from tensorflow.keras.datasets import cifar10
import numpy as np
np.random.seed(10)
(x_img_train, y_label_train), (x_img_test, y_label_test) = cifar10.load_data()
len(x_img_train)
50000
len(x_img_test)
10000
x_img_train.shape
(50000, 32, 32, 3)
x_img_test[0]
array([[[158, 112, 49],
[159, 111, 47],
[165, 116, 51],
...,
[137, 95, 36],
[126, 91, 36],
[116, 85, 33]],
[[152, 112, 51],
[151, 110, 40],
[159, 114, 45],
...,
[136, 95, 31],
[125, 91, 32],
[119, 88, 34]],
[[151, 110, 47],
[151, 109, 33],
[158, 111, 36],
...,
[139, 98, 34],
[130, 95, 34],
[120, 89, 33]],
...,
[[ 68, 124, 177],
[ 42, 100, 148],
[ 31, 88, 137],
...,
[ 38, 97, 146],
[ 13, 64, 108],
[ 40, 85, 127]],
[[ 61, 116, 168],
[ 49, 102, 148],
[ 35, 85, 132],
...,
[ 26, 82, 130],
[ 29, 82, 126],
[ 20, 64, 107]],
[[ 54, 107, 160],
[ 56, 105, 149],
[ 45, 89, 132],
...,
[ 24, 77, 124],
[ 34, 84, 129],
[ 21, 67, 110]]], dtype=uint8)
label_dict = {
0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck'
}
import matplotlib.pyplot as plt
def show_images_labels_prediction(images, labels, prediction, idx, num=10):
fig = plt.gcf()
fig.set_size_inches(12, 14)
if num > 25: num = 25
for i in range(0, num):
ax = plt.subplot(5, 5, i + 1)
ax.imshow(images[idx], cmap='binary')
title = str(i) + 'label_dict[labels[i][0]]'
if len(prediction) > 0:
title += ',label_dict[prediction[i]]'
ax.set_title(title, fontsize=10)
ax.set_xticks([])
ax.set_yticks([])
idx += 1
plt.show()
show_images_labels_prediction(x_img_train, y_label_train, [], 0)

x_img_train[0][0][0]
array([59, 62, 63], dtype=uint8)
x_img_train_normalize = x_img_train.astype('float32') / 255
x_img_test_normalize = x_img_test.astype('float32') / 255
x_img_train_normalize[0][0][0]
array([0.23137255, 0.24313726, 0.24705882], dtype=float32)
y_label_train.shape
(50000, 1)
y_label_train[:5]
array([[6],
[9],
[9],
[4],
[1]], dtype=uint8)
from tensorflow.keras.utils import to_categorical
y_label_train_Onehot = np_utils.to_categorical(y_label_train)
y_label_test_Onehot = np_utils.to_categorical(y_label_test)
y_label_train_Onehot.shape
(50000, 10)
y_label_train_Onehot[:5]
array([[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]], dtype=float32)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Activation, Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPool2D, ZeroPadding2D
model = Sequential()
model.add(
Conv2D(filters=32,
kernel_size=(3, 3),
input_shape=(32, 32, 3),
activation='relu',
padding='same'))
model.add(Dropout(0.25))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(
Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(Dropout(0.25))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dropout(0.25))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(rate=0.25))
model.add(Dense(10, activation='softmax'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
dropout_9 (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 16, 16, 64) 18496
_________________________________________________________________
dropout_10 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 8, 8, 64) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 4096) 0
_________________________________________________________________
dropout_11 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_5 (Dense) (None, 1024) 4195328
_________________________________________________________________
dropout_12 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_6 (Dense) (None, 10) 10250
=================================================================
Total params: 4,224,970
Trainable params: 4,224,970
Non-trainable params: 0
_________________________________________________________________
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history = model.fit(x_img_train_normalize,
y_label_train_Onehot,
validation_split=0.2,
epochs=10,
batch_size=128,
verbose=1)
W0815 14:02:18.266812 3476 deprecation.py:323] From E:\Anaconda3\envs\ml\lib\site-packages\tensorflow\python\ops\math_grad.py:1250: add_dispatch_support..wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
40000/40000 [==============================] - 80s 2ms/step - loss: 1.4861 - acc: 0.4651 - val_loss: 1.2726 - val_acc: 0.5727
Epoch 2/10
40000/40000 [==============================] - 78s 2ms/step - loss: 1.1343 - acc: 0.5957 - val_loss: 1.1271 - val_acc: 0.6321
Epoch 3/10
40000/40000 [==============================] - 78s 2ms/step - loss: 0.9794 - acc: 0.6547 - val_loss: 1.0180 - val_acc: 0.6591
Epoch 4/10
40000/40000 [==============================] - 79s 2ms/step - loss: 0.8696 - acc: 0.6945 - val_loss: 0.9446 - val_acc: 0.6983
Epoch 5/10
40000/40000 [==============================] - 79s 2ms/step - loss: 0.7815 - acc: 0.7254 - val_loss: 0.8846 - val_acc: 0.6979
Epoch 6/10
40000/40000 [==============================] - 79s 2ms/step - loss: 0.6987 - acc: 0.7541 - val_loss: 0.8430 - val_acc: 0.7234
Epoch 7/10
40000/40000 [==============================] - 80s 2ms/step - loss: 0.6221 - acc: 0.7812 - val_loss: 0.8249 - val_acc: 0.7241
Epoch 8/10
40000/40000 [==============================] - 78s 2ms/step - loss: 0.5540 - acc: 0.8058 - val_loss: 0.7874 - val_acc: 0.7359
Epoch 9/10
40000/40000 [==============================] - 79s 2ms/step - loss: 0.4923 - acc: 0.8278 - val_loss: 0.7541 - val_acc: 0.7458
Epoch 10/10
40000/40000 [==============================] - 78s 2ms/step - loss: 0.4360 - acc: 0.8477 - val_loss: 0.7844 - val_acc: 0.7289
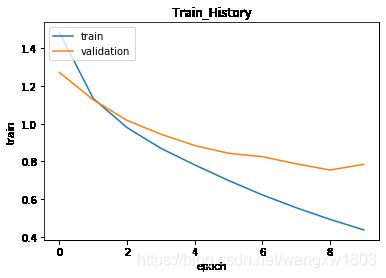
def show_train_hitory(train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train_History')
plt.ylabel('train')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_hitory('acc', 'val_acc')

