文本主题模型之LDA
什么是话题模型(topic model)?
话题模型就是用来发现大量文档集合的主题的算法。借助这些算法我们可以对文档集合进行归类。适用于大规模数据场景。目前甚至可以做到分析流数据。需要指出的是,话题模型不仅仅限于对文档的应用,可以应用在其他的应用场景中,例如基因数据、图像处理和社交网络。这是一种新的帮助人类组织、检索和理解信息的计算工具。
通过这类算法获得的那些主题都可以比喻成望远镜不同的放大倍数。我们可以根据特定的情形设置可以看到的关注对象的精度;并且可以研究主题随着时间变化产生的相关变化。这样的思考方式对于很多场景都是有效的,例如在搜索时,我们可以把单纯使用关键词的相关性推进到结合主题的结果整合从而给用户更好的使用体验。
Latent Dirichlet Allocation(LDA)
【总结】
LDA(Latent dirichlet allocation)[1]是有Blei于2003年提出的三层贝叶斯主题模型,通过无监督的学习方法发现文本中隐含的主题信息,目的是要以无指导学习的方法从文本中发现隐含的语义维度-即“Topic”或者“Concept”。隐性语义分析的实质是要利用文本中词项(term)的共现特征来发现文本的Topic结构,这种方法不需要任何关于文本的背景知识。文本的隐性语义表示可以对“一词多义”和“一义多词”的语言现象进行建模,这使得搜索引擎系统得到的搜索结果与用户的query在语义层次上match,而不是仅仅只是在词汇层次上出现交集。
这是最简单的话题模型。LDA的直觉上认为文档有多个话题生成。这个过程也是LDA给出的文档生成过程。
LDA生成过程:
所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
首先我们所做的事情都在词典的限定下,就是文档中出现的词都不会超出词典给出的范围。比如说,话题“基因”中以很高的概率包含若干关于基因的词,而话题“进化生物学”则会以很高概率包含进化生物学的相关词。我们假设这些话题在数据产生前已经确定了。现在在文档集合中的每个文档,我们来生成其中的文字。步骤如下:
- 随机选择话题之上的分布
- 对文档中的每个词
2.1 从步骤1中产生的分布中随机选择一个话题
2.2 从词典上的对应分布中随机选择一个词
这个统计模型反应出文档拥有不同比例的话题(步骤1);每个文档中的每个词都是从众多话题之一中抽取出来的(步骤2.2),而被选择的话题是从针对每个文档的话题上的分布中产生的(步骤2.1)
简单理解这个生成过程:
在LDA中,所有的文档共有同样的话题集,但是每个文档以不同的比例展示对应的话题。LDA的主要目标是自动发现一个文档集合中的话题。这些文档本身是可以观测到的,而话题的结构——话题、每个文档的话题分布和每个文档的每个词的话题赋值——是隐藏的(可称为hidden structure)。话题建模的核心计算问题就是使用观测到的文档来推断隐藏话题结构。这也可以看作是生成(generative)过程的逆过程——什么样的隐藏结构可以产生观测到的文档集合?
