KPI异常检测【三】- 机器学习算法
目录
1、相关概念
1.1 异常类型
1.2 检测方法
2、点异常检测算法
2.1 基于统计
2.2 基于相似度 2.2.1 基于距离 2.2.2 基于密度 2.2.3 基于聚类 2.2.4 基于树
2.3 基于谱(spectral)
3、上下文异常检测算法
3.1 直接与间接
3.2 上下文异常(时序、图)
3.3 单变量与多变量
4、时序特征构造
1、相关概念
1.1 异常类型
异常点是指数据中和其它点不一样的点,异常检测就是要找到这些点。通常有以下这些不同类型的异常:
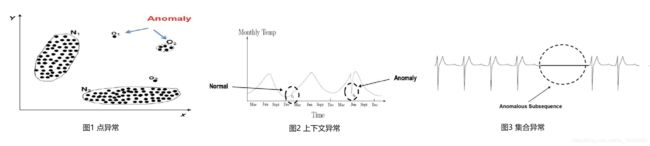
- 点异常(Point Anomalies):单个点和其它数据显著的不同。
- 上下文异常 (Contextual Anomalies):数据在所在的上下文环境中是个异常。
- 集合异常(Collective Anomalies):指一组数据点和其它的数据有显著的不同,这一组数据的集合构成异常。
1.2 检测方法
(1)标记(labels):
无监督:无标注,假设数据中正常数据比异常数据多很多。常用方法分为基于统计分布、基于距离、基于密度、基于距离、基于聚类和基于树的五类方法。
半监督:被标注的全是正常数据。常用方法包括one-class SVM、AutoEncoder、GMM等。
有监督:数据标注是个问题,并且处理时需要注意类别不均衡现象,不适用于检测新类别。常用方法包括LR、SVM、RF、NN等。
| 样本类型 | 困难 | |
| 有监督 | 平衡 | 样本极度不平衡时,训练难;人工标记难 |
| 半监督 | 极度平衡 | 可能无异常样本 |
| 无监督 | 无标签 | 有强假设关系,检测存在偏差 |
(2)直接检测(点异常)与间接检测(非点异常)
2、点异常检测算法
2.1 基于统计
需要假设数据服从某种分布,然后利用数据去进行参数估计。
方法主要三种,简单的比如有3σ准则、箱型图、Grubbs检验等。复杂点的比如有时间序列建模(移动平均、指数平滑、ARMA、ARIMA)。还有混合方法,假设正常数据和异常数据来自不同的高斯分布,然后用Grubbs检验;或者仅对正常数据进行混合高斯建模或者泊松建模等等。
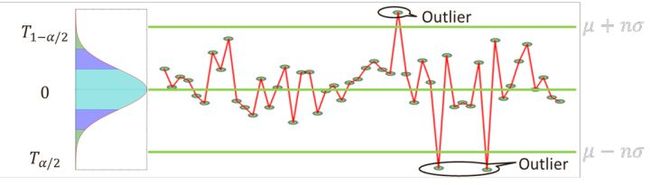
(1)N-sigma :
n-sigma准则基于目标分布是正态或近似正态分布。一般地,选取n=3。根据正态分布的概率密度公式可以算出,样本取值几乎全部(99.7%)集中在 区间内,其中,
超出这个范围的可能性仅占不到0.3%,可以认为是小概率事件。因此,检测的方法也比较简单,如下:
- 检测突增异常:异常区间为 ;
- 检测突降异常:异常区间为 ;
- 检测双向(突增或突降)异常: 或, 如下图所示;
(2)boxplot(单变量)
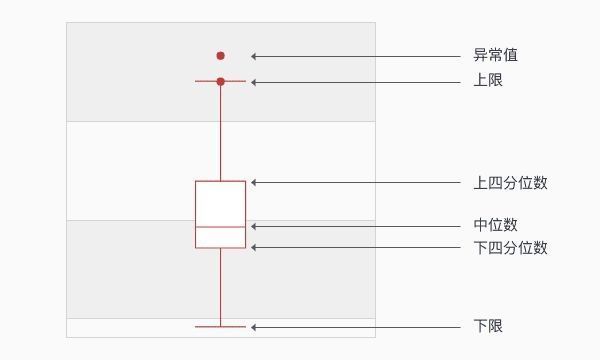
为了降低异常点的影响,boxplot准则被提出。boxplot(箱线图)是一种用作显示一组数据分散情况的统计图,经常用于异常检测。BoxPlot的核心在于计算一组数据的中位数、两个四分位数、上限和下限,基于这些统计值画出箱线图。
