【Cassandra从入门到放弃系列 三】Cassandra的数据模型设计
前两篇分别介绍了为什么要使用NoSql数据库及为什么选用Cassandra作为业务数据库以及其基于列的存储模式对于处理海量数据聚合计算的优势,本篇详细说明下Cassandra的数据模型是如何设计的?
基本数据模型【列】
数据模型中有如下几个概念:Column,Super Column,Column Family以及Keyspace。
列Column
在Cassandra中,列是基本单元,可以想象为关系型数据库中的列。
普通列Column
Column是Cassandra所支持的最基础的数据模型。该模型中可以包含一系列键值对,列是Cassandra的基本数据结构,具有三个值,即列名称,值和时间戳
{
"name": "Auther Name",
"value": "Sam",
"timestamp": 123456789
}
其数据结构如下图所示:

超级列Super Column
Super Column则包含了一系列Column。在一个Super Column中的属性可以是一个Column的集合,一般会把几个常用的属性定义为一个超级列
{
"name": "Cassandra Introduction",
"value": {
"auther": { "name": "Auther Name", "value": "Sam", "timestamp": 123456789},
"publisher": { "name": "Publisher", "value": "China Press", "timestamp": 234567890}
}
}
其数据结构如下图所示,key为一个超级列名称,value为column的集合。

列族Column Family
Column Family是一组Column的集合,包括Row,普通列族【普通Column】和超级列族【Super Column】
行Row
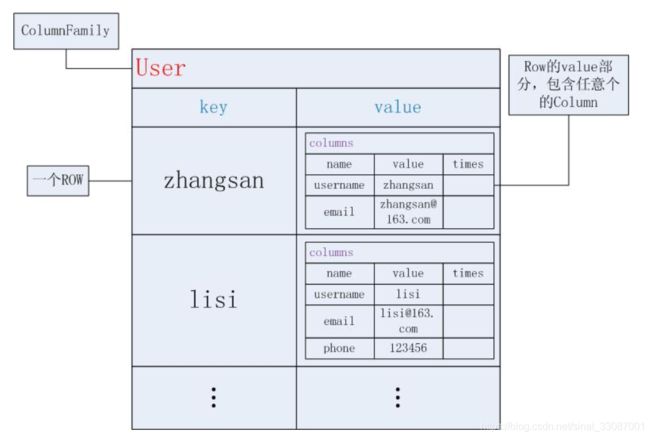
在cassandra里,每个ColumnFamily都存在一个单独的文件里,这个文件以Row为单位存储并排序。因此,我们应尽量将相关的Column放在同一个ColumnFamily里。与不是固定列族的模式的关系表不同,Cassandra不强制单个行拥有所有列,它可以拥有任意数量的列或超级列:ColumnFamily的组成是一行行的Row,一个Row就是一个key-value对,key决定数据将被存在哪台机器上,value部分就是Columns或SuperColumns

