python用箱型图进行异常值检测
异常值检测:数据挖掘工作中的第一步就是异常值检测,异常值的存在会影响实验结果。异常值是指样本中的个别值,也称为离群点,其数值明显偏离其余的观测值。常用检测方法3σ原则和箱型图。其中,3σ原则只适用服从正态分布的数据。在3σ原则下,异常值被定义为观察值和平均值的偏差超过3倍标准差的值。P(|x−μ|>3σ)≤0.003,在正太分布假设下,大于3σ的值出现的概率小于0.003,属于小概率事件,故可认定其为异常值。
-
3σ原则对数据分布有一定限制,而箱型图并不限制数据分布,只是直观表现出数据分布的本来面貌。其识别异常值的结果比较客观,而且判断标准以四分位数和四分位间距为标准,多达25%的数据可以变得任意远而不会扰动这个标准,鲁棒性更强,所以更受大家亲睐。
-
箱型图识别异常值标准: 异常值被定义为大于QU+1.5IQR或小于QL−1.5IQR的值。QU是上四分位数,表示全部观察值中有1/4的数据比他大,QL是下四分位数,表示全部数据中有1/4的数据比他小。IQR是四分位间距,是QU和QL的差,其间包含了观察值的一半。
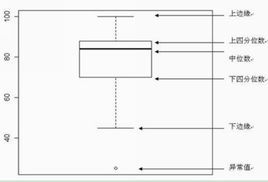
箱型图检测异常值实战:
对10位歌手近6个月的播放量数据集进行异常值检测. 数据集每一列表示歌手6个月的播放量,共10列.每一行表示每一天的播放量,共183天.
音乐播放量数据.
#-*- coding: utf-8 -*-
import pandas as pd
number = '../data/all_musicers.xlsx' #设定播放数据路径,该路径为代码所在路径的上一个目录data中.
data = pd.read_excel(number)
data1=data.iloc[:,0:10]#10位歌手的183天音乐播放量
#data2=data.iloc[:,10:20]
#data3=data.iloc[:,20:30]
#data4=data.iloc[:,30:40]
#data5=data.iloc[:,40:50]
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(1, figsize=(13, 26))#可设定图像大小
#plt.figure() #建立图像
p = data1.boxplot() #画箱线图,直接使用DataFrame的方法.代码到这为止,就已经可以显示带有异常值的箱型图了,但为了标注出异常值的数值,还需要以下代码进行标注.
#for i in range(0,4):
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签.[0]是用来标注第1位歌手的异常值数值,同理[i]标注第i+1位歌手的异常值.
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
若想同时在一张图上标注所有的歌手异常值的数值, 可以这样做:
x0 = p[‘fliers’][0].get_xdata() # ‘flies’即为异常值的标签.
y0= p[‘fliers’][0].get_ydata()
y0.sort() #从小到大排序
for i in range(len(x0)):
if i>0:
plt.annotate(y0[i], xy = (0x[i],y0[i]), xytext=(x0[i]+0.05 -0.8/(y0[i]-y0[i-1]),y0[i]))
else:
plt.annotate(y0[i], xy = (x0[i],y0[i]), xytext=(x0[i]+0.08,y0[i]))
上述代码将x0换成xi就表示给第i+1位歌手添加异常值标注. 在所有的歌手异常值都标注完后,执行plt.show() #展示所有异常值标注的箱型图.
