Task04:机器翻译及相关技术;注意力机制与Seq2seq模型;Transformer
Task04:机器翻译及相关技术;注意力机制与Seq2seq模型;Transformer
机器翻译及相关技术
预处理的小tip
字符在计算机里是以编码的形式存在,我们通常所用的空格是 \x20 ,是在标准ASCII可见字符 0x20~0x7e 范围内。 而 \xa0 属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,代表不间断空白符nbsp(non-breaking space),超出gbk编码范围,是需要去除的特殊字符。再数据预处理的过程中,我们首先需要对数据进行清洗。
Encoder-Decoder
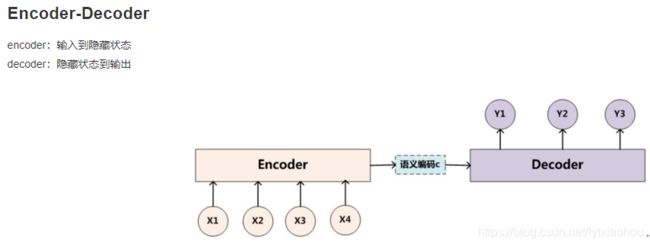
其训练和预测方式:
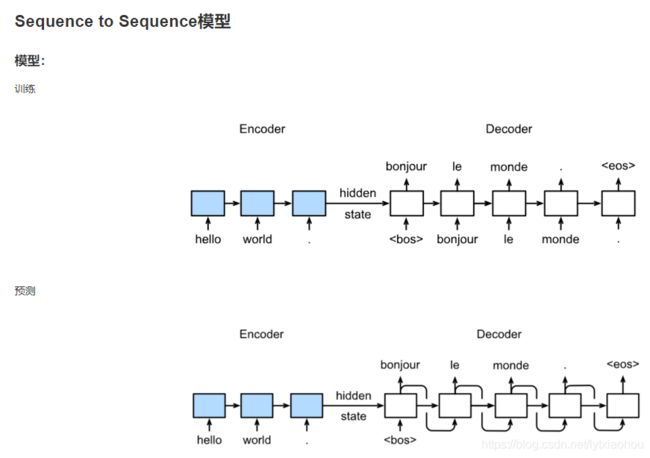
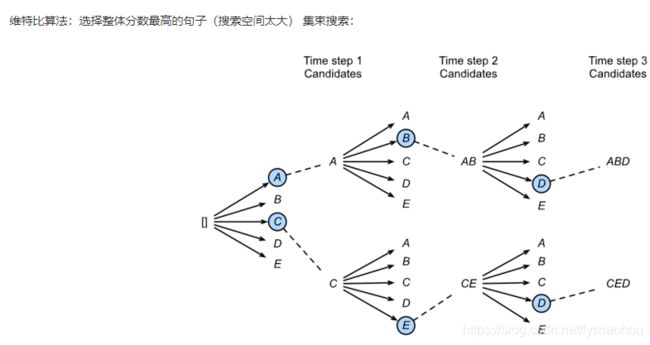
这样在预测时会有一个贪婪搜索的问题,可以一定程度的兼顾广度,即为集束搜索:
注意力机制
这个之前一直没有搞明白,现在感觉有一点点明白,复述一下我的理解。
所谓注意力机制在翻译里面就是预测的词可能只和原句中某几个词有关系,但原始的seq2seq方法只传递最后一个隐层,就导致没有办法进行这种对应。所以改用如下形式,用解码层的隐层去对每一个编码层的隐层进行query,然后softmax、加权求和,就是所谓的注意力机制。
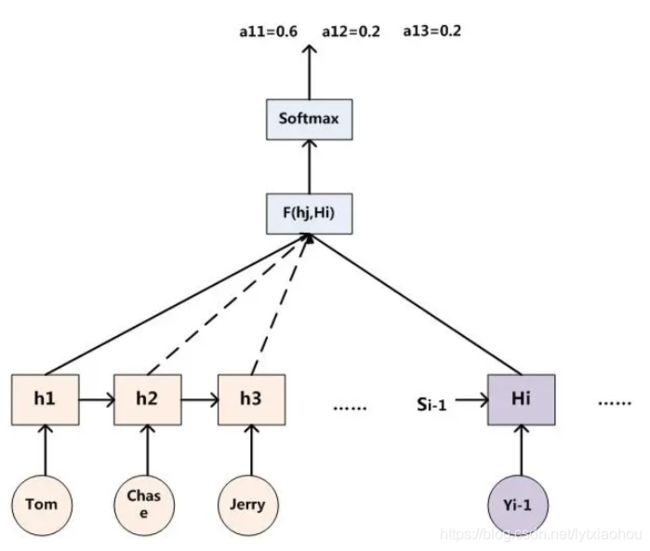
出自https://www.jianshu.com/p/e14c6a722381,这篇文章也将注意力机制讲的很透彻。
Transformer
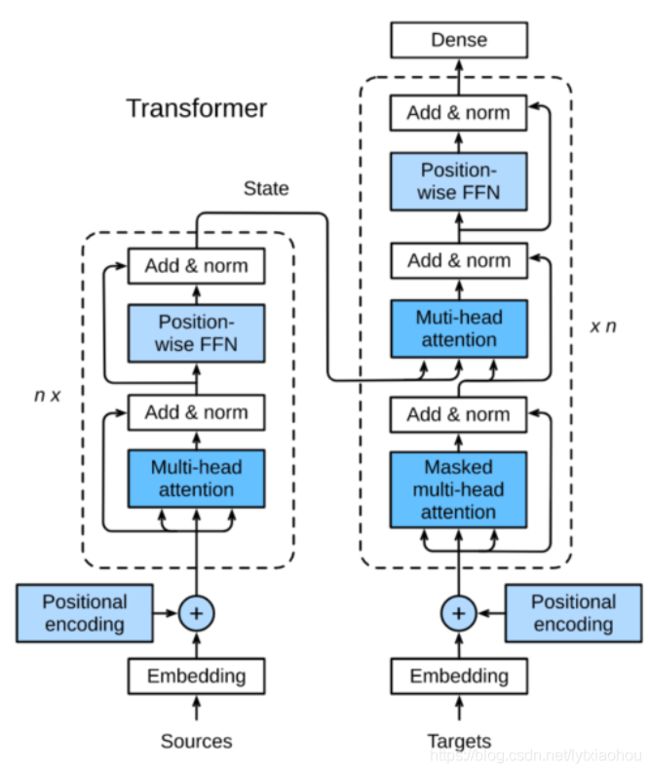
三个结构:

1.多头相当于做多个注意力机制,而不是之前的一个
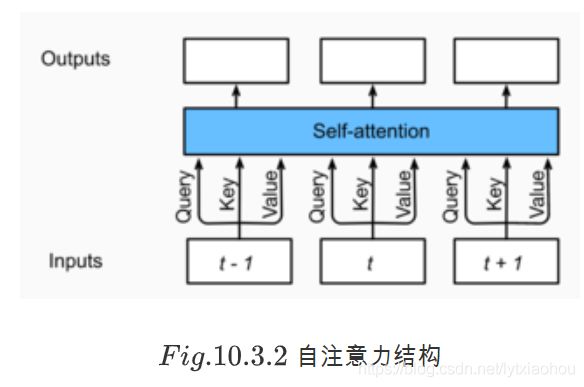
class MultiHeadAttention(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, dropout, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(input_size, hidden_size, bias=False)
self.W_k = nn.Linear(input_size, hidden_size, bias=False)
self.W_v = nn.Linear(input_size, hidden_size, bias=False)
self.W_o = nn.Linear(hidden_size, hidden_size, bias=False)
def forward(self, query, key, value, valid_length):