借助LDA算法可以得到话题的结构,需要指出的是,算法本身并不需要用到这些话题的信息,文档本身也没有使用话题或者关键字进行标注。这个隐藏结构最有可能产生现在可以观测到的文档集合。
话题模型方便的地方就是可以通过推断的隐藏结构来组成文档的主题结构。这样的信息对于信息检索,分类和语料研究提供了有力的支撑。所以可以这样说,话题模型给出了一种管理、组织和标注文本的大量集合的算法解答。
LDA的定义和分析
LDA和其他一些话题模型从属于概率建模领域之下。生成概率建模中,我们的数据可以从一个包含了隐藏变量的生成过程中得到。这个生成过程定义了一个在已观测随机变量和隐藏随机变量之上的联合概率分布。我们通过使用联合概率分布来计算给定观测变量值下的隐藏变量的条件分布。这种条件分布也被叫做后验分布。
LDA正好属于这个框架。已观测的变量就是那些文档中的词;隐藏变量就是话题模型;生成过程就是前面我们介绍的。而从文档来推断隐藏话题结构的问题就变成了计算后验分布的问题——计算给定文档后隐藏变量的条件分布。
现在我们可以形式化地描述LDA,话题 (Topics)是\beta_{1:K},其中每个\beta_k是在词典上的分布。第d个文档的话题比例(Per-document topic proportions)是\theta_d,其中\theta_{d,k}是话题k在文档d中的比例。对第d个文档的话题赋值 (Per-word topic assignment) 就是z_d,其中z_{d,n}是第d个文档的第n个词的话题赋值。最后,文档d观测到的词 (Observed word) 是w_d,其中w_{d,n}是在文档d中的第n个词,它是来自于我们给定的词典的。
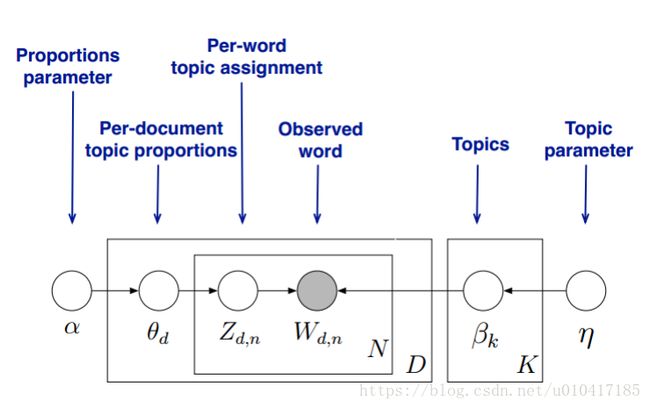
LDA参数:
K为主题个数,M为文档总数, 是第m个文档的单词总数。
是第m个文档的单词总数。 是每个Topic下词的多项分布的Dirichlet先验参数,
是每个Topic下词的多项分布的Dirichlet先验参数,  是每个文档下Topic的多项分布的Dirichlet先验参数。
是每个文档下Topic的多项分布的Dirichlet先验参数。 是第m个文档中第n个词的主题,
是第m个文档中第n个词的主题, 是m个文档中的第n个词。剩下来的两个隐含变量
是m个文档中的第n个词。剩下来的两个隐含变量 和
和 分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)。
分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)。
使用这个表示方法,LDA生成过程对应于下面的隐藏变量和观测变量的联合分布:
p(\beta_{1:K},\theta_{1:D},z_{1:D},w_{1:D})
= \prod_{i=i}^k p(\beta_i) \prod_{d=1}^D p(\theta_d) (\prod_{n=1}^N p(z_{d,n}|\theta_d)p(w_{d,n}|\beta_{1:K},z_{d,n}))这个分布给出一些依赖关系。例如,话题赋值z_{d,n}依赖于对每个文档的话题比例\theta_d和所有的话题\beta_{1:K}(从实施角度上看,这个项首先通过确定其代表的话题z_{d,n}而后在那个话题中查询w_{d,n}相应的概率)
正是这样依赖关系定义了LDA。他们由生成过程背后的统计假设给出,以一种联合分布的数学形式和针对LDA的概率图模型的方式确定了这些依赖关系。概率图模型提供了一个图形化的语言来描述概率分布的家族(family)。这些表示方法都可以描述LDA背后的概率假设。
后面我们会介绍一下LDA的推断算法。这里顺便提一下pLSI(probabilistic latent semantic analysis)。这个模型本身是LSA的概率版本,它揭示了SVD在文档-项矩阵上的作用。从矩阵分解的角度看,LDA同样可以看作是对于离散数据的PCA。
LDA的后验分布计算
现在就开始介绍LDA的后验分布的计算,也就是在给定观测文档下计算话题结构的条件分布。(这就是传说中的后验分布posterior)
其定义如下:
p(\beta_{1:K},\theta_{1:D},z_{1:D}|w_{1:D})
= p(\beta_{1:K},\theta_{1:D},z_{1:D}, w_{1:D}) / p(w_{1:D})当然了,可能的话题结构是指数级大的,这个问题难解的(NP-hard)。正如很多现代概率模型那样,因为分母难以计算就使得我们很难计算出后验。所以现代概率模型研究的焦点之一就是设计出高效的近似方法。话题模型算法通常是通用近似后验分布方法的适配使用。
话题模型算法通过适配一种隐藏话题结构的分布来接近最终正确的后验。而主要的话题建模算法可以分成两种——基于采样的算法和变分算法。
基于采样的算法尝试从后验分布中搜集样本使用一个经验分布来近似它。最常用的采样算法是Markov chain——一个随机变量的序列,每个变量只依赖于前一个,其极限分布是我们需要的后验分布。Markov chain定义在对一个特定的语料的隐藏话题变量上,算法思想就是运行chain很长一段时间,从极限分布中搜集样本,接着使用搜集来的样本来近似分布。(常常,仅仅是一个有着最大概率的样本被搜集来作为近似的话题结构)。
变分方法是一个确定性的方式。变分方法没有去使用样本来近似后验,而是采用了一个在隐藏结构上的参数化的分布家族,接着找到家族中最靠近后验的那个成员。因此,推断问题就被转化为一个优化问题了。变分方法打开了一扇通向实用的概率建模的创新大门。
See Blei et al.8 for a coordinate ascent variational inference algorithm for LDA; see Hoffman et al.20 for a much faster online algorithm (and open-source software) that easily handles millions of documents and can accommodate streaming collections of text.
