数据库基础知识
一边复习一边把重要的内容摘出来以便自己查找~不是很全,只涉及基础操作
SQL层流程:
MySQL语句SQL层流程:SQL语句-缓存查询-解析器-优化器-执行器
查询缓存:如果查询缓存中有这条SQL语句则直接将结果返回客户端,没有就进入解析器。8.0以后没有
解析器:进行语法分析(拼写是否正确,语法错误)、语义分析(访问对象是否存在,比如列名错误)。
优化器:确定SQL语句执行路径(全表检索/索引检索等)
执行器:判断用户是否具有权限,具有权限则根据索引检索并返回结果。
存储引擎 InnoDB MylSAM
InnoDB:5.5以后默认,支持事务、行级锁定、外键约束等
MylSAM:5.5以前,不支持事务和外键,速度快、占用资源少。
数据库的设计在于表的设计,MySQL可以每个表采用不同存储引擎,根据实际数据处理需要来选择引擎、
PROFILE
分析语句性能时采用profile(官方建议 Performance Schema),里面记录所有的查询和错误语句,会话结束则丢失profile信息。
查看执行语句的时间:
mysql>select @@profiling;
mysql> set profiling=1;
mysql> select * from xxx;
mysql> show profiles;#查看会话产生的所有profiles 如果show profile则打开最近的profile
约束:
主键约束:唯一标识一条记录,不能重复不能为空,UNIQUE NOT NULL。一个表的主键只能有一个,可以是一个字段,也可以是多个字段复合组成。
外键约束:一个表中的外键,对应另一个表的主键。外键可以重复可以为空,主要是保证了表与表之间引用的完整性。
- 外键为了实现强一致性,如果正确性>性能,建议使用外键保证数据的完整性和一致性。
- 高并发的情况外键会造成额外的开销,也容易造成死锁。
- 可以通过业务层来进行实现外键,但业务逻辑和数据必须同时修改。
唯一性约束:表明字段在表中的数值是唯一的。唯一性约束相当于创建了一个约束和普通索引,目的是保证字段的正确性。索引的目的是提升数据检索速度。
NOT NULL约束:该字段不能为空,必须有取值
DEFAULT约束:默认值,如果没有插入值则采用默认值。
CHECK约束:检查特定字段取值范围的有效性,如CHECK(height>=0 AND height<3)
设计数据表的原则
数据表个数越少越好
数据表字段个数越少越好(前提各字段相互独立)
数据表中联合主键的字段个数越少越好(联合主键字段多,索引空间和运行时间大)
通过主键和外键的使用来增强数据表之间的复用率。
SELECT
查询某一列列名/SELECT * 查询所有/可以查询某个常量来增加列字段 SELECT 'AAA' AS name, id FROM table
DISTINCT需要放在所有列名前,实际是对列名组合进行去重,不能单独在一个列的前面
ORDER BY:可以多列排序(可以包含非选择列),DESC表示递减,ASC默认递增,文本类需要参考数据库字段的属性
LIMIT:约束返回结果数量,可以提高查询效率
关键字顺序:SELECT...FROM...WHERE...GROUP BY ...HAVING...ORDER BY ...LIMIT
执行顺序:FROM组装数据>WHERE>GROUP BY>聚集函数计算>HAVING>计算表达式>SELECT>DISTINCT>ORDER BY>LIMIT
SELECT(*)的效率比较低,如果能选择列或限制返回行数则可以提高效率。
COUNT是个特例:统计行数时COUNT(*)=COUNT(1)>COUNT(字段)
WHERE
()优先级>AND优先级>OR优先级
通配符区别大小写,%一个或多个,_只代表一个,尽量少用通配符因为消费数据库更长的时间来匹配,如果想让索引生效,不能LIKE直接加通配符%,这样会进行全表扫描。
常用SQL函数
一般WHERE中不用条件函数,会导致查询不走索引全表遍历,导致慢查询。
算数函数:ABS()取绝对值 MOD()取余 ROUND()四舍五入取小数,包含字段名称和小数位数
字符串函数:
- CONCAT多个字段拼接,
- LENGTH字段长度(汉字3字符,一个数字/字母 一个字符),CHAR_LENGTH 数字字母汉字都是一个字符
- LOWER、UPPER 大小写转换
- REPLACE()替换函数,要替换的表达式或字段名、要查找的被替换字符串、替换成哪个字符串
- SUBSTRING()截断字符串,3个参数:待截断的表达式或字段名,开始截取的位置,截取长度
日期函数
如果进行日期比较需要DATE函数,不要直接日期列字段和字符串比较,因为不能确定该列是字符串还是datetime类型
日期的标准写法是:'xxxx-xx-xx'
