val': y_val, \
'X_test': X_test, 'y_test': y_test,
}
#前向传播
def affine_forward(x, w, b):
"""
计算某一层的前向传播。
输入:x,N*D,若为RGB图像,则为N*(长*宽*3),N为本层的神经元数量,D为特征数量
w,D*M,M为下一层的神经元数量
b,偏置向量,M*1
返回:out,N*M
"""
out = None
#数据量
N = x.shape[0]
#将x整理成二维数组,N行,剩下的组成列
x = np.reshape(x, (N,-1))
#在数据矩阵的最后一列再添加一列1,作为偏置x0,x变成N*(D+1)
x = np.hstack((x, np.ones((N, 1))))
#将偏置向量b添加到权重矩阵w的最后一行,作为偏置x0的权重,w变成(D+1)*M
w = np.vstack((w, np.transpose(b)))
#计算下一层所有神经元对本层所有神经元的激活值,例如本层有2个神经元,下一层有3个,则输出2*3矩阵
out = x.dot(w)
return out
#反向传播
def affine_backward(dout, cache):
"""
计算反向传播
输入:
dout,上层梯度,即残差,N*M
cache, 上层
输出:
dx,输入数据的梯度,N*d1*d2*...*dk
dw,权重矩阵的梯度,D*M
db,偏置项b的梯度,M*1
"""
x, w, b = cache
dx, dw, db = None, None, None
#反向传播
#数据量
N = x.shape[0]
#将x重塑成N*D
x = np.reshape(x, (N, -1))
#计算残差的梯度
dx = dout.dot(np.transpose(w))
#计算权重的梯度
dw = np.transpose(x)
dw = dw.dot(dout)
#计算偏置的梯度
db = np.sum(dout, axis = 0)
#将dx重塑回来
dx = np.reshape(dx, x.shape)
return dx, dw, db
#RelU传播
def relu_forward(x):
"""
计算ReLUs激活函数的前向传播,然后保存结果。
输入:
x - 输入数据
返回:
out - 与输入数据的尺寸相同。
cache - x。
"""
out = None
out = np.max(np.dstack((x,np.zeros(x.shape))),axis = 2)
return out
#ReLUs反向传播
def relu_backward(dout, x):
"""
计算ReLU函数的反向传播。
输入:
dout - 上层误差梯度
x - 输入数据x
返回:
dx - x的梯度
"""
dx = dout
dx[x <= 0] = 0
return dx
#softmax损失函数
def softmax_loss(X, y):
"""
无正则化
输入:
X:神经网络的输出层激活值
y:训练数据的标签,即真实标签
输出:
loss:损失值
dx:输入数据的梯度
"""
#初始化损失值
loss = 0.0
#计算损失-------------
#训练集数据数量N
num_train = X.shape[0]
#数据类别数量C
num_catogries = X.shape[1]
#归一化概率的分子,N*C
#为了防止指数运算时结果太大导致溢出,这里要将X的每行减去每行的最大值
score_fenzi = X - np.max(X, axis = 1, keepdims = True)
score_fenzi = np.exp(score_fenzi)
#归一化概率的分母,即,将归一化概率的分子按行求和,N*1
score_fenmu = np.sum(score_fenzi, axis = 1, keepdims = True)
#将分母按列复制,
score_fenmu = score_fenmu.dot(np.ones((1, num_catogries)))
#归一化概率,N*C/(N*1)*(1*C)=N*C/N*C
prob = np.log(score_fenzi/score_fenmu)
y_true = np.zeros((num_train, num_catogries))
#把训练数据的标签铺开,例如,x是第3类,则x对应的标签为[0,0,1,0,0,0,0,0,0,0]
y_true[range(num_train), y] = 1.0
#y_true与p对应元素相乘后,只留下了每个数据真实标签对应的分数,例如x属于第3类,则留下第3个归一化概率
#求出每一行归一化概率的和,即把多余的0消除,再计算所有数据归一化概率的和
loss = -np.sum(y_true * prob) / num_train
#计算梯度--------------
dx = (score_fenzi/score_fenmu).copy()
dx[np.arange(num_train), y] -= 1
dx /= num_train
return loss, dx
#导入CIFAR10数据库
data = get_CIFAR10_data()
X_train = data['X_train']
y_train = data['y_train']
X_val = data['X_val']
y_val = data['y_val']
X_test = data['X_test']
y_test = data['y_test']
for k, v in data.items():
print(f"{k}:", v.shape)
#测试含多层隐含层的神经网络-------------------------------------------------
#网络超参数设置
hidden_layers_num = 5 #隐含层的层数
weight_scale = 1e-1 #初始权重矩阵中各元素的标准差
input_dim = 32*32*3 #输入数据的特征数量,即维度
hidden_dim = [100, 100, 100, 100, 100] #从左到右分别表示第一层到最后一层隐含层的神经元数量
num_classes = 10 #输出层神经元数量
params = {} #初始化存储有权重矩阵和偏置矩阵的字典
print("参数初始化...", end = '')
#初始化各权重矩阵与偏置向量
#初始化从输入层到第一层隐含层的权重矩阵与偏置矩阵
params['W_i_b_h'] = weight_scale * np.random.randn(input_dim, hidden_dim[0])
params['b_i_b_h'] = np.zeros(hidden_dim[0])
#初始化从第一层到最后一层隐含层之间所有的权重矩阵与偏置矩阵
for i in range(hidden_layers_num - 1):
if hidden_layers_num == 1:
break;
