在安装好hadoop伪分布式后,开始搭建eclipse的hadoop开发环境
我的版本信息如下:
Ubuntu 版本 12.10
Hadoop版本 1.2.1
Java版本 1.6.0_31(命令java -version)
于2014年8月1日安装成功
1.安装Eclipse
调用我写的这篇博客 点击打开链接
2.复制eclipse_hadoop插件
在网上下载hadoop-1.2.1-eclipse-plugin.jar插件(插件版本一定要与hadoop的版本匹配,否则无法成功启动)后复制到eclipse/plugins目录下,重启eclipse
3.安装成功的表现
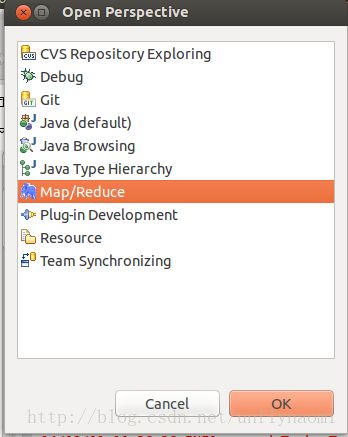
第一在open perspective >other里
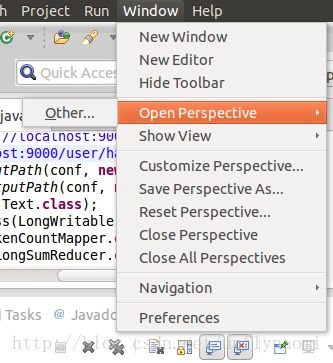
有mapreduce
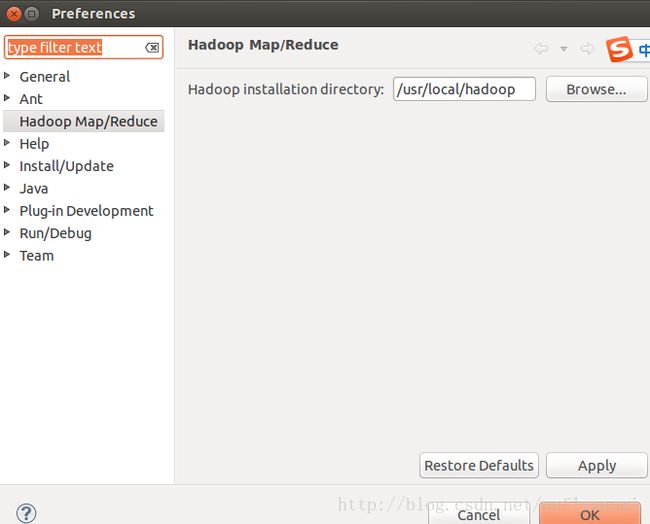
第二在 windows -> preferences里面会多一个hadoop map/reduce的选项,
4.在终端(terminal)启动hadoop
先切换用户
naomi@ubuntu:~$ su hadoop
输入密码
Password:
转到hadoop目录下
hadoop@ubuntu:/home/naomi$ cd /usr/local/hadoop
启动所有东东
hadoop@ubuntu:/usr/local/hadoop$bin/start-all.sh
这一步不做就无法连接到hadoop5.配置参数
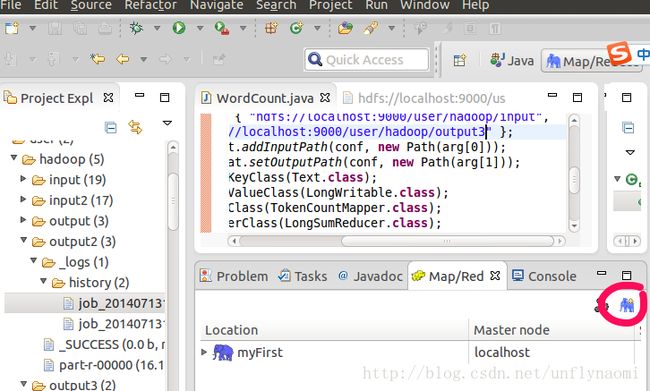
点击这个蓝大象就会new hadoop location
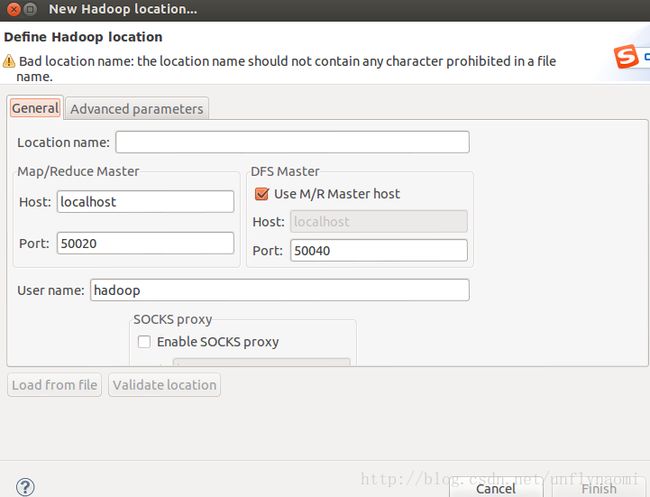
可以发现很多都是默认填好的,不需要去改,更不需要去查安装时的配置文件,在这个设置页面中,你只需要填两项
1.location name 随便取名字
2.确认user name一定是hadoop(安装hadoop时的用户),如果不是hadoop,而是root或其他用户,必须退出以hadoop用户的身份启动eclipse(若此时启动eclipse出错参见我的另一篇博客 http://blog.csdn.net/unflynaomi/article/details/38340383 ),否则出错
然后选择上面的advanced parameter选项卡