普通列族 Column Family
一个Column Family则是一系列Column的集合。在该集合中,每个Column都会有一个与之相关联的键:
User={//这是一个ColumnFamily,名字是User
zhangsan:{//这是一个Row,Row的key是zhangsan
//下面的value可以有无限制的Columns,这里有两个
username:"zhangsan",
email:"[email protected]",
},//这个Row结束了
lisi:{//这是第二个Row,Row的key是lisi
//value部分,依然是Columns,lisi有三个
username:"lisi",
email:"[email protected]",
phone:"123456"
},//Row结束
}
key决定本条Row存放在哪个机器上。
超级列族 Super Column Family
如果是任意数量的超极列,则结构如下,这种结构的考虑或许是为了将结构组织的更细粒度化,联合索引的处理机制好像也类似
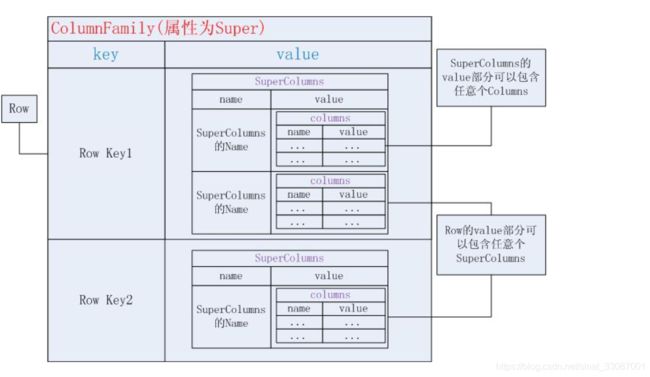
假设我们提供一种网上地址本的服务,用户可以在这保存他的朋友们的地址,而地址又是由不同的属性如邮编、街道、城市等组成。这时候我们可以采用SuperColumn。对于ColumnFamily,它的key使用的是用户自己的名字,value部分是若干SuperColumns。每个SuperColumns的name部分是用户某个朋友的名字,value部分是若干Columns,存储地址的各个属性
AddressBook={//这是一个SuperColumnFamily,名字是AddressBook
zhangsan:{//这是一个Row,key是zhangsan,张三的地址本
//下面是Row的Value部分,可以有任意个SuperColumns
lisi:{//这是SuperColumn的name
//下面是Columns,表示地址
street:"XiTuCheng road",
zip:"410083",
city:"BeiJing"
},
wangwu:{//另一个SuperColumn
street:"XiTuCheng road",
zip:"410083",
city:"BeiJing"
},
zhaoliu:{//SuperColumn
street:"XiTuCheng road",
zip:"410083",
city:"BeiJing"
},
.......
}//end the row of zhangsan
lisi:{//这是另一个Row,key是lisi,李四的地址本
wangwu:{//SuperColumn
street:"XiTuCheng road",
zip:"410083",
city:"BeiJing"
},
zhangsan:{//SuperColumn
street:"XiTuCheng road",
zip:"410083",
city:"BeiJing"
},
.......
}
}
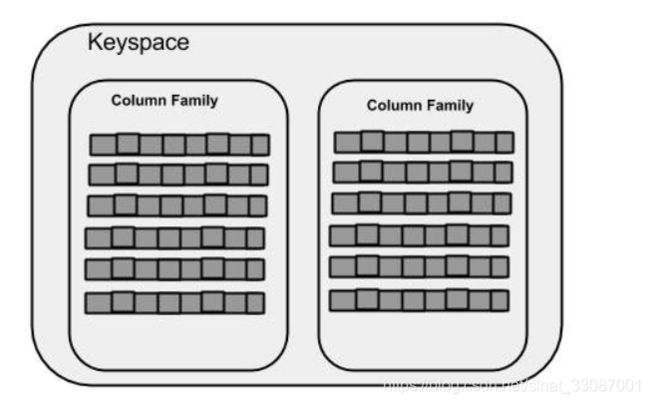
键空间Keyspace
键空间,KeySpace是最外层的容器,也是最大的容器,通常一个应用程序对应一个KeySpace。所有的ColumnFamily都位于一个KeySpace里面,它相当于关系数据库里的DB。
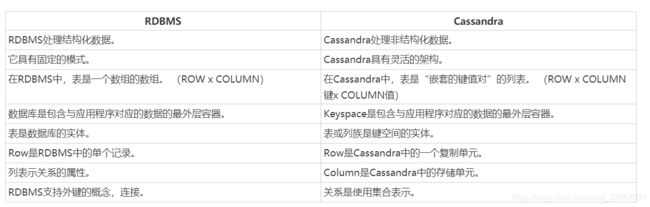
对比关系型数据库
关系型数据库和Cassandra的数据结构对比如下:
基本数据模型【行】
确定了列的相关属性后,其实还有一些行的内容,也就是我们知道Cassandra是基于列组织的,在抽象设计模型时,我们常常需要面对另外一个问题,那就是如何指定各Column Family所使用的各种键。在Cassandra相关的各类文档中,我们常常会遇到以下一系列关键的名词:Partition Key,Clustering Key,Primary Key以及Composite Key。那么它们指的都是什么呢?Primary Key实际上是一个非常通用的概念。在Cassandra中,其表示用来从Cassandra中取得数据的一个或多个列:
create table sample (
key text PRIMARY KEY,
data text
);
在上面的示例中,我们指定了key域作为sample的PRIMARY KEY。而在需要的情况下,一个Primary Key也可以由多个列共同组成:
create table sample {
key_one text,
key_two text,
data text,
PRIMARY KEY(key_one, key_two)
};
在上面的示例中,我们所创建的Primary Key就是一个由两个列key_one和key_two组成的Composite Key。其中该Composite Key的第一个组成被称为是Partition Key,而后面的各组成则被称为是Clustering Key。Partition Key用来决定Cassandra会使用集群中的哪个结点来记录该数据,每个Partition Key对应着一个特定的Partition。而Clustering Key则用来在Partition内部排序 。如果一个Primary Key只包含一个域,那么其将只拥有Partition Key而没有Clustering Key。Partition Key和Clustering Key同样也可以由多个列组成:
create table sample {
key_primary_one text,
key_primary_two text,
key_cluster_one text,
key_cluster_two text,
data text,
PRIMARY KEY((key_primary_one, key_primary_two), key_cluster_one, key_cluster_two)
};
而在一个CQL语句中,WHERE等子句所标示的条件只能使用在Primary Key中所使用的列。您需要根据您的数据分布决定到底哪些应该是Partition Key,哪些应该作为Clustering Key,以对其中的数据进行排序
数据排序
前面所介绍的是cassandra里各种数据容器的概念,现在来看看数据模型的另外一个关键地方即数据是如何排序的。cassandra和关系型数据库不同,你**无法在取出数据时指定一种排序(orderby)。数据在你存储到集群,被写入数据库时已经按照预定的规则被排好序。当你取出数据时,它们的顺序已经确定了**。cassandra是按照name而不是value进行排序。cassandra在写入数据的时候,每个row中的所有Columns会按照name自动排好序。排序的规则由ColumnFamily的CompareWith选项确定,可选的有:BytesType,UTF8Type,LexicalUUIDType,TimeUUIDType,AsciiType和LongType。这些选项将ColumnName看作不同的数据类型来排序,如LongType将它视为64bitLong类型。如下面给出的例子:
{name: 123, value: “hello there”},
{name: 832416, value: “kjjkbcjkcbbd”},
{name: 3, value: “101010101010″},
{name: 976, value: “kjjkbcjkcbbd”}
采用LongType排序类型,结果是:
{name: 3, value: “101010101010″},
{name: 123, value: “hello there”},
{name: 976, value: “kjjkbcjkcbbd”},
{name: 832416, value: “kjjkbcjkcbbd”}
总结
整体的数据结构和排序方式可以按照这个草图总结:
了解了数据模型之后下一篇了解内部机制