KNN, LDA, SVM 实战 —— 运用在Farm-ads(python)
概述
使用KNN,LDA,SVM求解UCI中的Farm-ads数据集。其中KNN为纯手写,LDA包括手写和使用sklearn的模块,SVM也包括手写和使用sklearn模块。
github代码
实验环境
anaconda + jupyter notebook + python3.7
数据
数据集来源
实验数据来源于:UCI机器学习数据库(http://archive.ics.uci.edu/ml/index.php)
其中,本次实验用到的数据集是Farm Ads Data Set。
其中UCI是一个非常适合入门的数据库,里面包括各种大小数据集,适用于分类,回归等多种任务。
数据集分析
这是一个纯文本数据集。每一行(共有4143行)是一条广告分割出来的单词。第一个特征是y,取值为1或者-1,代表该广告是否被接受。我们要做的就是,给定一系列的单词,判断这些单词组成的广告是否会被接受。
数据预处理
- 数据集格式
首先看一下数据的具体情况。一共有两个文件,一个是farm-ads,一个是farm-ads-vect。第一个打开后如图1所示:

图1:farm-ads
里面的每一行代表一条广告。其中第一个词是1或者-1,表示这条广告是否会被拒收。也就是最后的y。x便是后面的单词。其中存在一些没有意义的前缀和单词,如“page”“com”等。下一步会进行预处理。
Farm-ads-vect打开之后如图2所示。数据提供者将单词转换成为一个id,每个单词对应一个id。但是感觉不是很对应,有些数据对应出错。所以后面的实验并没有使用该文件。
图2:farm-ads-vect
- 数据预处理思路
对于文本数据,常见的处理思路是根据词料(也就是源数据)建立词表,给每个单词一个唯一的编号。然后对于每条数据,使用one-hot编码。不过针对这个相对较小的数据集(4w+)还勉强可以。如果词料变多,将会陷入维度灾难(后面实验有遇到)。
同时,在生成one-hot编码之前,还会进行一个清洗处理。将词料中的无意义词去除,如“com”,“page”等。这些词出现并无规律,会对结果造成影响。并且还去除了“ad-”等无意义前缀。这样子可以生成更加纯粹的单词。这方面的工作可以从“preprocess/loadData”函数中看到,如图3所示:

图3:去除无意义词
接着使用findAllWord函数以及genDataMatrix函数生成one-hot编码,并且在此过程中提取出结果(第一个特征),将x和y分开。并且写好10折交叉函数cross_10folds。
这部分的工作可以从preprocess.py中查看。
- 数据预处理结果
得到一个词表,共有44155个单词。这意味着每一个x的特征数量有44155个,在该样例中出现的单词的编号的位置为1.所以最终的x矩阵其实是非常稀疏的。这方面的问题在NLP领域有不少处理的方式,如word2vec,由于时间限制,所以没有进一步实现。
 图4:词表规模
图4:词表规模
实战过程
在小数据集上测试
除了手写实现KNN,LDA,SVM算法,我还使用深度学习框架sklearn中的LDA和SVM算法和自身实现的版本进行对比(KNN由于原理简单,故没有进行测试)。
为了便于调试,我在原先的数据集上随机抽取了一部分数据,用于算法正确性的测试,名为‘small’。下面将对几种算法的实现进行简要介绍,并给出小测试集上的结果。小数据集的规模如下图所示。
![]()
图5:小规模数据集
KNN
KNN的原理相对简单,主要是计算特征空间之间的距离。在实现过程中,k取5。图6所示是在手写KNN在小测试集上的结果。利用10折测试,平均准确率大概有0.66。这部分代码可以从KNN.py中查看。

图6:手写KNN小数据集上结果
LDA
LDA大部分情况下是用来进行降维的,如同PCA,但也可以用来进行二分类。LDA的实现比较简单,主要是使用矩阵间的变化。但是我根据公式实现之后,发现由于数据矩阵太过稀疏,所以称为了一个奇异矩阵,无法进行求逆操作。这导致手写LDA算法测试失败,如图7所示。这部分代码可以从LDA.py中查看,里面有两个手写版本,均无法使用。

图7:手写LDA小数据集上结果
之后使用了sklearn中的LDA,发现是可以跑得通的(在小数据下可以,大数据也是不行的),可能在实现上有所区别。但是也出现了警告“variables are collinear”,变量是共线的。这也是由于矩阵过于稀疏的原因,如图8所示。这部分代码可以从LDA.py中查看。

图8:sklearn LDA小数据集上结果
SVM
SVM的原理更加复杂一些。但却是最好的分类器之一。我参考了网上的教程,并基本数据集实现了手写的SVM,不过实现结果似乎比KNN还差。初步估计是:由于是一个二分类问题,所以KNN中前K的结果,有比较大的可能找到正确的。(广告间的共性),而SVM考虑的因素更多,过于复杂反而使得解的质量下降。结果如图9所示,这部分代码可以从SVM.py中查看。
图9:手写SVM 小数据集上结果
之后使用sklearn中的SVM,发现其准确率相比自己实现的准确率高出接近一半。使用的核函数是‘linear’,C=1, gamma=1。如图10所示。这部分代码同样可以在SVM.py中查看。