e.g. WHERE time>'2015-01-01' 不安全 应为: WHERE DATE(time)>'2015-01-01'
- CURRENT_DATE()系统当前的日期
- CURRENT_TIME()系统当前的时间(无日期)
- CURRENT_TIMESTAMP()系统当前的日期+时间
- EXTRACT()抽取具体的年月日 e.g. SELECT EXTRACT(YEAR FROM ‘2020-02-16’)
- DATE()返回时间的日期部分 e.g. SELECT DATE('2019-04-01 12:00:05')
- YEAR() MONTH() DAY() HOUR() MINUTE() SECOND()返回时间的某一部分
转换函数
CAST()数据类型转换,原始数据和目标数据
e.g. SELECT CAST(123.123 AS DECIMAL(8,2)) 运行结果123.12
DECIMAL(a,b) a是整数和小数加起来最多的位数,b表示小数位数
COALESCE()返回第一个非空数值
大小写规范:
MySQL在Linux环境下,数据库名、表名、变量名严格区分大小写,字段名忽略大小写
MySQL在Windows环境下全部不区分大小写。
规范建议:关键字和函数名大写,数据库名、表名、字段名小写,SQL语句以分号结尾
聚集函数:
COUNT MAX MIN SUM AVG
AVG MAX MIN会自动忽略NULL的行,MAX MIN可以对字符串使用。
对于中文字符串可以先转换成gbk再进行比较,e.g. MIN(CONVERT(name USING gbk))
COUNT(字段名)会忽略值为NULL的数据行,而COUNT(*)计数包括NULL行
聚集函数可以和DISTINCT一起使用,AVG(DISTINCT num) 对不同num值的数据聚集
HAVING
HAVING对分组过滤,WHERE对数据行过滤
子查询:
非关联子查询:子查询执行一次从数据表中查询到数据结果,将结果作为主查询的条件进行执行。
关联子查询:子查询中的表用到了外部的表,进行了条件关联。需要执行多次,将内部查询结果反馈给外部。
SELECT * FROM A WHERE cc IN (SELECT cc FROM B) A表比B大,如果B中cc有索引则IN更快
SELECT * FROM A WHERE EXIST(SELECT cc FROM WHERE B.cc=A.cc) A表比B小,EXISTS效率更高
IN是外表和内表进行HASH连接,先执行子查询,但IN不能判断NULL,而且IN只能跟一个列名,外表大用IN
EXISTS是对外表进行循环,然后再内表进行循环,可以判断NULL,外表小用EXISTS
ANY(SOME)和ALL都必须和比较操作符一起用,ANY表示任一,ALL表示所有
SQL92:
笛卡尔积:SELECT * FROM table1,table2 返回table1行数*table2行数
等值连接:用两张表中都存在的列进行连接(等号),如果使用了表别名在查询字段只能用表别名,不能用原表名。
非等值连接:连接多个表的条件是等号以外的其他的运算符。
LEFT JOIN 和RIGHT JOIN存在SQL99以后
自连接:查询条件使用了当前的表的字段
SQL99(可读性比92更强):
NATURAL JOIN:自然连接,自动连接表中相同的字段,进行等值连接,不需要WHERE的条件
ON:JOIN进行连接,ON指定连接条件
JOIN USING连接: A JOIN B USING(l两个表中相同的列名)可以简化JOIN ON
外连接:LEFT JOIN左外连接,RIGHT JOIN右外连接,FULL JOIN全外连接。(LEFT OUTER JOIN 一回事儿,省略OUTER)
MySQL不支持全外连接
连接的性能:
空值连接表的数量,多表连接降低SQL查询性能,不要连接不必要的表
连接时可以用WHERE语句过滤掉不必要的数据行返回
使用自连接的速度比使用子查询要快
视图 VIEW
安全性:基于底层数据表的虚拟表,可以限制对底层数据的修改,设定不同的数据查询权限。可以保证数据表的数据安全。
简单:视图是对SQL查询的封装,将原本复杂的SQL查询简化,方便重用而不必知道细节。
跳过了总结存储和管理事务这两部分,知识点有点多T T
隔离
脏读、幻读、不可重复读
脏读:读到了其他事务还没有提交的数据
不可重复读:对某数据进行提取,两次读取结果不同,是因为有其他的事务对这个数据同时进行了修改或者删除。
幻读:事务A根据条件查询得到了N条数据,事务B更改或增加了M条符合A查询条件的数据。事务A再次查询发现N+M条数据。
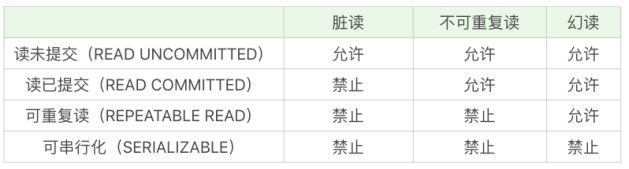
可串行化是最高级别的隔离等级,可以解决事务读取中所有可能出现的异常,但它牺牲了系统的并发性。隔离级别越低,意味系统并发程度越大,更可能出现异常情况。