- 1
输出结果如下:其中,+所表示的均是(统计学认为的)异常值.工作中,要结合数据应用背景, 距离箱型图上下界很近的可归为正常值. 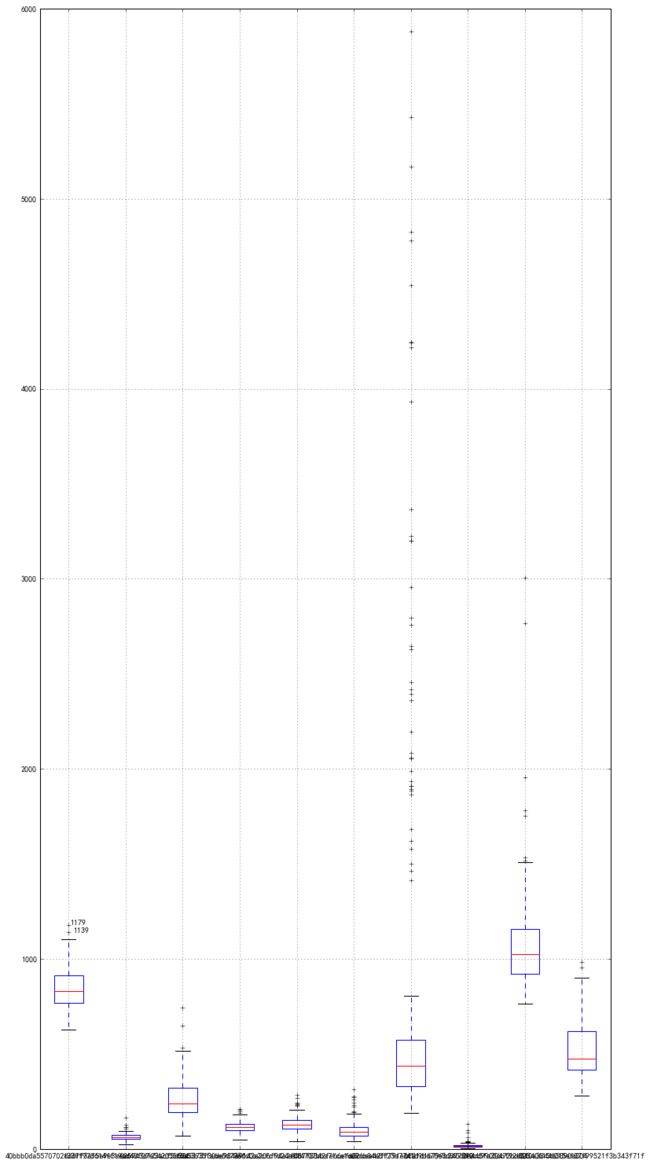
异常值处理:
- 删除:对于数据量比较小的数据,删除会造成样本不足,减少有用信息。
- 视为缺失值:用均值、插值等方法进行填补
- 不处理:将缺失值视为一种特征,统计其缺失个数等信息作为缺失特征。
本文将异常值视为缺失值,并用前后值的均值来填补.代码如下:
for i in range(0,182):
if data1.iloc[:,1][i]>125:
data1.iloc[:,1][i]=(data1.iloc[:,1][i+1]+data1.iloc[:,1][i-1])/2
for i in range(0,182):
if data1.iloc[:,2][i]>600:
data1.iloc[:,2][i]=(data1.iloc[:,2][i+1]+data1.iloc[:,1][i-1])/2
for i in range(0,182):
if data1.iloc[:,4][i]>225:
data1.iloc[:,4][i]=(data1.iloc[:,4][i+1]+data1.iloc[:,4][i-1])/2
for i in range(0,182):
if data1.iloc[:,7][i]>60:
data1.iloc[:,7][i]=(data1.iloc[:,7][i+1]+data1.iloc[:,7][i-1])/2
for i in range(0,182):
if data1.iloc[:,8][i]>2500:
data1.iloc[:,8][i]=(data1.iloc[:,8][i+1]+data1.iloc[:,8][i-1])/2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
处理完异常值后,导出数据,保存:
#datan=pd.concat([data1,data2,data3,data4,data5],axis=1)
data1.to_csv("train_innoraml.csv") - 1
- 2
保存时有时会出现这种问题:
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 0-1: ordinal not in range(128)
解决方法,输入以下代码: import sys
reload(sys)
sys.setdefaultencoding('utf-8')
转载自http://blog.csdn.net/shuaishuai3409/article/details/51428106