图10:sklearn SVM 小数据集上结果
在大数据集上测试
确认模型无误之后,在整个数据集上训练和测试。
整个数据集的所有单词数目(除去无意义单词)是44155个,相比之前的小数据集规模大了一倍,这也意味着数据矩阵会更加稀疏,并且每一个行的特征会变大。下面给出运行之后的结果截图。思路和之前的一样,并且加上了程序计时。

图11:KNN 全数据集测试
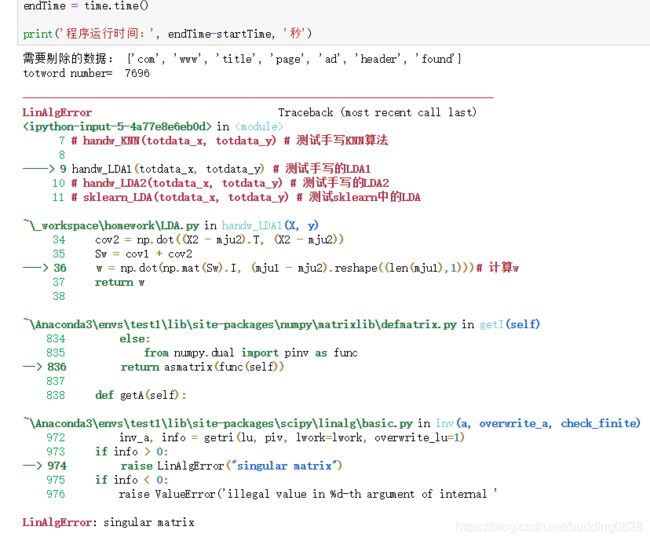
图12:手写LDA全数据集测试
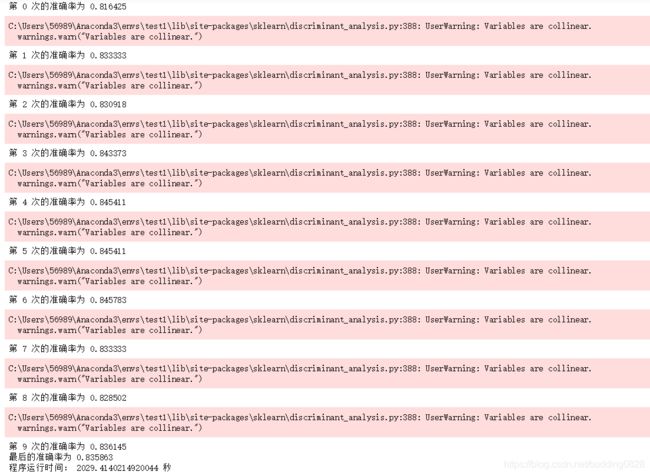
图13:sklearn LDA全数据集测试

图14:手写SVM全数据集测试

图15:sklearn SVM全数据集测试
结果分析
| 算法名称 | KNN | Handw_LDA | sklearn_LDA | Handw_SVM | sklearn_SVM |
|---|---|---|---|---|---|
| 准确率 | 0.811719 | (未能求解) | 0.835863 | 约0.4 | 0.886317 |
| 时间(s) | 5526.78 | (未能求解) | 2029.41 | (超过24h) | 3613.19 |
这里针对上述图表进行分析。需要说明的有两点:
- 如图13所示,手写的LDA是无法求解的,问题出现在稀疏矩阵求逆上,对于该数据集是不合适的。所以Handw_LDA没有结果。
- 手写的SVM跑了12个小时(电脑几乎卡死),还是只跑了一半。如果全部跑完,需要24h,并且准确率并没有很高。
实验分析:
从分类准确率上看:
- 对于该数据集,可以看出SVM分类器还是占优的。LDA和KNN的结果相对接近。
- 这三个分类器都能有比较好的分类效果。(针对该数据集)推测原因是因为这只是一个简单的二分类问题。
从运行时间上看:
- LDA是最快的。这是可以理解的。KNN每次都需要计算和其他所有样本计算距离(总的样本数目是4143),所以需要非常久的时间,并且维度有4w。而SVM的计算更加复杂。而LDA主要是求解一个w矩阵,有了这个矩阵之后,每一个测试数据只需和这个w相乘就可以得出预测的分类。更加高效。
- 手写的SVM性能不佳,并且分类效果也不佳,这将在以后的学习中不断寻求改进方式。
后记:
在实验完成之后,发现对于NLP的维度灾难问题,已经有很多人进行研究并提出改进方法,一个是word2vec,一种是sentence2vec。由于时间限制,在本次实验中没有进行,不过我非常感兴趣,因为这个实验我在做的过程中,维度灾难确实困扰我非常久,我非常希望能有办法去解决。这里给出一些学习链接,方便以后自己学习:
- word2vec
- 介绍和实现:https://blog.csdn.net/xsdxs/article/details/72951545
- 介绍Word2vec和ELMO:https://www.jianshu.com/p/a6bc14323d77
- 机器之心介绍:https://www.jiqizhixin.com/articles/2018-12-10-8
- 进一步扩展为sentence2vec:
有几个思路:
- 使用word2vec,并且将句子中的每个单词的vec相加。然后比较两个句子的距离。(当然,对于短文本是可以的,但是对于长文本的效果很差,因为相加过程中会损失很多单词间的相关性以及句意)
- 首先选出一个词库,比如说10万个词,然后用w2v跑出所有词的向量,然后对于每一个句子,构造一个10万维的向量,向量的每一维是该维对应的词和该句子中每一个词的相似度的最大值。然后计算向量之间的距离。