记 Q1、Q3分别表示一组数据的下四分位数和上四分位数,则

根据上面的统计值就可以画出下面的图,超过上限的点或这个低于下限的点都可以认为是异常点。
(3)卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
![]()
(4)Grubbs检验(多变量)参见:Grubbs Test
(5)其他方法参见:几种常见的离群点检验方法
优点:方法简单,适合低维数据、鲁棒性较好,速度快
缺点:对假设依赖比较严重,效果不好
2.2 基于相似度
2.2.1 基于距离
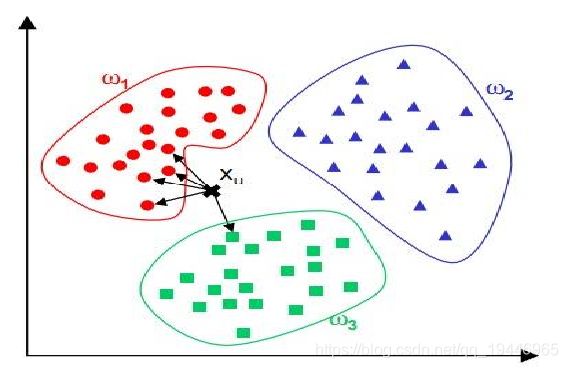
这种方法认为异常点距离正常点比较远,因此可以对于每一个数据点,计算它的K-近邻距离(或平均距离),并将距离与阈值进行比较。若大于阈值,则认为是异常点。或者是将全部样本的K-近邻距离排序,取前n个最大的作为异常点。计算距离时一般使用欧式距离,也可以使用角度距离。
KNN:基于假设正常点的周围存在很多个近邻点,而异常点距离周围点的距离都很远。
优点:无分布假设
缺点:不适合高维数据
只能找出异常点,无法找出异常簇
每一次计算近邻距离都需要遍历整个数据集,不适合大数据及在线应用
参数K和阈值需要人工调参
当正常点较少、异常点较多时,该方法不好使
当使用欧式距离时,即默认是假设数据是球状分布,因此在边界处不容易识别异常
仅可以找出全局异常点,无法找到局部异常点
2.2.2 基于密度
基于距离的方法中,阈值是一个固定值,属于全局性方法。但是有的数据集数据分布不均匀,有的地方比较稠密,有的地方比较稀疏,这就可能导致阈值难以确定(稠密的地方和稀疏的地方最好不用同一阈值)。我们需要根据样本点的局部密度信息去判断异常情况。基于密度的方法主要有LOF、COF、ODIN、MDEF、INFLO、LoOP、LOCI、aLOCI等。
LOF(local outlier factor):局部离群因子,基于假设正常点周围的密度类似于其近邻的周围的密度,而异常点周围的密度与其近邻周围的密度明显不同。
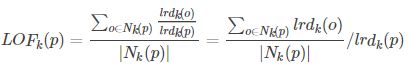
LOF是一个比值,分子是K个近邻的平均局部可达密度,分母是该数据点的局部可达密度。可达密度是一个比值,分子是K-近邻的个数,分母是K-近邻可达距离之和。上式表示点p的邻域点Nk(p)的局部可达密度与点p的局部可达密度之比的平均数。
- local outlier factor越接近1,说明p的其邻域点密度差不多,p可能和邻域同属一簇;
- local outlier factor越小于1,说明p的密度高于其邻域点密度,p为密集点;
- local outlier factor越大于1,说明p的密度小于其邻域点密度,p越可能是异常点。
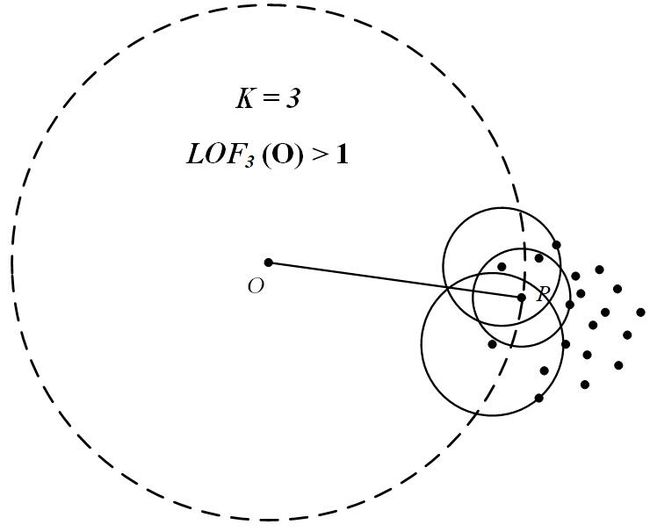
因为LOF对密度的是通过点的第k邻域来计算,而不是全局计算,因此得名为“局部”异常因子,这样,对于图1的两种数据集C1和C2,LOF完全可以正确处理,而不会因为数据密度分散情况不同而错误的将正常点判定为异常点。