不严格地说,两种类型的算法都是在话题结构上的一种搜索。文档集合(模型中的观测到的随机变量)是确定的,并当作是一个搜索方向的指导。方法的优劣取决于所使用的特定的话题模型——除了我们前面一直讨论的LDA,还有其他的话题模型——这也是学术争论之源。
#-*- coding:utf-8 -*-
import logging
import logging.config
import ConfigParser
import numpy as np
import random
import codecs
import os
from collections import OrderedDict
#获取当前路径
path = os.getcwd()
#导入日志配置文件
logging.config.fileConfig("logging.conf")
#创建日志对象
logger = logging.getLogger()
# loggerInfo = logging.getLogger("TimeInfoLogger")
# Consolelogger = logging.getLogger("ConsoleLogger")
#导入配置文件
conf = ConfigParser.ConfigParser()
conf.read("setting.conf")
#文件路径
trainfile = os.path.join(path,os.path.normpath(conf.get("filepath", "trainfile")))
wordidmapfile = os.path.join(path,os.path.normpath(conf.get("filepath","wordidmapfile")))
thetafile = os.path.join(path,os.path.normpath(conf.get("filepath","thetafile")))
phifile = os.path.join(path,os.path.normpath(conf.get("filepath","phifile")))
paramfile = os.path.join(path,os.path.normpath(conf.get("filepath","paramfile")))
topNfile = os.path.join(path,os.path.normpath(conf.get("filepath","topNfile")))
tassginfile = os.path.join(path,os.path.normpath(conf.get("filepath","tassginfile")))
#模型初始参数
K = int(conf.get("model_args","K"))
alpha = float(conf.get("model_args","alpha"))
beta = float(conf.get("model_args","beta"))
iter_times = int(conf.get("model_args","iter_times"))
top_words_num = int(conf.get("model_args","top_words_num"))
class Document(object):
def __init__(self):
self.words = []
self.length = 0
#把整个文档及真的单词构成vocabulary(不允许重复)
class DataPreProcessing(object):
def __init__(self):
self.docs_count = 0
self.words_count = 0
#保存每个文档d的信息(单词序列,以及length)
self.docs = []
#建立vocabulary表,照片文档的单词
self.word2id = OrderedDict()
def cachewordidmap(self):
with codecs.open(wordidmapfile, 'w','utf-8') as f:
for word,id in self.word2id.items():
f.write(word +"\t"+str(id)+"\n")
class LDAModel(object):
def __init__(self,dpre):
self.dpre = dpre #获取预处理参数
#
#模型参数
#聚类个数K,迭代次数iter_times,每个类特征词个数top_words_num,超参数α(alpha) β(beta)
#
self.K = K
self.beta = beta
self.alpha = alpha
self.iter_times = iter_times
self.top_words_num = top_words_num
#
#文件变量
#分好词的文件trainfile
#词对应id文件wordidmapfile
#文章-主题分布文件thetafile
#词-主题分布文件phifile
#每个主题topN词文件topNfile
#最后分派结果文件tassginfile
#模型训练选择的参数文件paramfile
#
self.wordidmapfile = wordidmapfile
self.trainfile = trainfile
self.thetafile = thetafile
self.phifile = phifile
self.topNfile = topNfile
self.tassginfile = tassginfile
self.paramfile = paramfile