show_train_hitory('loss', 'val_loss')
scores = model.evaluate(x_img_test_normalize, y_label_test_Onehot, verbose=0)
scores[1]
0.7243
prediction = model.predict_classes(x_img_test_normalize)
prediction[:10]
array([3, 8, 8, 0, 6, 6, 1, 6, 3, 1], dtype=int64)
show_images_labels_prediction(x_img_test, y_label_test, prediction, 0, 10)

predicted_Probability = model.predict(x_img_test_normalize)
def show_Predicted_Probability(y, prediction, x_img, Predicted_Probability, i):
print('label:', label_dict[y[i][0]], 'predict', label_dict[prediction[i]])
plt.figure(figsize=(2, 2))
plt.imshow(np.reshape(x_img_test[i], (32, 32, 3)))
plt.show()
for j in range(10):
print(label_dict[j] + 'Probability: % 1.9f' %
(Predicted_Probability[i][j]))
show_Predicted_Probability(y_label_test, prediction, x_img_test,
predicted_Probability, 0)
label: cat predict cat

airplaneProbability: 0.006167101
automobileProbability: 0.001565425
birdProbability: 0.044187795
catProbability: 0.715321243
deerProbability: 0.014729370
dogProbability: 0.098865360
frogProbability: 0.068471827
horseProbability: 0.006407721
shipProbability: 0.043457642
truckProbability: 0.000826489
show_Predicted_Probability(y_label_test, prediction, x_img_test,
predicted_Probability, 3)
label: airplane predict airplane

airplaneProbability: 0.840534329
automobileProbability: 0.001597346
birdProbability: 0.083605878
catProbability: 0.000940685
deerProbability: 0.008222473
dogProbability: 0.000034206
frogProbability: 0.000021479
horseProbability: 0.000218752
shipProbability: 0.064438224
truckProbability: 0.000386720
import pandas as pd
pd.crosstab(y_label_test.reshape(-1),
prediction,
rownames=['label'],
colnames=['predict'])
E:\Anaconda3\envs\ml\lib\importlib\_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
return f(*args, **kwds)
| predict |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| label |
|
|
|
|
|
|
|
|
|
|
| 0 |
791 |
6 |
85 |
8 |
28 |
3 |
15 |
6 |
46 |
12 |
| 1 |
35 |
752 |
29 |
11 |
14 |
4 |
20 |
2 |
58 |
75 |
| 2 |
49 |
2 |
696 |
25 |
101 |
37 |
65 |
16 |
8 |
1 |
| 3 |
23 |
5 |
133 |
427 |
91 |
159 |
122 |
26 |
8 |
6 |
| 4 |
16 |
0 |
97 |
21 |
759 |
23 |
54 |
22 |
8 |
0 |
| 5 |
9 |
4 |
98 |
109 |
63 |
627 |
49 |
33 |
5 |
3 |
| 6 |
3 |
2 |
44 |
20 |
30 |
15 |
881 |
0 |
5 |
0 |
| 7 |
13 |
1 |
63 |
19 |
90 |
73 |
9 |
725 |
6 |
1 |
| 8 |
59 |
16 |
32 |
7 |
15 |
7 |
11 |
2 |
837 |
14 |
| 9 |
63 |
64 |
27 |
11 |
7 |
13 |
17 |
19 |
31 |
748 |