实现参见:https://www.cnblogs.com/bonelee/p/9848019.html
优点:可以找出分布不均匀的数据中局部异常的数据
可以给出数据的异常得分,得分越高越可能异常,不是二分类
缺点: 计算量大
不适合高维数据
由于需要遍历数据计算距离,因此计算复杂度也很高,不适合在线应用
只能找到异常点,无法找出异常簇
需要人工调参
2.2.3 基于聚类
假设一:不属于任何聚类的点是异常点,主要方法包括DBSCAN、SNN clustering、FindOut algorithm、WaveCluster Algorithm。
缺点:不能发现异常簇
假设二:距离最近的聚类结果较远的点是异常点,主要方法包括K-Means、Self-Organizing Maps(SOM)、GMM。
首先进行聚类,然后计算样例与其所属聚类中心的距离,计算其所属聚类的类内平均距离,用两者的比值衡量异常程度。
缺点:不能发现异常簇
假设三:稀疏聚类和较小的聚类里的点都是异常点,主要方法包括CBLOF、LDCOF、CMGOS等。
首先进行聚类,然后启发式地将聚类簇分成大簇和小簇。如果某一样例属于大簇,则利用该样例和其所属大簇计算异常得分,如果某一样例属于小簇,则利用该样例和距离其最近的大簇计算异常得分。三种算法的区别在于计算异常得分的方式不同,具体细节还未看。
优点:考虑到了数据全局分布和局部分布的差异,可以发现异常簇
具体实现参见:https://www.cnblogs.com/bonelee/p/7776565.html
优点:聚类参数难界定,结果受初始参数影响大
测试阶段会很快,以内只需要和有限个簇比较
有些聚类算法(k-means)可以在线应用(准实时)
缺点:异常检测效果很大程度上依赖于聚类效果,但是聚类算法主要目的是聚类,并不是为了异常检测
大数据聚类计算开销比较大,可能是个瓶颈
2.2.4 基于树
此类方法的思想是基于划分子空间寻找异常点,异常点所在树深度小于正常点。,不同的方法区别主要在三个地方:特征的选取、分割点的选取和分类空间打标签的方案。此类方法不受球形邻近的限制,可以划分任意形状的异常点。此类方法主要包括iForest、SCiForest、RRCF。
iForest:只适合检测全局异常点(Robust random cut forest based anomaly detection on streams[C]// International),不适合检测局部异常点,因此有人做了改进, 论文为--Improving iForest with Relative Mass.
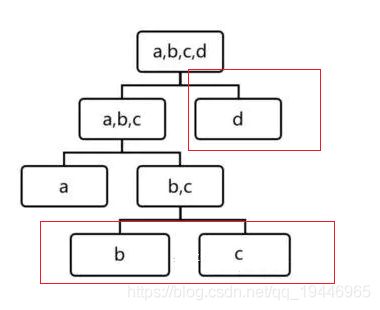 正常点所在树的深度更深。
正常点所在树的深度更深。
SCiForest:传统iForest方法在选择特征是随机选取的,SCiForest在选择特征时利用了方差;传统iForest选择分割点后形成的分割超平面是平行于坐标轴的,SCiForest可以生成任意角度的分割超平面。
RRCF:可以动态增删树种的节点,适用于流数据异常检测。--Conference on International Conference on Machine Learning-volume. JMLR.org, 2016.