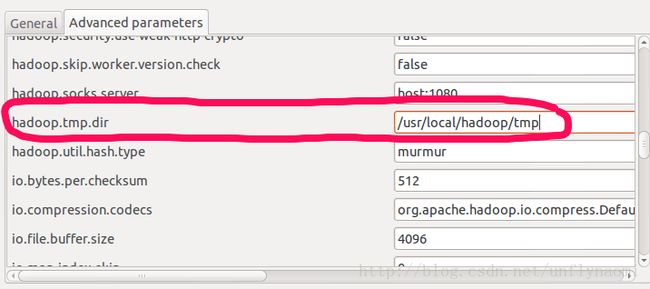
改这两项即可,其他不动这两个参数在“hadoop/conf/core-site.xml”进行了配置,可以查看
点击ok
6.加载hdfs文件系统
配置完后,就在左面有了hdfs文件系统了

如果没有出来那么一定参数配置错误选择
edit hadoop location即可重新编辑
7.创建工程
File -> New -> Project 选择“Map/Reduce Project”,然后输入项目名称,创建项目。插件会自动把hadoop根目录和lib目录下的所有jar包导入。
8.添加wordcount class
在工程上右键,new class即可,class名字为wordcount

9.运行mapreduce
源代码为:
package com.baison.action;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.lib.TokenCountMapper;
import org.apache.hadoop.mapred.lib.LongSumReducer;
public class WordCount {
public static void main(String[] args) {
JobClient client = new JobClient();
JobConf conf = new JobConf(WordCount.class);
String[] arg = { "hdfs://localhost:9000/user/hadoop/input",
"hdfs://localhost:9000/user/hadoop/output3" }; //这句指明了输入输出文件,input文件夹下所有文件都是输入文件,输出目录不可重复
FileInputFormat.addInputPath(conf, new Path(arg[0]));
FileOutputFormat.setOutputPath(conf, new Path(arg[1]));
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(LongWritable.class);
conf.setMapperClass(TokenCountMapper.class);
conf.setCombinerClass(LongSumReducer.class);
conf.setReducerClass(LongSumReducer.class);
client.setConf(conf);
try {
JobClient.runJob(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
} Run As -> Run on Hadoop
部分运行过程如下
14/08/01 10:36:27 INFO mapred.JobClient: Total committed heap usage (bytes)=3001692160
14/08/01 10:36:27 INFO mapred.JobClient: CPU time spent (ms)=0
14/08/01 10:36:27 INFO mapred.JobClient: Map input bytes=34768
14/08/01 10:36:27 INFO mapred.JobClient: SPLIT_RAW_BYTES=2074
14/08/01 10:36:27 INFO mapred.JobClient: Combine input records=3452
14/08/01 10:36:27 INFO mapred.JobClient: Reduce input records=1654
14/08/01 10:36:27 INFO mapred.JobClient: Reduce input groups=871
14/08/01 10:36:27 INFO mapred.JobClient: Combine output records=1654
14/08/01 10:36:27 INFO mapred.JobClient: Physical memory (bytes) snapshot=0
14/08/01 10:36:27 INFO mapred.JobClient: Reduce output records=871
14/08/01 10:36:27 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0
14/08/01 10:36:27 INFO mapred.JobClient: Map output records=3452
部分运行结果如下:(可以直接在eclipse中查看)
"". 4
"*" 10
"AS 6
"License"); 6
"alice,bob 10
"console" 2
"hadoop.root.logger". 2
"jks". 4
圆满成功
本文部分参考http://blog.csdn.net/xiaotom5/article/details/8080595#