params['W_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)] = weight_scale * np.random.randn(hidden_dim[i], hidden_dim[i + 1])
params['b_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)] = np.zeros(hidden_dim[i + 1])
#初始化从最后一层隐含层到输出层的权重矩阵与偏置矩阵
params['W_h_b_o'] = weight_scale * np.random.randn(hidden_dim[-1], num_classes)
params['b_h_b_o'] = np.zeros(num_classes)
print('完成')
#输入数据
print('输入数据...', end = '')
X = X_train #训练集数据
y = y_train #训练集标签
print('完成')
#开始训练
#输入训练超参数
num_iters = 500 #迭代次数
batch_size = 25 #每一次迭代中从训练集中随机选取的数据量,选取出来作为一个批次
learning_rate = 1e-3 #学习率
verbose = True #是否在命令行显示训练消息
reg = 0.6 #正则化系数
learning_rate_decay = 0.95 #学习率衰减率
iterations_per_epoch = X_train.shape[0] / batch_size #遍历整个训练集需要多少个批次
#存储历次迭代的损失值、训练准确率与验证准确率
loss_history = [] #历次损失值
train_history = [] #历次训练准确率
val_history = [] #历次验证准确率
#存储每次迭代生成的权重梯度与偏置梯度的字典
grad = {}
forward_out = {}
for it in range(num_iters):
num_train = X.shape[0] #训练集中的总数据量
X_batch = None
y_batch = None
#从训练集中随机取出batch_size个训练数据
#从0到num_train-1中随机取batch_size个数字,作为一个批次的训练数据的索引
i = np.random.choice(range(num_train), batch_size, replace = True)
X_batch = X[i,:]
#标签y和训练数据X必须对应,例如取出了第3个数据,则必须取出第3个标签
y_batch = y[i]
#前向传播------------------------
#从输入层传到第一层隐含层,注意只有隐含层才有激活函数
forward_out_i2h = affine_forward(X_batch, params['W_i_b_h'], params['b_i_b_h'])
forward_out['i2h'] = relu_forward(forward_out_i2h)
#从第二层隐含层到最后一层隐含层
if hidden_layers_num > 1:
for i in range(hidden_layers_num - 1):
if i == 0:
forward_out['h' + str(i) + '_2_' + 'h' + str(i + 1)] = forward_out['i2h']
forward_out['h' + str(i + 1) + '_2_' + 'h' + str(i + 2)] = affine_forward(forward_out['h' + str(i) + '_2_' + 'h' + str(i + 1)],
params['W_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)],
params['b_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)])
forward_out['h' + str(i + 1) + '_2_' + 'h' + str(i + 2)] = relu_forward(forward_out['h' + str(i + 1) + '_2_' + 'h' + str(i + 2)])
forward_out_hidden = forward_out['h' + str(hidden_layers_num - 1) + '_2_' + 'h' + str(hidden_layers_num)]
else:
forward_out_hidden = forward_out['i2h']
#从最后一层隐含层到输出层
scores = affine_forward(forward_out_hidden, params['W_h_b_o'], params['b_h_b_o'])
#在输出层使用softmax损失函数,计算网络的总损失与梯度
loss, grad_out = softmax_loss(scores, y_batch)
#对总损失加入正则项
loss += 0.5 * reg * np.sum(params['W_i_b_h'] ** 2) + np.sum(params['W_h_b_o'] ** 2)
for i in range(hidden_layers_num - 1):
loss += 0.5 * reg * (np.sum(params['W_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)] ** 2))
#存储损失值
loss_history.append(loss)
#反向传播-------------------------------------------------------------------
#计算输出层到最后一层隐含层的残差、权重梯度与偏置梯度
dx, grad['W_o_b_h'], grad['b_o_b_h'] = affine_backward(grad_out, (forward_out_hidden, params['W_h_b_o'], params['b_h_b_o']))
#对输出层到隐含层的权重梯度加入正则项
grad['W_o_b_h'] += reg * params['W_h_b_o']
#从最后一层隐含层到第一层隐含层的所有残差、权重梯度与偏置梯度
if hidden_layers_num > 1:
for i in range(hidden_layers_num - 1, 0, -1):
if i == hidden_layers_num - 1:
forward_out['h' + str(i + 1) + '_2_' + 'h' + str(i + 2)] = forward_out_hidden
#计算第i+1层到第i层隐含层的残差、权重梯度与偏置梯度
dx = relu_backward(dx, forward_out['h' + str(i + 1) + '_2_' + 'h' + str(i + 2)])