# p,概率向量 double类型,存储采样的临时变量
# nw,词word在主题topic上的分布
# nwsum,每各topic的词的总数
# nd,每个doc中各个topic的词的总数
# ndsum,每各doc中词的总数
self.p = np.zeros(self.K)
# nw,词word在主题topic上的分布
self.nw = np.zeros((self.dpre.words_count,self.K),dtype="int")
# nwsum,每各topic的词的总数
self.nwsum = np.zeros(self.K,dtype="int")
# nd,每个doc中各个topic的词的总数
self.nd = np.zeros((self.dpre.docs_count,self.K),dtype="int")
# ndsum,每各doc中词的总数
self.ndsum = np.zeros(dpre.docs_count,dtype="int")
self.Z = np.array([ [0 for y in xrange(dpre.docs[x].length)] for x in xrange(dpre.docs_count)]) # M*doc.size(),文档中词的主题分布
#随机先分配类型,为每个文档中的各个单词分配主题
for x in xrange(len(self.Z)):
self.ndsum[x] = self.dpre.docs[x].length
for y in xrange(self.dpre.docs[x].length):
topic = random.randint(0,self.K-1)#随机取一个主题
self.Z[x][y] = topic#文档中词的主题分布
self.nw[self.dpre.docs[x].words[y]][topic] += 1
self.nd[x][topic] += 1
self.nwsum[topic] += 1
self.theta = np.array([ [0.0 for y in xrange(self.K)] for x in xrange(self.dpre.docs_count) ])
self.phi = np.array([ [ 0.0 for y in xrange(self.dpre.words_count) ] for x in xrange(self.K)])
def sampling(self,i,j):
#换主题
topic = self.Z[i][j]
#只是单词的编号,都是从0开始word就是等于j
word = self.dpre.docs[i].words[j]
#if word==j:
# print 'true'
self.nw[word][topic] -= 1
self.nd[i][topic] -= 1
self.nwsum[topic] -= 1
self.ndsum[i] -= 1
Vbeta = self.dpre.words_count * self.beta
Kalpha = self.K * self.alpha
self.p = (self.nw[word] + self.beta)/(self.nwsum + Vbeta) * \
(self.nd[i] + self.alpha) / (self.ndsum[i] + Kalpha)
#随机更新主题的吗
# for k in xrange(1,self.K):
# self.p[k] += self.p[k-1]
# u = random.uniform(0,self.p[self.K-1])
# for topic in xrange(self.K):
# if self.p[topic]>u:
# break
#按这个更新主题更好理解,这个效果还不错
p = np.squeeze(np.asarray(self.p/np.sum(self.p)))
topic = np.argmax(np.random.multinomial(1, p))
self.nw[word][topic] +=1
self.nwsum[topic] +=1
self.nd[i][topic] +=1
self.ndsum[i] +=1
return topic
def est(self):
# Consolelogger.info(u"迭代次数为%s 次" % self.iter_times)
for x in xrange(self.iter_times):
for i in xrange(self.dpre.docs_count):
for j in xrange(self.dpre.docs[i].length):
topic = self.sampling(i,j)
self.Z[i][j] = topic
logger.info(u"迭代完成。")
logger.debug(u"计算文章-主题分布")
self._theta()
logger.debug(u"计算词-主题分布")
self._phi()
logger.debug(u"保存模型")
self.save()
def _theta(self):
for i in xrange(self.dpre.docs_count):#遍历文档的个数词
self.theta[i] = (self.nd[i]+self.alpha)/(self.ndsum[i]+self.K * self.alpha)
def _phi(self):
for i in xrange(self.K):
self.phi[i] = (self.nw.T[i] + self.beta)/(self.nwsum[i]+self.dpre.words_count * self.beta)
def save(self):
# 保存theta文章-主题分布
logger.info(u"文章-主题分布已保存到%s" % self.thetafile)