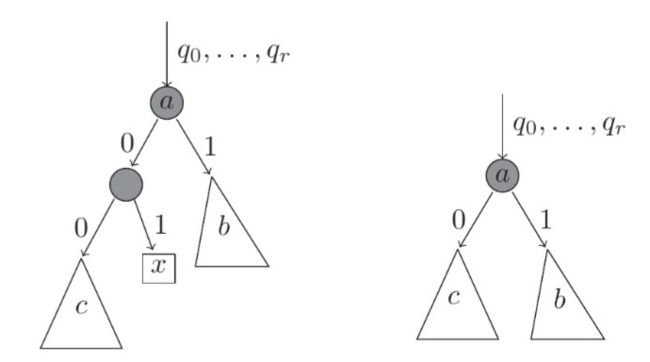
上图,x是否导致模型变化的程度
优点:分布式计算,非距离计算速度快
每棵树都是独立构建,适合分布式计算
可以分割任意形状的数据集,不受限于球形近邻
测试时速度很快,适合在线处理
缺点:解决全局异常
只适用于异常点较少的情况
高维数据特征随机影响结果,因为高维数据会有很多无关特征
2.3 基于谱(spectral)
残差检测:重构误差(PCA、Autoencoder、VAE),谱残差(SR)-频域变换
3、上下文异常检测算法
3.1 直接与间接
直接检测:针对点异常,算法直接定位“离群”点
间接检测:先转化成点异常问题(如上下文或集合异常),再基于已有的点异常检测算法进行求解
3.2 上下文异常(时序、图)
1) 图或子图特征(顶点、边、出度、入度等)做变换,转化成点异常问题
Graph based anomaly detection and description: a survey[J]. Data Mining & Knowledge Discovery, 2015
2)时序数据异常检测
自相关和非自相关:时序独立VS 时序相关(点异常和上下文异常)
- 时序预测:ARIMA, MA,指数光滑,回归模型(时序连续点)、HMM (时序离散事件)
- 重构:PCA、Autoencoder 残差检测
- 集合异常:时序(转化成点异常问题)
3.3 单变量与多变量
单变量(上下文异常):a)时序预测+点异常检测,b)划窗变换+点异常检测
多变量:
- 深度学习:LSTM预测算法
- 多变量时序预测1:https://github.com/Seanny123/da-rnn
- 多变量时序预测2:https://github.com/chickenbestlover/RNN-Time-series-Anomaly-Detection
4、时序特征构造
Load forecasting using support vector Machines: a study on EUNITE competition 2001[J]. IEEE Transactions on Power Systems, 2004
1.历史数据的周期滑窗特征;
2.除了滑窗特征,还可以加入一些周期内数据的均值和方差等统计特征作为回归模型的特征输入
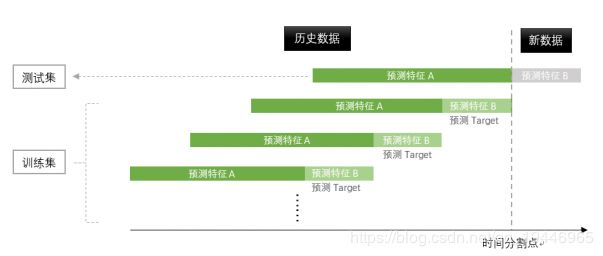
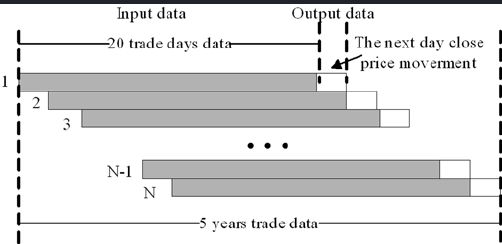
3.其他特征
| 时序预测算法 | 优点 | 缺点 |
| 一阶指数光滑(SES,EWMA) | 方法简单,计算速度快。 | 趋势,季节性等复杂波形拟合效果差 |
| 三阶指数光滑(Holtwinter) | 周期波形拟合比较准确。 | 计算复杂度高,性能较差,算法待优化的参数多 |
| 深度学习模型(LSTM) | 波形拟合度准确。 | 计算复杂度高,针对大量的待检测KPI指标较难应 |
参考:
- https://zhuanlan.zhihu.com/p/67396219
- https://www.cnblogs.com/rnanprince/articles/10790313.html
- https://blog.csdn.net/qq_19446965/article/details/89395190
- https://blog.csdn.net/qq_19446965/article/details/106460747
- https://blog.csdn.net/qq_19446965/article/details/89392892
- https://www.cnblogs.com/coshaho/p/9807923.html
- https://www.cnblogs.com/bonelee/p/9848019.html
- https://www.cnblogs.com/bonelee/p/7776565.html
- https://www.jianshu.com/p/c5e4e7dce972
- Robust random cut forest based anomaly detection on streams[C]// International
- Conference on International Conference on Machine Learning-volume. JMLR.org, 2016.
- Time-Series Anomaly Detection Service at Microsoft[J]. 2019.
- Graph based anomaly detection and description: a survey[J]. Data Mining & Knowledge Discovery, 2015
- https://github.com/Seanny123/da-rnn
- https://github.com/chickenbestlover/RNN-Time-series-Anomaly-Detection
-
http://www.jeepxie.net/article/691238.html
-
http://www.infocomm-journal.com/txxb/CN/10.11959/j.issn.1000-436x.2019159