# query, key, and value shape: (batch_size, seq_len, dim),
# where seq_len is the length of input sequence
# valid_length shape is either (batch_size, )
# or (batch_size, seq_len).
# Project and transpose query, key, and value from
# (batch_size, seq_len, hidden_size * num_heads) to
# (batch_size * num_heads, seq_len, hidden_size).
query = transpose_qkv(self.W_q(query), self.num_heads)
key = transpose_qkv(self.W_k(key), self.num_heads)
value = transpose_qkv(self.W_v(value), self.num_heads)
if valid_length is not None:
# Copy valid_length by num_heads times
device = valid_length.device
valid_length = valid_length.cpu().numpy() if valid_length.is_cuda else valid_length.numpy()
if valid_length.ndim == 1:
valid_length = torch.FloatTensor(np.tile(valid_length, self.num_heads))
else:
valid_length = torch.FloatTensor(np.tile(valid_length, (self.num_heads,1)))
valid_length = valid_length.to(device)
output = self.attention(query, key, value, valid_length)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
2.add and norm相当于残差加归一化(但为什么要归一化呢,这一定值得挖掘)
class AddNorm(nn.Module):
def __init__(self, hidden_size, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.norm = nn.LayerNorm(hidden_size) #注意这个normal函数,日后可以直接用
def forward(self, X, Y):
return self.norm(self.dropout(Y) + X)
3.用一个编码来给位置唯一标记。(这个编码啊方式挺有意思的,日后可以参考)
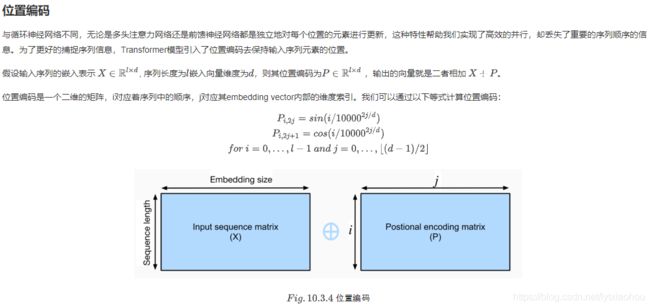
很有那么点傅里叶级数的意思,其编码思想应该有很价值,应该找原文看看
打完收工~