with codecs.open(self.thetafile,'w') as f:
for x in xrange(self.dpre.docs_count):
for y in xrange(self.K):
f.write(str(self.theta[x][y]) + '\t')
f.write('\n')
# 保存phi词-主题分布
logger.info(u"词-主题分布已保存到%s" % self.phifile)
with codecs.open(self.phifile,'w') as f:
for x in xrange(self.K):
for y in xrange(self.dpre.words_count):
f.write(str(self.phi[x][y]) + '\t')
f.write('\n')
# 保存参数设置
logger.info(u"参数设置已保存到%s" % self.paramfile)
with codecs.open(self.paramfile,'w','utf-8') as f:
f.write('K=' + str(self.K) + '\n')
f.write('alpha=' + str(self.alpha) + '\n')
f.write('beta=' + str(self.beta) + '\n')
f.write(u'迭代次数 iter_times=' + str(self.iter_times) + '\n')
f.write(u'每个类的高频词显示个数 top_words_num=' + str(self.top_words_num) + '\n')
# 保存每个主题topic的词
logger.info(u"主题topN词已保存到%s" % self.topNfile)
with codecs.open(self.topNfile,'w','utf-8') as f:
self.top_words_num = min(self.top_words_num,self.dpre.words_count)
for x in xrange(self.K):
f.write(u'第' + str(x) + u'类:' + '\n')
twords = []
twords = [(n,self.phi[x][n]) for n in xrange(self.dpre.words_count)]
twords.sort(key = lambda i:i[1], reverse= True)
for y in xrange(self.top_words_num):
word = OrderedDict({value:key for key, value in self.dpre.word2id.items()})[twords[y][0]]
f.write('\t'*2+ word +'\t' + str(twords[y][1])+ '\n')
# 保存最后退出时,文章的词分派的主题的结果
logger.info(u"文章-词-主题分派结果已保存到%s" % self.tassginfile)
with codecs.open(self.tassginfile,'w') as f:
for x in xrange(self.dpre.docs_count):
for y in xrange(self.dpre.docs[x].length):
f.write(str(self.dpre.docs[x].words[y])+':'+str(self.Z[x][y])+ '\t')
f.write('\n')
logger.info(u"模型训练完成。")
# 数据预处理,即:生成d()单词序列,以及词汇表
def preprocessing():
logger.info(u'载入数据......')
with codecs.open(trainfile, 'r','utf-8') as f:
docs = f.readlines()
logger.debug(u"载入完成,准备生成字典对象和统计文本数据...")
# 大的文档集
dpre = DataPreProcessing()
items_idx = 0
for line in docs:
if line != "":
tmp = line.strip().split()
# 生成一个文档对象:包含单词序列(w1,w2,w3,,,,,wn)可以重复的
doc = Document()
for item in tmp:
if dpre.word2id.has_key(item):# 已有的话,只是当前文档追加
doc.words.append(dpre.word2id[item])
else: # 没有的话,要更新vocabulary中的单词词典及wordidmap
dpre.word2id[item] = items_idx
doc.words.append(items_idx)
items_idx += 1
doc.length = len(tmp)
dpre.docs.append(doc)
else:
pass
dpre.docs_count = len(dpre.docs) # 文档数
dpre.words_count = len(dpre.word2id) # 词汇数
logger.info(u"共有%s个文档" % dpre.docs_count)
dpre.cachewordidmap()
logger.info(u"词与序号对应关系已保存到%s" % wordidmapfile)
return dpre
def run():
# 处理文档集,及计算文档数,以及vocabulary词的总个数,以及每个文档的单词序列
dpre = preprocessing()
lda = LDAModel(dpre)
lda.est()
if __name__ == '__main__':
run()