dx, grad['W_h' + str(i + 1) + '_b_' + 'h' + str(i)], grad['b_h' + str(i + 1) + '_b_' + 'h' + str(i)] = affine_backward(dx,
(forward_out['h' + str(i - 1) + '_2_' + 'h' + str(i)],
params['W_h' + str(i) + '_b_' + 'h' + str(i + 1)],
params['b_h' + str(i) + '_b_' + 'h' + str(i + 1)]))
#对第i+1层到第i层隐含层的权重梯度加入正则项
grad['W_h' + str(i + 1) + '_b_' + 'h' + str(i)] += reg * params['W_h' + str(i) + '_b_' + 'h' + str(i + 1)]
forward_relu_out = forward_out['h' + str(0) + '_2_' + 'h' + str(1)]
else:
forward_relu_out = forward_out_hidden
#计算第一层隐含层到输入层的残差、权重梯度与偏置梯度
dx = relu_backward(dx, forward_relu_out)
dx, grad['W_h_b_i'], grad['b_h_b_i'] = affine_backward(dx, (X_batch, params['W_i_b_h'], params['b_i_b_h']))
#对第一层隐含层到输入层的权重梯度加入正则项
grad['W_h_b_i'] += reg * params['W_i_b_h']
#反向传播完成,此时回到了输入层
#通过梯度和学习率更新权重与偏置
#先更新输入层与第一层隐含层之间的权重和偏置,与,最后一层隐含层与输出层之间的权重和偏置
params['W_i_b_h'] -= learning_rate * grad['W_h_b_i']
params['W_h_b_o'] -= learning_rate * grad['W_o_b_h']
params['b_i_b_h'] -= learning_rate * grad['b_h_b_i']
params['b_h_b_o'] -= learning_rate * grad['b_o_b_h']
#如果隐含层数量大于1层,则再更新从第一层隐含层到最后一层隐含层之间的权重和偏置
if hidden_layers_num > 1:
for i in range(hidden_layers_num - 1):
params['W_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)] -= learning_rate * grad['W_h' + str(i + 2) + '_b_' + 'h' + str(i + 1)]
params['b_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)] -= learning_rate * grad['b_h' + str(i + 2) + '_b_' + 'h' + str(i + 1)]
if verbose and it % batch_size == 0:
print(f"第{it}/{num_iters}次迭代,损失为{loss},", end = '')
if it % iterations_per_epoch == 0:
#做一个预测,计算此次迭代的训练准确率、验证准确率
#计算训练准确率
pred_out = affine_forward(X_batch, params['W_i_b_h'], params['b_i_b_h'])
pred_out = relu_forward(pred_out)
if hidden_layers_num > 1:
for i in range(hidden_layers_num - 1):
pred_out = affine_forward(pred_out,
params['W_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)],
params['b_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)], )
pred_out = relu_forward(pred_out)
pred_out = affine_forward(pred_out, params['W_h_b_o'], params['b_h_b_o'])
pred_out = np.argmax(pred_out, axis = 1)
train_acc = np.mean(pred_out == y_batch)
train_history.append(train_acc)
#计算验证准确率
valpred_out = affine_forward(X_val, params['W_i_b_h'], params['b_i_b_h'])
valpred_out = relu_forward(valpred_out)
if hidden_layers_num > 1:
for i in range(hidden_layers_num - 1):
valpred_out = affine_forward(valpred_out,
params['W_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)],
params['b_h' + str(i + 1) + '_b_' + 'h' + str(i + 2)], )
valpred_out = relu_forward(valpred_out)
valpred_out = affine_forward(valpred_out, params['W_h_b_o'], params['b_h_b_o'])
valpred_out = np.argmax(valpred_out, axis = 1)
val_acc = np.mean(valpred_out == y_val)
val_history.append(val_acc)
print(f'训练准确度为{train_acc}, 验证准确度为{val_acc}')
#学习率衰减
learning_rate *= learning_rate_decay
#结果显示
plt.figure(1)
plt.plot(loss_history)
plt.title('Training Loss')
plt.figure(2)
plt.plot(train_history)
plt.title('Training Accuracy')
plt.figure(3)
plt.plot(val_history)
plt.title('Validation Accuracy')```